文書の一覧
全部で66本あります(SG22のWG14からのものは除きます)。
- N4903 PL22.16/WG21 agenda: 7 February 2022, Virtual Meeting
- N4904 WG21 admin telecon meetings: 2022 summer and autumn (revision 1)
- N4905 WG21 2022-01 Admin telecon minutes
- N4906 Transactional Memory TS2
- N4907 WG21 2022-02 Virtual Meeting Minutes of Meeting
- P0009R15 MDSPAN
- P0323R12 std::expected
- P0447R19 Introduction of std::hive to the standard library
- P0561R6 An RAII Interface for Deferred Reclamation
- P0792R7 function_ref: a non-owning reference to a Callable
- P0792R8 function_ref: a non-owning reference to a Callable
- P0957R5 Proxy: A Polymorphic Programming Library
- P1018R15 C++ Language Evolution status - pandemic edition – 2022/01-2022/02
- P1202R4 Asymmetric Fences
- P1223R3 find_last
- P1478R7 Byte-wise atomic memcpy
- P1664R7 reconstructible_range - a concept for putting ranges back together
- P1774R6 Portable assumptions
- P1839R3 Accessing Object Representations
- P1841R3 Wording for Individually Specializable Numeric Traits
- P1885R10 Naming Text Encodings to Demystify Them
- P2093R13 Formatted output
- P2214R2 A Plan for C++23 Ranges
- P2416R2 Presentation of requirements in the standard library
- P2438R2 std::string::substr() &&
- P2441R2 views::join_with
- P2446R2 views::as_rvalue
- P2448R2 Relaxing some constexpr restrictions
- P2452R0 2021 October Library Evolution and Concurrency Polls on Networking and Executors
- P2453R0 2021 October Library Evolution Poll Outcomes
- P2458R1 2022 January Library Evolution Polls
- P2459R0 2022 January Library Evolution Poll Outcomes
- P2465R2 Standard Library Modules std and std.compat
- P2467R1 Support exclusive mode for fstreams
- P2472R1 make function_ref more functional
- P2495R0 Interfacing stringstreams with string_view
- P2502R1 std::generator: Synchronous Coroutine Generator for Ranges
- P2505R1 Monadic Functions for std::expected
- P2506R0 std::lazy: a coroutine for deferred execution
- P2513R1 char8_t Compatibility and Portability Fix
- P2521R1 Contract support -- Working Paper
- P2528R0 C/C++ Identifier Security using Unicode Standard Annex 39
- P2529R0 generator should have T&& reference_type
- P2530R0 Why Hazard Pointers should be in C++26
- P2531R0 C++ Standard Library Issues to be moved in Virtual Plenary, Feb. 2022
- P2532R0 Removing exception_ptr from the Receiver Concepts
- P2533R0 Core Language Working Group "ready" Issues for the February, 2022 meeting
- P2534R0 Slides: function_ref in the wild (P0792R7 presentation)
- P2535R0 Message fences
- P2536R0 Distributing C++ Module Libraries with dependencies json files.
- P2537R0 Relax va_start Requirements to Match C
- P2538R0 ADL-proof std::projected
- P2540R0 Empty Product for certain Views
- P2542R0 views::concat
- P2544R0 C++ exceptions are becoming more and more problematic
- P2545R0 Why RCU Should be in C++26
- P2546R0 Debugging Support
- P2547R0 Language support for customisable functions
- P2549R0 std::unexpected should have error() as member accessor
- P2550R0 ranges::copy should say output_iterator somewhere
- P2551R0 Clarify intent of P1841 numeric traits
- P2552R0 On the ignorability of standard attributes
- P2553R0 Make mdspan size_type controllable
- P2554R0 C-Array Interoperability of MDSpan
- P2555R0 Naming improvements for std::execution
- P2557R0 WG21 2022-02 Virtual Meeting Record of Discussion
- おわり
N4903 PL22.16/WG21 agenda: 7 February 2022, Virtual Meeting
2022年2月7日(北米時間)に行われたWG21全体会議のアジェンダ。
C++23のための4回目の全体会議です。
N4904 WG21 admin telecon meetings: 2022 summer and autumn (revision 1)
次回以降のWG21の各作業部会の管理者ミーティングの予定表。
次は2022年7月11日(北米時間)に予定されています。
N4905 WG21 2022-01 Admin telecon minutes
WG21の各作業部会の管理者ミーティングの議事録。
前回から今回の会議の間のアクティビティの報告がされています。
N4906 Transactional Memory TS2
P2066の最小トランザクショナルメモリのTechnical Specifications。
P2066R2については以前の記事を参照
- P2066R2 Suggested draft TS for C++ Extensions for Minimal Transactional Memory - [C++]WG21月次提案文書を眺める(2020年05月)
- P2066R3 Suggested draft TS for C++ Extensions for Minimal Transactional Memory - [C++]WG21月次提案文書を眺める(2020年09月)
- P2066R4 Suggested draft TS for C++ Extensions for Minimal Transactional Memory - [C++]WG21月次提案文書を眺める(2020年10月)
- P2066R5 Suggested draft TS for C++ Extensions for Minimal Transactional Memory - [C++]WG21月次提案文書を眺める(2021年02月)
- P2066R6 Suggested draft TS for C++ Extensions for Minimal Transactional Memory - [C++]WG21月次提案文書を眺める(2021年03月)
- P2066R7 Suggested draft TS for C++ Extensions for Minimal Transactional Memory - [C++]WG21月次提案文書を眺める(2021年05月)
- P2066R8 Suggested draft TS for C++ Extensions for Minimal Transactional Memory - [C++]WG21月次提案文書を眺める(2021年07月)
- P2066R9 Suggested draft TS for C++ Extensions for Minimal Transactional Memory - [C++]WG21月次提案文書を眺める(2021年09月)
- P2066R10 Suggested draft TS for C++ Extensions for Minimal Transactional Memory - [C++]WG21月次提案文書を眺める(2021年10月)
N4907 WG21 2022-02 Virtual Meeting Minutes of Meeting
2022年2月7日(北米時間)に行われた、WG21全体会議の議事録。
CWG/LWG/LEWGの投票の様子などが記載されています。
P0009R15 MDSPAN
多次元配列に対するstd::spanである、mdspanの提案。
以前の記事を参照
- P0009R12 MDSPAN - WG21月次提案文書を眺める(2021年05月)
- P0009R13 MDSPAN - WG21月次提案文書を眺める(2021年10月)
- P0009R14 MDSPAN - WG21月次提案文書を眺める(2021年11月)
このリビジョンでの変更は
mdspan::rank[_dynamic]の型がsize_tになった- strideを考慮するように
layout_strideの比較演算子を修正 layout_strideのrequired_span_sizeへのマッピングを修正- レイアウトマッピングクラスの
operator()の効果でindex_sequenceandのみを使用するようにした(stride(P())によるエラーを回避) extents<>を処理するために、単項畳み込み式を二項へ置き換えたmdspanのstd::arrayを受け取るコンストラクタがExtentのstd::arrayコンストラクタを呼び出すように修正- 提案する文言の調整・改善
などです。
この提案は現在、LWGにおいてレビュー作業中です。
P0323R12 std::expected
エラーハンドリングを戻り値で行うための型、std::expected<T, E>の提案。
以前の記事を参照
このリビジョンでの変更はよくわかりません。
この提案は2022年2月の全体会議で承認され、C++23入りが決定しています。
P0447R19 Introduction of std::hive to the standard library
要素が削除されない限りそのメモリ位置が安定なコンテナであるstd::hive(旧名std::colony)の提案。
以前の記事を参照
- P0447R11 Introduction of std::colony to the standard library - [C++]WG21月次提案文書を眺める(2020年12月)
- P0447R12 Introduction of std::colony to the standard library - [C++]WG21月次提案文書を眺める(2021年01月)
- P0447R13 Introduction of std::colony to the standard library - [C++]WG21月次提案文書を眺める(2021年04月)
- P0447R14 Introduction of std::colony to the standard library - [C++]WG21月次提案文書を眺める(2021年05月)
- P0447R15 Introduction of std::hive to the standard library - [C++]WG21月次提案文書を眺める(2021年06月)
- P0447R16 Introduction of std::hive to the standard library - [C++]WG21月次提案文書を眺める(2021年09月)
- P0447R17 Introduction of std::hive to the standard library - [C++]WG21月次提案文書を眺める(2021年11月)
- P0447R18 Introduction of std::hive to the standard library - [C++]WG21月次提案文書を眺める(2022年01月)
このリビジョンでの変更は、Introduction節の修正、sort()によってイテレータが無効化されることを追記、記載されていたQ&Aの削除、constexprについての説明の移動、などです。
P0561R6 An RAII Interface for Deferred Reclamation
deferred reclamationを実現するためのより高レベルAPIを標準ライブラリに追加する提案。
以前の記事を参照
このリビジョンでの変更は、<snapshot>を<experimental/snapshot>に変更した事、機能テストマクロを追加した事です。
この提案はConcurrency TS v2に向けて作業されているようです。
P0792R7 function_ref: a non-owning reference to a Callable
↓
P0792R8 function_ref: a non-owning reference to a Callable
Callableを所有しないstd::functionであるstd::function_refの提案。
以前の記事を参照
R7での変更は、関数と関数ポインタを同じようにハンドルすることを明確にしたことです。
R8での変更は
- メンバポインタのサポートをやめた
- コピー代入を維持しつつ、関数ポインタ以外のCallableの代入を削除
- 提案する文言をよりよい用語を用いて改善
などです。
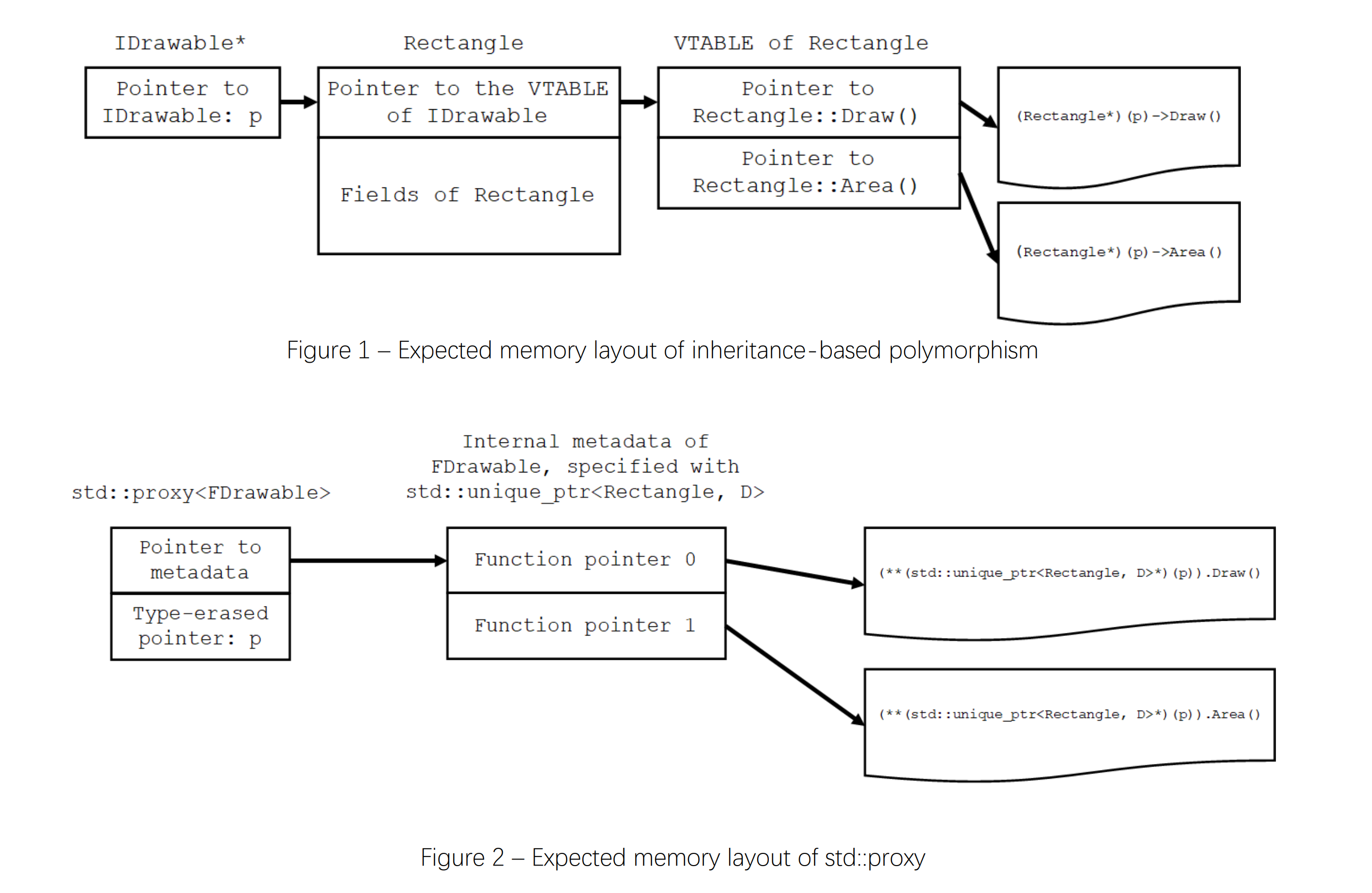
P0957R5 Proxy: A Polymorphic Programming Library
静的な多態的プログラミングのためのユーティリティ、"Proxy"の提案。
多態性(Polymorphism)はプログラムコンポーネントを分離し、拡張性を向上させるために不可欠です。ただし、そのコストとして実行時のパフォーマンスを低下させます。
現在の標準には仮想関数による継承ベースの方法とライブラリのポリモルフィックラッパ型(std::function, std::any, std::pmr::polymorphic_allocatorなど)の2つの多態性サポートがありますが、ライブラリのポリモルフィックラッパ型は特定の用途のために拡張性が制限されており、多態的なプログラミングには通常継承ベースの方法の使用が避けられません。
この提案の"Proxy"は自由に拡張可能で効率的な多態性を実現するためのユーティリティであり、多くの部分を静的に解決することによって従来のC++におけるOOPとFPの使いやすさとパフォーマンスの制限を取り払うことを目指すものです。
図形クラスによるサンプル。
// Drawableのインターフェースクラス class IDrawable { public: virtual void Draw() const = 0; // 図形の描画 virtual double Area() const = 0; // 面積の取得 }; // 長方形クラス class Rectangle : public IDrawable { public: void Draw() const override; void SetWidth(double width); void SetHeight(double height); void SetTransparency(double); double Area() const override; }; // 円クラス class Circle : public IDrawable { public: void Draw() const override; void SetRadius(double radius); void SetTransparency(double transparency); double Area() const override; }; // 点クラス class Point : public IDrawable { public: void Draw() const override; double Area() const override { return 0; } }; // Drawableな対象を操作する void DoSomethingWithDrawable(IDrawable* p) { printf("The drawable is: "); p->Draw(); // .Draw()の呼び出し printf(", area = %f\n", p->Area()); // .Area()の呼び出し } // 文字列による指定からDrawableを構築する auto MakeDrawableFromCommand(const std::string&) -> std::unique_ptr<IDrawable>; int main() { std::unique_ptr<IDrawable> p; p = MakeDrawableFromCommand("Rectangle 2 3"); DoSomethingWithDrawable(p.get()); p = MakeDrawableFromCommand("Circle 1"); DoSomethingWithDrawable(p.get()); p = MakeDrawableFromCommand("Point"); DoSomethingWithDrawable(p.get()); }
このよくある継承ベースのポリモルフィズムのサンプルは、Proxyによって次のように書くことができます。
#include <proxy> // Drawableに要求される2つの操作の定義(図形の描画と面積の取得) struct Draw : std::dispatch< void(), [](const auto& self) { self.Draw(); }> {}; struct Area : std::dispatch< double(), [](const auto& self) { return self.Area(); }> {}; // DrawableのFacadeクラスの定義 struct FDrawable : std::facade<Draw, Area> {}; // 長方形クラス class Rectangle { public: void Draw() const { printf("{Rectangle: width = %f, height = %f}", width_, height_); } void SetWidth(double width) { width_ = width; } void SetHeight(double height) { height_ = height; } void SetTransparency(double); double Area() const { return width_ * height_; } private: double width_; double height_; }; // 円クラス class Circle { public: void Draw() const { printf("{Circle: radius = %f}", radius_); } void SetRadius(double radius) { radius_ = radius; } void SetTransparency(double); double Area() const { return std::numbers::pi * radius_ * radius_; } private: double radius_; }; // 点クラス class Point { public: Point() noexcept { puts("A point was created"); } ~Point() { puts("A point was destroyed"); } void Draw() const { printf("{Point}"); } constexpr double Area() const { return 0; } }; // Drawableな対象をstd::proxy経由で呼び出す void DoSomethingWithDrawable(std::proxy<FDrawable> p) { printf("The drawable is: "); p.invoke<Draw>(); // .Draw()の呼び出し printf(", area = %f\n", p.invoke<Area>()); // .Area()の呼び出し } // 文字列による指定からDrawableを構築する auto MakeDrawableFromCommand(const std::string&) -> std::proxy<FDrawable>; int main() { std::proxy<FDrawable> p; p = MakeDrawableFromCommand("Rectangle 2 3"); DoSomethingWithDrawable(std::move(p)); p = MakeDrawableFromCommand("Circle 1"); DoSomethingWithDrawable(std::move(p)); p = MakeDrawableFromCommand("Point"); DoSomethingWithDrawable(std::move(p)); }
この提案のProxyの中核は、std::dispatch, std::facade, std::proxyの3つのクラスです。
std::dispatchは関数型と関数呼び出し可能なもの(Callable)をテンプレートパラメータに受け取る空のクラスで、第二引数のCallableにはディスパッチ処理を記述します(ここでは、メンバ関数Draw(), Area()の呼び出し)。std::facadeはstd::dispatchによって定義されたディスパッチ要件の列を受け取る空のクラスです。この2つのクラス定義ではこれ以外のことをする必要はありません(多分usingでもいいはず)。
std::proxyはstd::dispatch, std::facadeによって定義した要件にアダプトした任意の型のオブジェクトを保持する型消去ラッパーです。テンプレートパラメータにディスパッチ要件を指定したstd::facade<...>を受け取ります。構築及び代入では柔軟な変換によって任意のオブジェクトを受け取り(std::anyの振る舞いに近い)、.invoke<D>()メンバ関数によって保持するオブジェクトを使用してstd::dispatch(D)に指定した方法によって関数の呼び出しを行います。.invoke<D>()は追加の引数を受け取って呼び出される関数まで転送することもできます。
std::proxyはポリモルフィックなオブジェクトを外部から受け取って内部に保持するもので、そのオブジェクトの構築は任意に行うことができます。それによって、それらポリモルフィックなオブジェクトのライフタイム管理の戦略をも柔軟にカスタマイズすることができます。例えば、上記例のMakeDrawableFromCommand()は次のように実装されます。
std::proxy<FDrawable> MakeDrawableFromCommand(const std::string& s) { // 引数をパースする(ParseCommandは別に定義されているとする) std::vector<std::string> parsed = ParseCommand(s); if (!parsed.empty()) { if (parsed[0u] == "Rectangle") { if (parsed.size() == 3u) { // polymorphic_allocatorとプールによるアロケートとライフタイムのカスタマイズ static std::pmr::unsynchronized_pool_resource rectangle_memory_pool; std::pmr::polymorphic_allocator<> alloc{&rectangle_memory_pool}; auto deleter = [alloc](Rectangle* ptr) mutable { alloc.delete_object<Rectangle>(ptr); }; Rectangle* instance = alloc.new_object<Rectangle>(); std::unique_ptr<Rectangle, decltype(deleter)> p{instance, deleter}; p->SetWidth(std::stod(parsed[1u])); p->SetHeight(std::stod(parsed[2u])); return p; // unique_ptr -> proxyへ暗黙変換(unique_ptrを内部で保持することで間接所有する) } } else if (parsed[0u] == "Circle") { if (parsed.size() == 2u) { // ローカル(スタック)変数 Circle circle; circle.SetRadius(std::stod(parsed[1u])); return std::make_proxy<FDrawable>(circle); // コピーして直接保持、SBO(Small Buffer Optimization)が適用される } } else if (parsed[0u] == "Point") { if (parsed.size() == 1u) { // グローバルシングルトンオブジェクト static Point instance; return &instance; // ポインタを保持 } } } throw std::runtime_error{"Invalid command"}; }
このような柔軟で安全かつ効率的(SBOによる)なライフタイム管理は、従来の継承ベースの手法では困難だったものです。std::proxyはここにさらにインターフェースのディスパッチサポートが追加されていることで、継承ベースの手法と同等の多態性サポートを行うとともに、安全性と効率性や使いやすさを向上させています。
継承ベースとstd::proxyのメモリレイアウトの比較図
P1018R15 C++ Language Evolution status - pandemic edition – 2022/01-2022/02
2022年1月から2022年2月の間のEWGの活動についてのレポート。
2022年1月に行われた次の提案についてのEWGの電子投票の結果が記載されています。
- P2280R3 Using unknown references in constant expressions
- P2468R1 The Equality Operator You Are Looking For
- P2327R1 De-deprecating volatile compound operations
- P2266R2 Simpler implicit move
- P1467R8 Extended floating-point types and standard names
- P2350R2 constexpr class
- 否決
- P1169R3 static operator()
- P1774R5 Portable assumptions
- P1494R2 Partial program correctness
- 否決
- P2448R0 Relaxing some constexpr restrictions
- P2437R0 Support for #warning
- P2324R1 Labels at the end of compound statements (C compatibility)
- P2071R1 Named universal character escapes
- P2295R5 Support for UTF-8 as a portable source file encoding
- P2290R2 Delimited escape sequences
- P2362R3 Remove non-encodable wide character literals and multicharacter wide character literals
- P2348R2 Whitespaces Wording Revamp
否決されていない提案はC++23入りを目指してCWGでレビューされますが、否決されたものはC++23には間に合わず、C++26以降を目指して作業していくことになります。
P1202R4 Asymmetric Fences
非対称なフェンスの提案。
以前の記事を参照
このリビジョンでの変更は、どうやら文書内容の整理(承認されている部分について省略)のようです。
この提案は現在Concurrency TS v2を目指してLEWGで作業されています。
P1223R3 find_last
指定された値をシーケンスの後ろから探索するfind_lastアルゴリズムの提案。
これはstd::findの逆を行うものです。現在それを書こうとすると、単純なループかstd::reverse_iteratorを使用するかのどちらかになるでしょう。
template<std::bidirectional_iterator I, typename T> requires std::indirect_binary_predicate<ranges::equal_to, I, const T*> auto find_last1(I first, I it, const T& x) { // ループを使った探索 while (it-- != first) { if (*it == x) { // Use it here... } } return it; } template<std::bidirectional_iterator I, typename T> requires std::indirect_binary_predicate<ranges::equal_to, I, const T*> auto find_last1(I first, I it, const T& x) { // reverse_iteratorとfindを使った探索 auto rfirst = std::make_reverse_iterator(it); auto rlast = std::make_reverse_iterator(first); auto it2 = std::find(rfirst, rlast, x); // Use it here... return it2; }
しかし、やりたい事の単純さと比較してこれらの記法はどちらも煩わしさがあります。理想的には次のようにかけるといいはずです。
auto it2 = std::find_last(first, it, x);
この提案はこのfind_lastをはじめとした各種ファミリー(find_last_if, find_last_if_not)の標準ライブラリへの追加を目指すものです。
namespace std::ranges { // イテレータペアを受け取る template<forward_iterator I, sentinel<I> S, class T, class Proj = identity> requires indirect_binary_predicate<ranges::equal_to, projected<I, Proj>, const T*> constexpr I find_last(I first, S last, const T& value, Proj proj = {}); // rangeを受け取る template<forward_range R, class T, class Proj = identity> requires indirect_binary_predicate<ranges::equal_to, projected<iterator_t<R>, Proj>, const T*> constexpr borrowed_iterator_t<R> find_last(R&& r, const T& value, Proj proj = {}); }
現在の提案ではこれらの関数は全て対象の要素を発見した位置のイテレータを返すようになっていますが、find_last()はその実行に際してまず範囲の終端を求める必要があります(rangeを受け取る方の場合)。したがって(その他のアルゴリズム、特にranges版がそうであるように)、その有用な情報をユーザーに返す必要があります。そこで、subrangeを返すように変更することが議論されています。
namespace std::ranges { // イテレータペアを受け取る template<forward_iterator I, sentinel<I> S, class T, class Proj = identity> requires indirect_binary_predicate<ranges::equal_to, projected<I, Proj>, const T*> constexpr subrange<I> find_last(I first, S last, const T& value, Proj proj = {}); // rangeを受け取る template<forward_range R, class T, class Proj = identity> requires indirect_binary_predicate<ranges::equal_to, projected<iterator_t<R>, Proj>, const T*> constexpr borrowed_subrange_t<R> find_last(R&& r, const T& value, Proj proj = {}); }
この場合、指定されたものを見つけたら[it, last)のsubrangeを、何も見つからなかったら[last, last)のsubrangeを返します。
この設計の問題点は、この戻り値がfindなどと一貫していないこと、多くの場合ユーザーは終端情報(last)を使用しないので捨てるべき余分な情報が増えるだけと思われることです。しかし、筆者の方はこれを改善であると認識していて、その方向で議論が進んでいるようです。
P1478R7 Byte-wise atomic memcpy
アトミックにメモリのコピーを行うためのstd::atomic_load_per_byte_memcpy()/std::atomic_store_per_byte_memcpy()の提案。
以前の記事を参照
- P1478R4 Byte-wise atomic memcpy - [C++]WG21月次提案文書を眺める(2020年7月)
- P1478R5 Byte-wise atomic memcpy - [C++]WG21月次提案文書を眺める(2020年11月)
- P1478R6 Byte-wise atomic memcpy - [C++]WG21月次提案文書を眺める(2020年12月)
このリビジョンでの変更はP2396R0の変更を適用したことです。
この提案は、Concurrency TS v2に向けてLWGに転送済です。
P1664R7 reconstructible_range - a concept for putting ranges back together
viewによって別のrangeに変換されてしまった範囲を、元のrange(と同じ型)に戻す操作、std::ranges::reconstructと関連するコンセプトの提案。
以前の記事を参照
- P1664R3 reconstructible_range - a concept for putting ranges back together - [C++]WG21月次提案文書を眺める(2021年04月)
- P1664R4 reconstructible_range - a concept for putting ranges back together - [C++]WG21月次提案文書を眺める(2021年06月)
- P1664R5 reconstructible_range - a concept for putting ranges back together - [C++]WG21月次提案文書を眺める(2021年08月)
- P1664R6 reconstructible_range - a concept for putting ranges back together - [C++]WG21月次提案文書を眺める(2022年01月)
このリビジョンでの変更は、設計に関する説明の改善、提案する文言の改善などです。
この提案は、P2516R0(std::string_viewのrangeコンストラクタ削除)が採択された場合にviews::splitの内側rangeの使用を改善するのに役立つ可能性があります。
std::string_view s = "12.22.32.41"; auto ints = s | views::split('.') | views::transform([](auto v) { int i = 0; // vはstring_viewオブジェクト if (v.ends_with('2')) { std::from_chars(v.data(), v.size(), &i); } return i; });
P1774R6 Portable assumptions
コンパイラにコードの内容についての仮定を伝えて最適化を促進するための[[assume(expr)]]の提案。
以前の記事を参照
- P1774R4 Portable assumptions - [C++]WG21月次提案文書を眺める(2021年10月)
- P1774R5 Portable assumptions - [C++]WG21月次提案文書を眺める(2021年12月)
このリビジョンでの変更は、SG22での投票の結果を追記したことなどです。
SG22の投票では、この提案をCに対しても提案することを推奨することに合意が取れています。
この提案は、EWGからCWGに送られ、レビュー待ちをしています。
P1839R3 Accessing Object Representations
reinterpret_cast<char*>によるオブジェクト表現へのアクセスを未定義動作とならないようにする提案。
この提案の解決する問題は、キャストとポインタ演算という2つの操作によって発生します。
int a = 420; char b = *reinterpret_cast<char*>(&a); // UB
このreinterpret_cast<char*>(&a)はstatic_cast<char*>(static_cast<void*>(&a))と同じ効果となり([expr.reinterpret.cast]/7)、そのようなstatic_castの指定するところ([expr.static.cast]/13)によってそのポインタ値(アドレス値)は変化しません。そのため、このキャスト後のポインタは元のオブジェクトを指しています。
この時、bの初期化式にlvalue-to-rvalue conversionを適用するとその結果はintの値(420)となり、それはcharで表現できる値ではないので未定義動作となります([expr.pre]/4)。もしこの時、charにその表現が存在する場合でも、[basic.types]/4の規定するところのオブジェクト表現は配列ではなくunsgined charのオブジェクトの列となってしまい、現在のオブジェクトモデルの下ではポインタ演算に適していません。
この問題はC++17でP0137R1が採択されたことによって発生した問題のようです。この提案では、ポインタが単なるメモリのアドレス表現ではなくオブジェクトを指すものという形でポインタの動作方法の変更を行なっており、そこでは、ポインタを介してオブジェクトのオブジェクト表現へアクセスする方法についての考慮がおろそかになっていたようです。
この提案では、次のような変更によってこの問題の解決を図ります。
- ある型のオブジェクト表現が連続したストレージを占有している場合、そのオブジェクト表現は
unsigned charの配列とみなされるようにする unsigned char, char, std::byteのオブジェクトとその配列は、それ自身のオブジェクト表現とする(定義の再帰防止)unsigned char, char, std::byte以外の型のオブジェクト表現の各要素の値は未規定であり、unsigned char, char, std::byteのオブジェクト表現の要素の値はそれらのオブジェクト表現の値とする- オブジェクト表現へのポインタを、
unsigned char, char, std::byteへの(ポインタ)キャストによって取得できるようにする - オブジェクト表現へのポインタは、キャストを用いて元のオブジェクトへのポインタに戻せるようにする
std::launderが、オブジェクト表現の要素ではないオブジェクトへのポインタを返すことを優先するように規定- 複数のオブジェクトが同じストレージを占めている時、そのような領域へのポインタに対する
std::launderが返すポインタはプログラム定義のオブジェクトを指すものとする - おそらく、その時生存期間内にあるオブジェクトへのポインタを返すことを意図していると思われる、たぶん・・・
- 複数のオブジェクトが同じストレージを占めている時、そのような領域へのポインタに対する
- 式の型が
unsigned char*, char*, std::byte*の場合、オブジェクト表現の要素に対してポインタ演算できるようにする
これらの変更は新しい機能を導入するものではなく、既存の慣行を標準化するものです。
| 現在 | この提案 |
|---|---|
using T = unsigned char*; int a = 0; T b = reinterpret_cast<T>(&a); // ポインタ値は変更されない // bはaを指す T c = ++b; // UB、式の型は要素型と異なる |
using T = unsigned char*; int a = 0; T b = reinterpret_cast<T>(&a); // bはa(int)のオブジェクト表現の // 最初の要素(unsigned char)を指す T c = ++b; // cはa(int)のオブジェクト表現の2番目の要素を指す ++(*c); // OK |
| 現在 | この提案 |
|---|---|
using T = unsigned char*; int a[5]{}; T b = reinterpret_cast<T>(&a); // ポインタ値は変更されない // bはaを指す for (int i = 0; i < sizeof(int) * 5; ++i){ b[i] = 0; // UB、式の型は要素型と異なる } |
using T = unsigned char*; int a[5]{}; T b = reinterpret_cast<T>(&a); // bはa(int[5])のオブジェクト表現の // 最初の要素(unsigned char)を指す for (int i = 0; i < sizeof(int) * 5; ++i){ b[i] = 0; // OK } |
P1841R3 Wording for Individually Specializable Numeric Traits
std::numeric_limitsに代わる新たな数値特性(numeric traits)取得方法を導入する提案。
以前の記事を参照
- P1841R1 : Wording for Individually Specializable Numeric Traits - WG21月次提案文書を眺める(2020年05月)
- P1841R2 : Wording for Individually Specializable Numeric Traits - WG21月次提案文書を眺める(2022年01月)
このリビジョンでの変更は、CWG/LWGのレビュー結果の反映などです。
P1885R10 Naming Text Encodings to Demystify Them
システムの文字エンコーディングを取得し、識別や出力が可能なライブラリを追加する提案。
以前の記事を参照
- P1885R3 Naming Text Encodings to Demystify Them - [C++]WG21月次提案文書を眺める(2020年9月)
- P1885R4 Naming Text Encodings to Demystify Them - [C++]WG21月次提案文書を眺める(2020年11月)
- P1885R5 Naming Text Encodings to Demystify Them - [C++]WG21月次提案文書を眺める(2021年02月)
- P1885R6 Naming Text Encodings to Demystify Them - [C++]WG21月次提案文書を眺める(2021年08月)
- P1885R7 Naming Text Encodings to Demystify Them - [C++]WG21月次提案文書を眺める(2021年08月)
- P1885R8 Naming Text Encodings to Demystify Them - [C++]WG21月次提案文書を眺める(2021年10月)
- P1885R9 Naming Text Encodings to Demystify Them - [C++]WG21月次提案文書を眺める(2022年01月)
このリビジョンでの変更はP2498R1で提起された懸念とSG16の提案への対応を行ったことです。
P2498ではエンコーディングとしてIANAレジストリのものを参照しそれにほぼ固定されていることを問題としていました。SG16およびLEWGでの議論の結果、
などの理由によってP2498の提案を採用しないことで合意されました。
- P2498R0 Forward compatibility of text_encoding with additional encoding registries - [C++]WG21月次提案文書を眺める(2021年12月)
- P2498 Forward compatibility of text_encoding with additional encoding registries - Github
- P1885 進行状況
P2093R13 Formatted output
std::formatによるフォーマットを使用しながら出力できる新I/Oライブラリstd::printの提案。
以前の記事を参照
- P2093R0 Formatted output - [C++]WG21月次提案文書を眺める(2020年6月)
- P2093R1 Formatted output - [C++]WG21月次提案文書を眺める(2020年7月)
- P2093R2 Formatted output - [C++]WG21月次提案文書を眺める(2020年10月)
- P2093R3 Formatted output - [C++]WG21月次提案文書を眺める(2021年1月)
- P2093R4 Formatted output - [C++]WG21月次提案文書を眺める(2021年2月)
- P2093R5 Formatted output - [C++]WG21月次提案文書を眺める(2021年3月)
- P2093R6 Formatted output - [C++]WG21月次提案文書を眺める(2021年4月)
- P2093R7 Formatted output - [C++]WG21月次提案文書を眺める(2021年7月)
- P2093R8 Formatted output - [C++]WG21月次提案文書を眺める(2021年8月)
- P2093R9 Formatted output - [C++]WG21月次提案文書を眺める(2021年9月)
- P2093R10 Formatted output - [C++]WG21月次提案文書を眺める(2021年11月)
- P2093R12 Formatted output - [C++]WG21月次提案文書を眺める(2022年01月)
このリビジョンでの変更は、提案する文言の修正や改善です。
P2214R2 A Plan for C++23 Ranges
C++23に向けてのrangeライブラリの拡張プランについてまとめた文書。
前回の記事を参照
- P2214R0 A Plan for C++23 Ranges - [C++]WG21月次提案文書を眺める(2020年10月)
- P2214R1 A Plan for C++23 Ranges - [C++]WG21月次提案文書を眺める(2021年09月)
このリビジョンでは、R1以降の作業の進行を反映しいくつかの提案へのリンクを追加した事です。
C++23に向けて、次のものはすでに採択済です
ranges::toviews::adjacentviews::adjacent_transformviews::chunkviews::chunk_byviews::join_withviews::slideviews::zipviews::zip_transformranges::iotaranges::shift_leftranges::shift_right- P2321R2(
views::zipのためのpair/tupleの調整)
さらに、次のものはC++23に向けて、LWGのレビュー中です
views::as_constviews::as_rvalueviews::cartesian_producviews::strideviews::repeatranges::foldranges::contains- P2248R4(値を指定するRangeアルゴリズムで
{}を使えるようにする) - P2408R4(C++20イテレータをC++17アルゴリズムで使用可能にする)
- P2494R1(いくつかのRangeアダプタがムーブオンリーイテレータをサポートする)
おそらくこれ以上このリストに追加されることはなく、LWGでレビュー中のものもC++23に間に合わない可能性があります。
P2416R2 Presentation of requirements in the standard library
現在の規格書の、要件(requirement)の記述方法を変更する提案。
以前の記事を参照
- P2416R0 Presentation of requirements in the standard library - WG21月次提案文書を眺める(2021年07月)
- P2416R1 Presentation of requirements in the standard library - WG21月次提案文書を眺める(2021年12月)
このリビジョンでの変更は、LWGのフィードバックを反映したことです。
この提案は次の全体会議で投票にかけられることが決まっています。
P2438R2 std::string::substr() &&
右辺値std::stringからのsubstr()を効率化する提案。
以前の記事を参照
- P2438R0
std::string::substr() &&- WG21月次提案文書を眺める(2021年09月) - P2438R1
std::string::substr() &&- WG21月次提案文書を眺める(2021年12月)
このリビジョンでの変更は、フィードバックに基づく提案文言の変更、Annex Cセクションの追記、機能テストマクロの追加、などです。
この提案は次の全体会議で投票にかけられることが決まっています。
P2441R2 views::join_with
パターンによってrangeのrangeとなっているようなシーケンスを接合して平坦化するRangeアダプタ、views::join_withの提案。
以前の記事を参照
- P2441R0
views::join_with- WG21月次提案文書を眺める(2021年10月) - P2441R1
views::join_with- WG21月次提案文書を眺める(2021年11月)
このリビジョンでの変更は、提案する文言の修正です。
この提案は2022年2月の全体会議にて承認され、すでにC++23に向けたWDに適用されています。
P2446R2 views::as_rvalue
入力シーケンスの各要素をstd::moveするようなviewである、views::moveの提案
以前の記事を参照
このリビジョンでの変更は、名前をviews::as_rvalueへ変更したこと、提案する文言の修正です。
P2448R2 Relaxing some constexpr restrictions
constexpr関数がすべての引数について定数実行不可能となる場合でも、コンパイルエラーにしないようにする提案。
以前の記事を参照
- P2448R0 Relaxing some constexpr restrictions - WG21月次提案文書を眺める(2021年10月)
- P2448R1 Relaxing some constexpr restrictions - WG21月次提案文書を眺める(2022年01月)
このリビジョンでの変更は、提案する文言の修正のみです。
この提案はすでにCWGのレビューを終えて、次の全体会議で投票にかけられる予定です。
P2452R0 2021 October Library Evolution and Concurrency Polls on Networking and Executors
2021年10月ごろにLEWGとSG1のメンバーを対象に行われた、P2300とNetworking TSの方向性決定のための全体投票の周知文章。
この投票はすでに終了しており、なぜ今出てきたのかはわかりません・・・。
詳細はこちら
P2453R0 2021 October Library Evolution Poll Outcomes
2021年10月ごろにLEWGとSG1のメンバーを対象に行われた、P2300とNetworking TSの方向性決定のための全体投票(↑)の結果。
特に、投票の際に寄せられたコメントが記載されています。
P2458R1 2022 January Library Evolution Polls
2022年の1月に予定されている、LEWGでの全体投票の予定表。
以前の記事を参照
P2459R0 2022 January Library Evolution Poll Outcomes
2022年の1月に予定されている、LEWGでの全体投票の結果。
次の13の提案が投票にかけられ、P2300を除いてLWGへ転送されています。また、投票に当たって寄せられた賛否のコメントが記載されています。
- P2300R4 std::execution
- P2363R3 Extending Associative Containers With The Remaining Heterogeneous Overloads
- P0493R3 Atomic Maximum/Minimum
- P2286R6 Formatting Ranges
- P2165R3 Compatibility Between tuple, pair, And tuple-Like Objects
- P2494R1 Relaxing Range Adaptors To Allow For Move Only Types
- P2322R5 ranges::fold
- P2302R2 ranges::contains
- P1899R2 views::stride
- P2474R1 views::repeat
- P2508R1 Expose basic-format-string<charT, Args...>
- P2248R4 Enabling List-Initialization For Algorithms
- P2404R2 Move-Only Types For equality_comparable_with, totally_ordered_with, And three_way_comparable_with
P2465R2 Standard Library Modules std and std.compat
標準ライブラリモジュールについて最小のサポートをC++23に追加する提案
以前の記事を参照
このリビジョンでの変更は、提案する文言の改善とそれに伴う文言関連のQ&Aの削除などです。
この提案はすでにLWG/CWGでのレビューを終えており、次の全体会議で投票にかけられることが決まっています。
P2467R1 Support exclusive mode for fstreams
fstreamに排他モードでファイルオープンするフラグ、std::ios_base::noreplaceを追加する提案。
以前の記事を参照
このリビジョンでの変更は、提案する文言の修正・改善です。
この提案はC++23を目指してLWGでレビューされています。
P2472R1 make function_ref more functional
function_refに適応的に型消去させるためのヘルパ関数make_function_ref()を追加する提案。
以前の記事を参照
このリビジョンでの変更は、function_ref単体でのメンバポインタサポートを追求しないようにしたことから、std::nontypeを使用してfunction_refを初期化できるように拡張するようにへ変更した事です。
以前の提案は、std::make_function_refとfunction_refに1つコンストラクタを追加して、メンバポインタサポートを追加することを提案していましたが、この提案ではP2511の方向性を採用したうえで、function_refにそれを受け取るためのコンストラクタを追加することによって{}だけからfunction_refをメンバポインタのために初期化できるようにすることを提案しています。
struct cat { void walk() { } }; void leap(cat& c) { } void catwalk(cat& c) { c.walk(); } struct callback { cat* c; void (*f)(cat&); }; cat c; // メンバ関数の呼び出しを部分適用して引数なしにする例 void mem_func() { // callback構造体の利用 callback cb = {&c, [](cat& c){c.walk();}}; callback cb = {&c, catwalk}; // ラムダでラップ auto temp = [&c](){c.walk();}; // ダングリング防止のため中間オブジェクトが必要 function_ref<void()> fr = temp; some_function([&c](){c.walk();}); // some_functionの呼び出し中でだけ使われるなら直接渡せる // この提案 function_ref<void()> fr = {std::nontype<&cat::walk>, c}; } // フリー関数の呼び出しを部分適用して引数なしにする例 void free_func() { // callback構造体の利用 callback cb = {&c, [](cat& c){leap(c);}}; callback cb = {&c, leap}; // ラムダでラップ auto temp = [&c](){leap(c);}; function_ref<void()> fr = temp; some_function([&c](){leap(c);}); // この提案 function_ref<void()> fr = {nontype<leap>, c}; }
同じことをしているはずですが、function_ref使用時は場合によって2パターンの初期化方法に分かれています。このことはfunction_refを使用しづらくしており、安全性を損ねています。同じfunction_refを複数回使いたい場合、一度変数に受けてから使いまわすことはおそらくよく行われるでしょう。その場合、ダングリングを回避するには追加の(余分な)コードが必要となります。
この提案によるソリューションでは、関数に渡すときと変数を初期化する時で異なる構文を使用する必要はなく、より便利で安全です。また、コア言語のサポート(callback構造体のような)と一貫しています。
std::string_view sv = "hello world"s; // 次の行(`;`)以降ダングリング auto cs = "hello world"s; std::string_view sv = cs; // ダングリングではない function_ref<void()> fr = [&c](){c.walk();}; // 次の行(`;`)以降ダングリング function_ref<void()> fr = [&c](){leap(c);}; // 次の行(`;`)以降ダングリング function_ref<void()> fr = {nontype<&cat::walk>, c}; // ダングリングではない function_ref<void()> fr = {nontype<leap>, c}; // ダングリングではない
P2495R0 Interfacing stringstreams with string_view
std::stringstreamがstd::string_viewを受けとれるようにする提案。
std::stringstreamはstd::stringによる文字列を受け取ってその文字列によるストリームを構成するものです。C++20から.view()メンバ関数によってストリームの中身へのstd::string_viewを取得することができるようになっていますが、ストリームの最初の内容をコンストラクタで指定する際にはstd::stringしか渡せません。また、C++20から.str()メンバ関数によって後からストリームの中身を置き換えることができるようになっていますが、ここでもstd::stringしか渡せません。
std::stringstreamに文字列リテラルおよびstd::string_viewを渡そうとすると、std::stringの一時オブジェクトを作成してからそれをコンストラクタに渡さなければなりません。しかも、std::stringstreamはそこからさらに内部のstd::stringを構築するために、コピー/ムーブすることになります。
この提案はこの問題を解決するために、コンストラクタと.str()の両方がstd::string_viewを受けとれるようにするものです。
その際問題となるのが、文字列リテラルを渡した時にstd::stringを受け取るオーバーロードとstd::string_viewを受けとるオーバーロードで曖昧になることです。いくつかの解決が考えられますが、この提案では文字列リテラル用のオーバーロード(const char*を受け取る)も同時に追加することでそれを解消しています。
この提案による変更の例
const ios_base::openmode mode; const allocator<char> alloc; const string str; // mystringはstring_viewに暗黙変換可能だとする const mystring mstr; stringstream s0{""}; // ok stringstream s1{"", alloc}; // ng -> ok stringstream s2{"", mode, alloc}; // ng -> ok stringstream s3{""sv}; // ng -> ok stringstream s4{""sv, alloc}; // ng -> ok stringstream s5{""sv, mode, alloc}; // ng -> ok stringstream s6{""s}; // ok stringstream s7{""s, alloc}; // ok stringstream s8{""s, mode, alloc}; // ok stringstream s9{str}; // ok stringstream s10{str, alloc}; // ok stringstream s11{str, mode, alloc}; // ok stringstream s12{mstr}; // ng -> ok stringstream s13{mstr, alloc}; // ng -> ok stringstream s14{mstr, mode, alloc}; // ng -> ok stringstream s15; s15.str(""); // ok s15.str(""sv); // ng -> ok s15.str(""s); // ok s15.str(str); // ok s15.str(mstr); // ng -> ok
P2502R1 std::generator: Synchronous Coroutine Generator for Ranges
Rangeライブラリと連携可能なT型の要素列を生成するコルーチンジェネレータstd::generator<T>の提案。
以前の記事を参照
このリビジョンでの変更は、
generator::yielded(型)を説明専用ではなくし、publicにした- 機能テストマクロの追加
generator<T&&>のコルーチンでは、左辺値をyieldできるようにした(コピーしたxvalueが生成される)- これによって、
co_yield auto(lvalue)の代わりにco_yield lvalueと書けるようになった
- これによって、
- テンプレートパラメータの順番を再度並べ替え(
Allocatorを最後に)- 議論の結果、
Allocatorパラメータがテンプレートパラメータリストの最後に無いことは標準ライブラリの他の部分と一貫していないという合意が得られた
- 議論の結果、
elements_ofをシンプルな2要素構造体にしたelements_ofは再帰したrange(generator)をyield式で1要素づつ生成していくような変換を行うもの
- P2529R0の設計に従って、
generator<T>はgenerator<T&&>のように動作するようにした
この提案は、C++23に向けて現在LWGのレビュー中です。
P2505R1 Monadic Functions for std::expected
std::optionalのMonadic interfaceをstd::expectedにも導入する提案。
以前の記事を参照
このリビジョンでの変更は
transform_orの追加expected<void, E>にtransformを追加- サンプルコードの改善
or_elseの欠けていたオーバーロードを追加- エラー値に対する関数(
or_else, transform_or)での、戻り値型の変更に関する議論の追加
などです。
transform_orはエラー値に対してtransformするもので、参照実装ではmap_errorと呼ばれていたようです。要するに、expected<T, E> -> expected<T, E2>の変換を行うものです(or_elseとの違いは、エラー状態からの脱却ができないこと)。
この提案は、C++26に向けて議論されることになりました。
P2506R0 std::lazy: a coroutine for deferred execution
コルーチンによって非同期タスクを表現するためのユーティリティ、std::lazyの提案。
std::lazyはC#などの他の言語ではTaskという名前のクラスであることが多いものです。
これはコルーチンによって非同期処理の実行と待機、継続処理の実行を自動化するためのユーティリティ型で例えば次のように使用します。
// 何かのデータ型 struct record { int id; std::string name; std::string description; }; // recordをどこかから読み出す非同期処理 std::lazy<record> load_record(int id); // recordをどこかに保存する非同期処理 std::lazy<> save_record(record r); // recordの更新処理 std::lazy<void> modify_record() { // これらの処理はこの順番に実行される record r = co_await load_record(123); // 1. レコードの読み出し r.description = “Look, ma, no blocking!”; // 2. 1の実行後rが初期化されてから実行 co_await save_record(std::move(r)); // 3. レコード保存。2の実行後に実行される std::cout << "modify end.\n"; // 4. 3の実行が完了してから実行される }
このmodify_record()をコルーチンではなくfutureとコールバックによって同じ実行順となるように書くと次のようになります
// modify_record()の非コルーチン版 void modify_record_async() { auto f1 = load_record_async(123, [](record r) { r.description = “Look, ma, no blocking!”; auto f2 = save_record_async(std::move(r), [](){ std::cout << "modify end.\n" }); f2.wait(); }); f1.wait(); // f1, f2はstd::future相当のものとする }
このコールバックコードで手動でやっているようなことを、co_await構文を使用することで隠蔽・自動化するためのコルーチン制御を担っているのがstd::lazy型です。
std::lazyは元々は別の著者によって別の提案(P1056R1)で議論されていましたが、そちらは長期間止まっていたため、この提案が引き取った形です。そのため、ほとんどの部分の設計は変更されていません。筆者の方は、std::lazyを含めた基本的なコルーチンユーティリティがC++20に含まれていないのは間違いであり、C++23に含まれないのはもっと間違いだ、と述べていますが、この提案は今の所C++23に向けたものではありません(C++23の設計フェーズはすでに終了しているため)。
std::lazyは次のようなとてもシンプルで小さいクラスです
template<class T, class Allocator = void> class [[nodiscard]] lazy { public: lazy(lazy&& that) noexcept; ~lazy(); unspecified operator co_await(); T sync_await(); };
おそらくこれらのメンバ関数を明示的に呼び出すことはないでしょう。テンプレートパラメータTはコルーチンから返す値の型(move_constructibleであること)を指定し、何も返さない場合はvoidを指定することができます。2つ目のAllocatorは、コルーチンステートのために必要となるヒープアロケーションをカスタマイズするために指定します。
std::lazyはコルーチンとその呼び出し元の境界で暗黙的に使用されるものであって、上記サンプルコードにあるように、呼び出し側のco_awaitを除いてコルーチン側でもこの型に対して何か明示的な操作をする必要はありません。
C++26 Executorライブラリ(P2300)(予定)では、senderとコルーチンの相互変換などの仕組みが用意されており、std::lazyも別の提案によって後ほどP2300にアダプトする作業が行われる予定です。
なお、std::lazyがstd::taskという名前ではないのは、std::taskという名前をここで消費してしまうことを嫌ってのことのようです。
この部分の7割は以下の方のご指摘によって成り立っています。
P2513R1 char8_t Compatibility and Portability Fix
char8_tの非互換性を緩和する提案。
以前の記事を参照
このリビジョンでの変更は、タイポやタイトルの修正、配列を含む構造体の集成体初期化時のオーバーロード解決について説明の追加、文言の追加と集成などです。
この提案はSG16からEWGへ転送され、C++20へのDRとすることを目指してるようです。
P2521R1 Contract support -- Working Paper
以前の記事を参照
このリビジョンでの変更は、
- 関数の再宣言とオーバーライド時のコントラクト注釈を禁止
- コントラクトの条件式に仮想関数呼び出しが含まれている場合に起こることを明確化
- MVPに事後条件を含めることに関する投票結果の追記
- 翻訳単位毎にコントラクトチェックを有効にする/しないを混ぜてコンパイルするモード(mixed translation mode)の必要性について追記
- 現在のmixed translation modeは診断不用のill-formed
- 関数本体内に事前条件チェックを実装する必要がある事を示唆する記述の削除
- 仮想関数に関する特殊なケース(基底クラスがテンプレートパラメータによって指定されている時や複数の関数をオーバーライドするとき)についての説明の追加
- フリースタンディング環境でも使用可能とすることを目指していることを明確化
- コントラクト注釈内の
noexceptと似たルックアップを定義しないようにした
などです。
P2528R0 C/C++ Identifier Security using Unicode Standard Annex 39
セキュリティ上の問題のある文字を識別子に使用できなくする提案。
C++20では(DRなので以前のバージョンに対してもですが)P1949の採択によって不可視の文字や絵文字など、識別子(変数名やクラス名など)として使用すると問題のある一部の文字が識別子に使用できなくなりました。そこでは、ユニコード標準のAnnex 31というものを参照して識別子として使用可能な文字の集合を指定(制限)していました。
ユニコード標準にはAnnex 39としてユニコード文字のセキュリティ上の問題を解決するためのメカニズムを提供しています。P1949では、UAX31とUAX39の両方を実装するのは困難であるとして、UAX31による制限だけを提案していました。この提案は、筆者の方の経験(libu8identの実装)やRustやJavaなどでUAX31とUAX39が正しく実装されていることから、両方を実装するのは可能であるとしてそれを提案するものです。
UAX31に加えてUAX39を実装するとユニコード識別子に関する既知のセキュリティ上の問題のほとんどを修正することができます。残った問題は、文字列やコメント中のbidiオーバーライド(文字列中での双方向テキストの切り替えによる攻撃)ですが、これは識別子に対する制限だけでは解決できないため、この提案の範囲ではありません。それでも、最近GCCに実装されたように、トークナイザやプリプロセッサの警告によって発見することができます。
提案していることは以下の事です
- UAX39 #5.2 Mixed-Scripts Moderately Restrictive profileに部分的に準拠
- UAX31 #Table_7(限定文字)とUAX31 #Table_4(除外文字)をすべて使用しない
- UAX39 #Table_1のRecommended, Inclusion, Technicalに分類される文識別子タイプのみを許可
- NFCの正規化を要求する
- すべてのcomposable sequence(結合文字のこと?)を拒否する
- 混合スクリプト (SCX)を使用した不正な形式の混合マークシーケンス(Sk, Cf, Mn, Me)を拒否する
- オプション
#pragma unicode <LongScript>によって、ソースファイルごとに除外スクリプトを指定できるようにする
ここに出てくるスクリプトというのは、特定の文字の集合みたいな意味です(日本語では用字)というらしい)。
提案では、拒否する文字が識別子に現れた場合はコンパイルエラーとすることを提案しています(ただし、それは政治的な決断になるかもしれないと言っています)。
- UTS #39 UNICODE SECURITY MECHANISMS
- UTS #31 UNICODE IDENTIFIER AND PATTERN SYNTAX
- 用字 (Unicode) - Wikipedia)
- 双方向テキスト - Wikipedia
- P2528 進行状況
この部分の7割は以下の方のご指摘によって成り立っています。
P2529R0 generator should have T&& reference_type
提案中のstd::generator<T>のreference_typeはT&&であるべきとする提案。
std::generatorは現在P2502で議論されていますが、そこではstd::generator<T>についてそのreference_typeが何であるべきかが主な論点になっているようです。現在の提案ではconst T&が提案されています。この提案は、それはT&&とするように推奨しその根拠を述べるものです。
前提として、誰もが合意するであろうことは
std::generator<U>のUがT&, const T&, T&&である場合reference_typeはU、value_typeはremove_cvref_t<U>promise_type::yield_valueのシグネチャはyield_value(U)
std::generator<U>のUがconst T, const T&&、またはvolatileである場合を考慮する必要はない- これらを機能させるために時間をかける価値はない
std::generator<T>のTがCV・参照修飾されていない場合value_typeのデフォルトはTreference_typeはT, const T, const T&&ではないTはP2168R3で提案されていたがその時点での著者はそれが正しい選択ではないことに同意している- これによって、
T, const T, const T&&は候補から外れる
co_yield EXPRをサポートする、この時のEXPRは左辺値もしくは右辺値- これは右辺値のみを
co_yieldできるstd::generator<T&&>では異なる co_yieldに渡される左辺値とconst右辺値は関数の外部から変更できないようにする必要があるco_yieldに渡された非const右辺値は変更されるか、少なくともムーブされる- 必ずそうしなければなら無いという事ではなく、右辺値が変更されることに対する異議があるとは思っていないということ
- これは右辺値のみを
そして、問題となっているのは
std::generator<T>のTがCV・参照修飾されていない場合-
reference_typeはT&&とconst T&のどちらかconst T&: P2502R0T&&: この提案T&は既存のジェネレータで採用されており有効なオプションだが、std::generatorに対して提案した人はいない
co_yieldに左辺値が渡された時にどうすべきか?- P2502R0は
const参照によって直接返すことを提案している - この提案では、コピーしてその右辺値を返すことを提案する
- P2502R0は
-
この提案では、次の4つの理由によってT&&とこの振る舞いが最適であると説明しています。
パフォーマンスとムーブオンリー型のサポート
make_gen()はstd::generator<T>を返す関数であるとして、
| `T&&` | `const T&` |
|---|---|
ranges::copy(generator, output); // no copies make_gen() | to<vector>; // no copies for (auto s : make_gen()) {} // no copies for (auto&& s : make_gen()) { consume(s); // copies (as it should!) consume(std::forward<decltype(s)>(s)); // no copies } |
ranges::copy(generator, output); // copies make_gen() | to<vector>; // copies make_gen() | views::move | to<vector>; // still copies for (auto s : make_gen()) {} // copies for (auto&& s : make_gen()) { consume(s); // copies (as it should!) consume(std::forward<decltype(s)>(s)); // copies consume(std::move(s)); // still copies; } |
この2つの問題は異なる問題ですが、同じサンプルコードで表現できます。この場合のTがムーブオンリーであった場合、上記の全てのコピーはコンパイルエラーとなります。
reference_typeがconst T&であることで、あらゆる場合に要素型のムーブが妨げられることによってこの違いが出ています。generatorが自分で変更できない場合、この問題を解決することはできません。
言語の他の部分との一貫性
std::generator<T>を使用するコルーチン内部co_yield EXPR;は、fがTをとる時のf(EXPR)やTを返す関数の内部でreturn EXPR;した時と同様に考えるのが良い。どちらの場合も、EXPRが左辺値の時はコピーされるが、右辺値の時はそうではない。
Tを取る関数の引数の場合- 同等のものは、
T&&とconst T&を取るオーバーロードであると認識されている。xvalue引数の最終的な状態は呼び出された側に依存するため厳密には等価ではないが、std::move()して渡した後の変数の状態は通常気にされないので無視できる。 - さらに、ムーブ不可能なxvalueを
T&&/const T&をとる関数に渡すことはできても、Tを取る関数に渡すことはできない。
- 同等のものは、
これは、std:generator<T>::promise_type::yield_value()の振る舞いについてのこと(及び提案)です。寿命が短すぎるためTを直接取ることはできないため、次善の策としてT&&を取るようにしておき(これはTが参照の場合にも正しい動作をする)、copyable(かつmovableでない)非参照の型のためにconst T&のオーバーロードを提供して渡されたオブジェクトのコピーを作成できるようにします。
ジェネレータのユースケースに最適
std::generator<T>はその名前が示すように、複数のTのオブジェクトを生成して返す場合に最適なツールです。一方で、既存のデータ構造に対してイテレータを作成するためのツールにはなり得ません。一般的にその用途にはforward_rangeが求められますが、std::generatorは必然的にinput_rangeにしかなりえません。
そのため、範囲の各要素は高々1度しかアクセスされず、std::generatorを使用するコルーチンが新しいオブジェクトを生成する場合にそれを一々コピーさせるのは明らかに無駄です。
筆者の方のコードベースでは、このジェネレータのようなものを使用していませんが、似たようなパターンを色々な場所で使用しているようです。そこでは、連続した値の生成のためにSTLスタイルのイテレータではなくstd::optional<T>を返すgetNext()のようなものを使用しています。そして、それを使用するほぼすべての場所では、返されるのは右辺値であるか、ムーブが安全なローカル変数です。そのようなAPIは当初、呼び出し側が所有するオブジェクトを返すためにT*を返すことができましたが、誰も使用しなかったようです。
シンプルさ
この提案の主なポイントは、std::generator<T&&>::iterator::operator*()は常にT&&を返す必要がある、ということです。
これは、言語の参照の折り畳みルールを使用して、Tが参照型である場合も含めてすべての場合に正しい振る舞いをします。それによって、reference_type等の導出にconditional_tを用いるなど複雑なことをしなくても良くなります。
これらの理由により、co_yieldの引数型およびoperator*の戻り値型として非参照のTを使用することはいいアイデアではなく、常にT&&を使用するようにすることを提案しています。
この提案は既にLEWGのレビューを終えて、P2529への適用に合意が取れています。これによって、std::generator<T>はstd::generator<T&&>と同等の振る舞いをするようになります。
P2530R0 Why Hazard Pointers should be in C++26
標準ライブラリにハザードポインタサポートを追加する提案。
これは現在Concurrency TS v2(未発行)に含まれているハザードポインタ関連のユーティリティのサブセットをC++26の標準ライブラリに含めようとする提案です。以前はP1121で議論されていたため、詳細はそちらの解説記事を参照してください。
この提案の動機と根拠は、P1121R3のハザードポインタの設計が2018年頃にはほぼ固まっており変更されていない事、FacebookのFollyというライブラリで2016年頃から実装され、Facebook社内で2017年頃から実利用されていること、などによります。提案しているのはConcurrency TS v2にあるハザードポインタ関連のすべてではなく上記の経験に基づく安定している一部であり、文言の変更も軽微であるため少ない労力で導入できると述べています。
P1121R3およびConcurrency TS v2から含まれていないのは次の2点です
- カスタムドメイン
- グローバルクリーンアップ関数(
hazard_pointer_clean_up())- グローバルクリーンアップ関数が呼び出されると、ハザードポインタによってロックされているすべてのリソースが再利用可能となる(つまりロックが解放される)。これをsynchronous reclamationと呼ぶ。
- Follyでは、グローバルクリーンアップよりも効率的なsynchronous reclamation(cohort-based synchronous reclamation)を実装しており、2018年頃から利用されている。こちらを導入させたいためグローバルクリーンアップはこの提案に含めない。
- ただし、cohort-based synchronous reclamationに関する文言は複雑となることが予想され(Concurrency TS v2にも含まれていない)、ハザードポインタの一般的なユースケースのサポートを優先するためにこちらも将来の提案とする。
結果として、提案されているのはハザードポインタクラスそのもの及びそのファクトリ関数(とswap()特殊化)のみです。ただしこのドロップされたものも含めて将来の拡張の計画があるようで、それを意識した文言になっています。
P2531R0 C++ Standard Library Issues to be moved in Virtual Plenary, Feb. 2022
今回(2022/02)の会議で採択された標準ライブラリについてのIssue報告とその解決。
- 3088. forward_list::merge behavior unclear when passed *this
- 3471. polymorphic_allocator::allocate does not satisfy Cpp17Allocator requirements
- 3525. uses_allocator_construction_args fails to handle types convertible to pair
- 3601. common_iterator's postfix-proxy needs indirectly_readable
- 3607. contiguous_iterator should not be allowed to have custom iter_move and iter_swap behavior
- 3610. iota_view::size sometimes rejects integer-class types
- 3612. Inconsistent pointer alignment in std::format
- 3616. LWG 3498 seems to miss the non-member swap for basic_syncbuf
- 3618. Unnecessary iter_move for transform_view::iterator
- 3619. Specification of vformat_to contains ill-formed formatted_size calls
- 3621. Remove feature-test macro __cpp_lib_monadic_optional
- 3632. unique_ptr "Mandates: This constructor is not selected by class template argument deduction"
- 3643. Missing constexpr in std::counted_iterator
- 3648. format should not print bool with 'c'
- 3649. [fund.ts.v3] Reinstate and bump __cpp_lib_experimental_memory_resource feature test macro
- 3650. Are std::basic_string's iterator and const_iterator constexpr iterators?
- 3654. basic_format_context::arg(size_t) should be noexcept
- 3657. std::hash<std::filesystem::path> is not enabled
- 3660. iterator_traits<common_iterator>::pointer should conform to §[iterator.traits]
- 3661. constinit atomic<shared_ptr
> a(nullptr); should work
P2532R0 Removing exception_ptr from the Receiver Concepts
P2300について、receiverコンセプトからexception_ptrを取り除く提案。
P2300のreceiverの定義は次の2つのコンセプトからなります。
template <class T, class E = exception_ptr> concept receiver = move_constructible<remove_cvref_t<T>> && constructible_from<remove_cvref_t<T>, T> && requires(remove_cvref_t<T>&& t, E&& e) { { execution::set_stopped(std::move(t)) } noexcept; { execution::set_error(std::move(t), (E&&) e) } noexcept; }; template<class T, class... An> concept receiver_of = receiver<T> && requires(remove_cvref_t<T>&& t, An&&... an) { execution::set_value(std::move(t), (An&&) an...); };
ここで要求されているのは、receiverオブジェクトに対してはset_stopped(), set_error(), set_value()の3つの関数(tag_invokeによるCPO)による呼び出しが可能であることです。この3つはreceiverの提供する3つの通知チャネルであり、接続されたsenderによってその処理の実行後にいずれか1つが呼び出されることが保証されています。3つはそれぞれ、完了(キャンセル)・エラー・成功時の結果の通知を担うチャネルです。
この提案が問題としているのはset_error(R, E)チャネルのデフォルトのエラー型で、上記定義(現在)ではexception_ptrが設定されています。これについて、LEWGでのP2300レビュー中に次のような問題が提起されました
set_value()は例外を投げる可能性があり(何が飛んでくるかわからず)、senderがcompletion signature(set_error(), set_value()チャネルで送信される値の型)を計算するように要求された時でもそれがわからないことから、ほとんどのsenderは実際にその経路が使用されるかに関わらずexception_ptrによって完了するようなcompletion signatureを返してしまう可能性がある。receiver型Rはexception_ptrによるエラーチャネルを提供しなければ、receiver<R>, receiver_of<R, Args...>といったコンセプトを満たすことができない。-
exception_ptrはstd::shared_ptrと比較すると重いエラーチャネルである。このチャネルの存在を要求してしまうと不必要なコード生成を引き起こす可能性が高い - 例外処理のサポートが無い場合が多いフリースタンディング環境でP2300の機能の何が使用可能かが不透明となる
-
この提案では、これらの懸念に対応するために次のような変更を行っています
get_envカスタマイゼーションポイントのデフォルト実装を削除receiver_ofコンセプトはreceiver型とcompletion_signatures<>型を取るようにするreceiverによるset_valueのカスタマイズはnoexceptである必要があるsender_to<S, R>コンセプトでは、R(receiver型)がS(sender型)の全ての完了通知を受け入れる必要があるconnect(s, r)では、r(receiverオブジェクト)がs(senderオブジェクト)の全ての完了通知を受け入れることを要求するget_completion_signaturesはcompletion_signaturesクラステンプレートのインスタンスを返す必要があるmake_completion_signaturesをより一般的になるように調整
これらの変更は、senderのcompletion signatureから得られる情報を用いた型チェックをライブラリ側でより行うようにするものです。これらの変更がなぜこのタイミングでなされたのかというと、元々のsenderは必ずしもcompletion signatureを提供しておらず、その情報を前提とすることができなかったからです。P2300R4(2022年1月発行)での変更によって、そのようなuntyped senderのサポートが削除され、senderはデフォルトかつ全てがtyped sender(completion signatureを提供するsender)となりました。この提案はP2300R4で開かれたこの新しい情報を用いてreceiver(およびP2300全体)のexception_ptrへの依存を減らすものです。
この提案はすでにP2300へ適用されることが決定しています。
P2533R0 Core Language Working Group "ready" Issues for the February, 2022 meeting
今回(2022/02)の会議で採択されたコア言語についてのIssue報告とその解決。
- 1726. Declarator operators and conversion function
- 2494. Multiple definitions of non-odr-used entities
- 2499. Inconsistency in definition of pointer-interconvertibility
- 2502. Unintended declaration conflicts in nested statement scopes
- 2506. Structured bindings and array cv-qualifiers
- 2509. decl-specifier-seq in lambda-specifiers
- 2511. cv-qualified bit-fields
P2534R0 Slides: function_ref in the wild (P0792R7 presentation)
function_ref(P0792R7)の紹介スライド。
内容としてはむしろ、function_refで問題となっている関数ポインタの右辺値を参照するとUBになる可能性があるという問題の紹介がメインです。
struct retry_options { // 実行する処理を受け取るfunction_ref function_ref<payload()> action; ... }; // optに指定された事を成功するまで繰り返すような関数とする auto retry(retry_options opt) -> payload; // retryに渡すオプション auto opt = default_strategy(); // 実行する処理の指定、downloadは引数なしで呼び出してpayloadを返す関数とする opt.action = &download; // 関数ポインタの右辺値を渡している auto result = retry(opt);
function_refの一つの実装として、関数ポインタを渡されたときに関数ポインタへのポインタを保持して呼び出しに使用する、というものがあります。その場合、この例のように関数ポインタの右辺値を渡してしまうと一時オブジェクトへのポインタを保持する事でUBになってしまいます。その場合でも、関数そのものやデリファレンスして関数参照を渡すとUBにはなりません。
opt.action = download; // ok opt.action = &download; // UB opt.action = *(&download); // ok
現在の提案では(そしてこのスライドの結論では)、function_refを関数と関数ポインタで初期化した時の違いがないようにする方向で設計されているようです。
類似の問題として、メンバ関数ポインタを渡した時の振る舞いについての問題があります。
function_ref<void(Ssh&)> cmd = &Ssh::connect; // UB? Ssh ssh{}; cmd(ssh); // ok?
この振る舞いを認めると、内部でメンバポインタを保持するためにunionを使用しなければならなくなるなど、実装が複雑になります。現在の提案では(そしてこのスライドの結論では)、この振る舞いはサポートせず、別の方法(P2511など)によってfunction_refにアダプトする方向性のようです。
function_ref<void(Ssh&)> cmd = nontype<&Ssh::connect>; // ok
P2535R0 Message fences
対象オブジェクトを限定するフェンス、メッセージフェンスの提案。
現在C++で利用できるメモリフェンスにはstd::atomic_thread_fenceがあります。これはstd::atomicオブジェクトへの読み書きの操作がそのフェンスを越えて前後しないようにするためのもので、フェンスが置かれているとそのスレッドの全てのstd::atomicオブジェクト(あるいは間接的に他の変数)の読み書きの順序に影響を与え、フェンスの効果はすべてのスレッドにわたって保証されます。
メモリモデルの説明によく見られる2つのスレッド間でのメッセージパッシングの例のように、特定の少数のスレッドの間でのやり取りのみでフェンスの効果が必要である場合、フェンスのもたらす効果をその他多くのスレッドの間でも保証することは場合によっては(特殊なメモリファブリックやメモリ構造を持つハードウェアなど、例えばGPU等のアクセラレータで)とても高価になります。
メッセージフェンスでは、特定のオブジェクトに対してのみフェンスの効果を適用することでフェンスの効果が及ぶスレッドを限定し、そのようなユースケースにおいてさらなる最適化を図るものです。そのようなメッセージフェンスを標準化することで、ハードウェアや環境固有のより効率的なメカニズムをポータブルかつ容易に利用できるようになります。
| 現在 | この提案 |
|---|---|
x = 1; atomic_thread_fence(memory_order_release); a.store(1, memory_order_relaxed); while(a.load(memory_order_relaxed) != 1); atomic_thread_fence(memory_order_acquire); assert(x == 1); |
x = 1; atomic_object_fence(memory_order_release, x); a.store(1, memory_order_relaxed); while(a.load(memory_order_relaxed) != 1); atomic_object_fence(memory_order_acquire, x); assert(x == 1); |
提案されているのは、std::atomic_message_fence()とstd::atomic_object_fence()の2つです。std::atomic_thread_fence()はその存在がstd::atomicオブジェクトへのアクセスに対してのみ影響を及ぼし、他の変数へは直接的な影響を持ちません。std::atomic_message_fence()はそれと同様に、そのフェンスが介在するstd::atomicオブジェクトに対して暗黙にメッセージフェンスを適用するもので、std::atomic_object_fence()は指定された変数(非std::atomicも含む)に対してメッセージフェンスを適用するものです。
std::atomic_message_fence()をメッセージフェンスと呼び、std::atomic_object_fence()をオブジェクトフェンスと呼んでいます。オブジェクトフェンスは同時にメッセージフェンスでもあり、std::atomic_thread_fence()の事をスレッドフェンスと呼びます。この提案では次のような規定によってメッセージフェンスの効果を指定しています
オブジェクトOと任意のフェンスXとYが存在していて
Oに対する評価(アクセス)AがXの出現よりも前に順序づけられ(sequenced before)、かつXがオブジェクトフェンスならばOとともに起動され、かつYがオブジェクトフェンスならばOとともに起動され 、かつYの出現は、Oに対する別の評価Bよりも前に順序づけられている(sequenced before)
とき、Oに対する評価Aと同じオブジェクトOに対する別の評価Bの間にhappens before関係が定義されます。
さらに、XとYが共にスレッドフェンスであるならば、XはYと同期(X synchronize with Y)します。
なお、この2つのメッセージフェンスに対してはmemory_order_seq_cstを指定することができません。メッセージフェンスは2つのスレッドの間でのメッセージパッシングが成立する程度の順序保証しか与えないため、その順序が別のスレッドからどう観測されるかについて何の保証も与えません。ある特定のメモリ領域への読み書きの推移的な順序に関する保証もなく、sequential consistencyのような強い順序保証を提供するものではないからです。
この部分の9割は以下の方のご指摘によって成立しています。
P2536R0 Distributing C++ Module Libraries with dependencies json files.
P2473R1で提案されているビルド済みモジュールの配布のための、別のアプローチについての提案。
この提案のシナリオは次のようなものです
- あるグループAはC++モジュールとしてライブラリAを構築し、BMI(Binary Module Interface、ビルド済みのモジュールインターフェース)として配布したい。Aはそのパッケージに含まれていない別のモジュールに依存している。
- グループBはライブラリAを使用したい。互換性のあるコンパイラとツールを使用しているのでビルド済みのライブラリやモジュールを使用できる。
- 静的解析(あるいはBMI形式を理解しない他のツール)は、グループBのソース・ビルドにおいてモジュールのソースとそれをビルドするために使用されたコンパイルオプションを見つける必要があり、ここに2つのシナリオがある
- . メインビルドが成功した後でモジュールを再ビルドする。つまり、グループBのビルドで生成された情報を利用できる
- . メインビルドが行われる前にモジュールを再ビルドする。Visual Studioのインテリセンスなど
この時、2と3においてビルド済みモジュールを活用するために必要な情報は何で、ライブラリAから何が必要で、どう見つかる必要があるか?を考え、それらの必要な情報をJSONファイルとしてコンパイラが出力するようにすることを提案するものです。
以下、提案の説明の訳。
ビルド済みのモジュールを使用するにはどのような情報が必要か?
- 2 : モジュールAを利用するとき
- 3 : 静的解析など、モジュールAのインターフェースをリビルドするとき
- グループBのPC上にある、モジュールAのインターフェースのソースファイルの場所
- グループBのPC上にある、すべての依存インクルードファイルの場所
- すべてのモジュール依存関係(上2つと同じ情報など)
- 現在のPCに依存しない(場所以外の)ビルドオプション
メインビルドによって生成された依存関係情報使用してモジュールをリビルドする(シナリオ3.1)
コンパイラはモジュールそのものも含めた翻訳単位をビルドするために、使用しているすべてのBMIの場所を認識している必要があります。したがって、この情報を他の情報(#include等の依存関係情報)と共に出力しておくことができます。できれば、現在MSVCが/sourceDependenciesに対して生成しているような、簡単に解析可能なjson等の形式であることが望ましいです。
インクリメンタルビルドをサポートするにはすべてのソース依存関係に関する情報が必要であるため、これらの情報の必要性はこの提案の前提シナリオ固有のものではありません。
例えば、グループBの次のようなソースファイル(source.cpp)に対しては
/// source.cpp import ModuleA; // ライブラリAのモジュール, AのパーティションとモジュールCに依存する import ModuleB; // グループBの所有しているモジュール ...
次のようなソース依存関係ファイル(source-dependencies)を出力するものとします
{ "Version": "1.1", "Data": { "Source": "C:\\PartyB\\sources\\source.cpp", “Includes” = […], "ImportedModules": [ { "Name": "ModuleA", "BMI": "C:/Path/To/LibraryA/x64/SpecialConfig/ModuleA.ixx.ifc" }, { "Name": "ModuleA:PartitionA", "BMI": " C:/Path/To/LibraryA/x64/SpecialConfig/ModuleA-PartitionA.ixx.ifc" }, { "Name": "ModuleC", "BMI": " C:/Path/To/LibraryC/x64/Release/ModuleC.ixx.ifc" }, { "Name": "ModuleB", "BMI": "C:/Path/To/Outputs/x64/MyConfig/ModuleB.ixx.ifc" }, ], "ImportedHeaderUnits": [] } }
ModuleB.ixx.ifcファイルはグループBのビルドの一部として同じルールの下でビルドされており、そのsource-dependenciesファイルはifcファイルと同じ場所に同じ名前であるはずです。したがって、C:/Path/To/Outputs/x64/MyConfig/ModuleB.ixx.ifc.jsonが存在し、次のような内容となります
{ "Version": "1.1", "Data": { "Source": "C:\\PartyB\\sources\\ModuleB.ixx", "ProvidedModule": "ModuleB", “Includes” = […], "ImportedModules": […] "ImportedHeaderUnits": […] } }
C:/Path/To/LibraryA/x64/SpecialConfig/ModuleA.ixx.ifcおよび他のifcファイルの近くにこれらと同様のjsonファイルがある事で、source.cppのビルドに使用したすべての依存関係(インクルードファイル、モジュール名およびそのソース)が判明したことになります。また、すべての依存関係の正確な場所も同時に把握することができます。
このようなsource-dependencies jsonファイルによってすべての依存関係の場所を把握できるため、メインビルドが成功した後で任意のモジュール(モジュールAを含めて)をリビルドできるようにする(3.1のシナリオ)ために、あとはコマンドラインオプションなどの場所を示すものではないオプション(#defineなど)だけが必要です。
dependencies jsonファイルによるライブラリAのパッケージ(シナリオ1)
ライブラリのパッケージ構造は任意ですが、少なくとも次のものを含んでいる必要があります
例えばライブラリA(モジュールAとそのパーティション、依存するモジュールC)の場合次のようなディレクトリ構造となり
LibraryA
Sources
ModuleA.ixx
ModuleA-PartitionA.ixx
x64
SpecialConfig
ModuleA.ifc
ModuleA.ifc.d.json
ModuleA-PartitionA.ifc
ModuleA-PartitionA.ifc.d.json
LibraryA.lib
x64
Release
…
x64/SpecialConfig/ModuleA.ifc.d.jsonは次のようになります
{ "Version": "1.1", "Data": { "Source": "../../sources/ModuleA.ixx", // このファイルの場所からの相対パス "ProvidedModule": "ModuleA", “Options”=[…], // 構成固有の、場所ではないオプション "ImportedModules": [ { "Name": "ModuleA:PartitionA", "BMI": ". /ModuleA-PartitionA.ixx.ifc" // このパッケージ依存関係 } { "Name": "ModuleC", "BMI": "" // このパッケージの外の依存関係 } ] } }
ライブラリのビルドで(Bのビルド時と同様の)source-dependencies jsonファイルが出力される場合、このファイルはそこから簡単に作成できます。
モジュールAをグループBのビルドで使用し(シナリオ2)、そのビルド情報を使用せずにAをリビルドする
モジュールAをグループBのビルドで使用するにはAのBMIの場所をBのビルド構成に外から与える必要があります。これはBMIの名前が常に定まっていないためで、パッケージマネージャが行うかユーザーが手動で行う(コンパイラの検索パスのどこかにBMIを配置する)ことで可能です。BMIとモジュールを対応付けるためには、BMI名とモジュール名の対応が事前に分かっている必要があります。これはユーザーが手動で対応を指示する、モジュール名をBMI名にエンコードするなどの方法で可能となります。
モジュール名をBMI名にエンコードする場合、BMI名がコンパイラの期待するエンコードと一致する必要があります。例えば:はwindowsではファイル名に使用できないため別の文字に置き換える必要があります。このことは、BMIをコンパイルしたコンパイラと互換性のある環境を使用していれば可能かもしれませんが、そうではない場合にはうまく働かない可能性があります。
仮にモジュール名のBMI名へのエンコードに関して標準化できたとしても、それを要求してしまうとモジュール名が変更されるたびにBMI名/場所のビルドオプションの変更が必要となります。これは、ユーザー/IDEの両方に負担をかけることになります(BMIファイルはコンパイラ固有のビルド成果物であるため、パースに向くものではないものと考える)。
しかし、上記のd.jsonファイルがBMIの近くにあれば、ビルドにモジュール検索パスだけが指定されている時でも、このパスですべてのd.jsonファイルを発見することができ、それらを読み込むことでモジュール名とBMIパスの対応を記録したビルド前モジュールマップを作成することができます。
この情報は、グループBのソースでインポートされているすべてのモジュールの依存関係を解決するのに十分であり、必要なライブラリがすべて同一PC上に存在している場合はすべてのライブラリモジュールを解決することができます。また、BMIやモジュールインターフェースの名前にモジュール名をエンコードする必要もなくなり、異なるコンパイラがモジュールをビルドするために必要なすべての情報を提供することができます。
提案の概要
インクリメンタルビルドのサポートには翻訳単位のコンパイルで使用されるすべてのファイルのリストが必要となります。現在、ほとんどのコンパイラはインクリメンタルビルドをサポートしているため、それらの#include情報やソースの場所を含む依存関係ファイルを作成することができるはずです。
モジュールのBMIは#includeするファイルと同様の依存関係です。コンパイラは翻訳単位をコンパイルするために、それらの正確な場所を知っていなければならず、依存関係としてそれらをリストアップすることができるはずです。
従って、この提案では、コンパイラは次のものを含む依存関係の情報をJSON形式(解析や修正が簡単にできる)で出力できるようにすることを提案します
モジュール依存関係情報はP1689R4でソーススキャンについて提案されたもの(つまり、ビルド前に生成される)と似ている部分もありますが、ここではBMIとソースファイルの場所が追加されています。
また、ビルド済みモジュールを配布するすべてのライブラリは、以下の情報を含めるようにする事も提案します
BMIはビルド時の設定(おそらくリリースビルドなどのこと)に依存しているため、d.jsonファイル内の依存関係やコンパイルオプションも同様の設定に依存します。ビルド時にどの設定を選択するかについては曖昧さはなく、d.jsonファイルにはモジュールインターフェースソースの場所とそのすべての依存関係の名前(と場所)が含まれており、モジュール名をファイルシステムでエンコードする必要はありません。
それぞれのBMIの近くにd.jsonファイルがあれば、すべてのモジュールをリビルドするシナリオにおいて十分な情報を提供できます。
この提案では各JSONファイルの形式について、現在MSVCが/sourceDependenciesに出力しているものと同様のものを使用していますが、実際のフィールド名や追加の内容については標準化委員会における合意が必要であり、これから決めることです。
- P2473R0 Distributing C++ Module Libraries - [C++]WG21月次提案文書を眺める(2021年10月)
- P1689R3 Format for describing dependencies of source files - [C++]WG21月次提案文書を眺める(2020年06月)
- P2536 進行状況
P2537R0 Relax va_start Requirements to Match C
可変長引数関数を0個の引数で宣言できるようにする提案。
C23で古いK&Rスタイルの関数宣言が削除されたことで、それを有効活用していたCから他言語の関数を呼び出すためのトリックが使用できなくなります。
// C23以前のK&R Declaration // 実装は別言語によってどこかで実装されている // 引数0の関数宣言、では無い double compute_values(); int main () { // C: K&Rルールで許可された宣言、C23で削除 // C++: ill-formed、関数は0個の引数をとる double x = compute_values("with_pi", 2.4, 2.7, true); return (int)x; }
compute_values()の実装は他言語で行うことができ、実体との接続等を適切に整えた上でC側でこのように関数宣言だけを用意しておけば、それをCから呼び出すことができました。しかし、C23でK&Rスタイルの関数宣言が削除されたことで、このトリックは使用不可能となります。
C++では元々この形の宣言は引数0個の関数宣言であリ、f(...)と言う関数宣言によってK&Rスタイルの関数宣言をAPI/ABI両面で近似できていました。しかし、Cでは可変長引数関数がその可変長引数の利用のために可変長引数の前に最低1つの名前のある引数を必要とすることから、Cでは逆にf(...)のような関数宣言を使用できません。これは、va_startがその呼び出しに際してva_listと可変長引数の直前の引数名の2つのパラメータを取るためです。
void f(int arg1, ...) { // 可変長引数リスト va_list args; // 可変長引数の使用を開始 va_start(args, arg1); ... }
C23では、最初の例のような他言語関数呼び出しのユースケースを保護するためにf(...)の形式の関数宣言を許可しており、同時にva_startが1つの引数(va_list)のみで呼び出すことができるようにされました。C++ではf(...)の形式の関数宣言は元々可能でありC23のそれと同じ意味を持っていますが、va_startの定義はCに合わせる形で2つの引数を要求するようになっていました。この提案は、C++側でもC23でのその修正に従って、va_startが1引数で呼び出すことができるように修正するものです。
この提案によって、最初の例(をC23に合わせて修正したコード)はCとC++で一貫した意味を持つコードとなります。
// C23からok、C++は以前からok // 定義は多言語など、このソースの外でなされている double compute_values(...); int main () { // C/C++両方でポータブル double x = compute_values("with_pi", 2.4, 2.7, true); return (int)x; }
va_start| Programming Place Plus C言語編 標準ライブラリのリファレンス- Ever Closer - C23 Draws Nearer | The Pasture
- P2537 進行状況
P2538R0 ADL-proof std::projected
C++20 Rangeアルゴリズムが不必要な型の完全性要求をしないようにする提案。
まず、説明のために不完全型(定義の無い型)をテンプレートパラメータに受け取るとコンパイルエラーを起こすクラスを用意します。
// 完全性を要求される文脈で、Tに不完全型を指定されるとエラーを起こすクラス template<class T> struct Holder { T t; }; // 不完全型 struct Incomplete; Holder<Incomplete> h; // error
Holder型の完全性(定義の存在)が要求されるとテンプレートパラメータTがメンバとして実体化し同様に完全性が要求されるため、Tが不完全型だとコンパイルエラーを起こします。
不完全型はその使用が制限されており、完全型(定義を備えた型)が要求される文脈で使用されるとコンパイルエラーを起こします。そのような操作の1つにはADLがあります。
Holder<Incomplete> *p; // ok、ポインタとしての利用は完全性を要求しない int f(Holder<Incomplete>*); // ok int x = f(p); // error、ADLでは完全型が必要 int x = ::f(p); // ok、ADLは行われない
不完全型はポインタとして宣言することはでき、ネイティブのポインタ型T*ではTの完全性を要求しません。また、ネイティブポインタに対する多くの操作はADLをトリガーしません。
Holder<Incomplete> *a[10] = {}; // 10個のnullptr Holder<Incomplete> **p = a; // ok p += 1; // ok assert(*p == nullptr); // ok assert(p == a+1); // ok assert(std::count(a, a+10, nullptr) == 10); // ok
libc++(clangの標準ライブラリ実装)のテストスイートには、STLのアルゴリズムが不必要に型の完全性を要求しないことをチェックするテストが含まれており、それらのテストの事をADL-proofingテストと呼んでいます。libc++実装者たちは、これは標準への適合性の問題ではなくかなり重要な実装品質の問題だと考えているようです。なぜなら、早期の不必要な型の完全性要求はユーザーにとって困難なハードエラーの原因となるほか、ODRの問題を引き起こす可能性があるためです。
C++20 Rangeアルゴリズムではまさにこのことが問題となり、ADLから保護されていません。
Holder<Incomplete> *a[10] = {}; // 10個のnullptr assert(std::count(a, a+10, nullptr) == 10); // ok assert(std::ranges::count(a, a+10, nullptr) == 10); // error
より詳しく見てみると
using T = Holder<Incomplete>*; static_assert(std::equality_comparable<T>); // ok bool x = std::indirectly_comparable<T*, T*, std::equal_to<>>; // error bool y = std::sortable<T*>; // error
std::indirectly_comparable<T*, T*, Pred>はstd::indirect_binary_predicate<Pred, projected<T*, identity>, projected<T*, identity>>で定義されており、それはstd::projected<T*, identity>型のイテレータitに対する*itが有効な式であるかどうかをチェックしています。ADLは*itという式で発動しており、それによってprojected<T*, identity>の関連するすべての型(Holder<Incomplete>も含む)に対して完全性が要求され、Holder<Incomplete>の完全性が要求されてエラーが発生しています。
ADLでは、関数に渡された引数の型から関連する型を抽出し、その型の関連する名前空間(その型を囲う最も内側の名前空間)を取得します。引数型がクラステンプレートの特殊化である場合、クラステンプレートのテンプレート引数(非型テンプレートパラメータおよびテンプレートテンプレートパラメータを除く)を関連する型として抽出してしまうため、テンプレートパラメータの型に対して完全性の要求が発生します。
これによって、std::sortやstd:countなどはHolder<Incomplete>のようなADLで危険な型に対して安全に使用できるのに対して、rangesの対応するものはそうではない、という問題が生じています。
この問題を解決し、すべてのRangeアルゴリズムをADLから保護するためには、Tがprojected<T*, identity>の関連する型(associated type)にならないようにすればよく、これはADLに対するファイアウォールを導入することで実現可能です。
// 現在のstd::projected定義 template<class Associated> struct projected { ... }; // この提案によるstd::projected定義 template<class T> struct __projected_impl { struct type { ... }; }; template<class NonAssociated> using projected = __projected_impl<NonAssociated>::type;
ADLは派生クラスに対する基底クラスを関連する型として関連付けますが、ネストしたクラスにおける包含されたクラスは関連付けません。そのため、__projected_impl<NonAssociated>::typeはprojected<NonAssociated>の関連する型ではなくなります。__projected_impl<NonAssociated>::typeの::は不要なADLに対するファイアウォールとして機能していると見ることができます。
このような考慮はP2300R4では既に文言として存在しており、同様の指定をstd::projectedに行えれば理想です。しかし、std::projectedはC++20機能として出荷済みであるため、ここでは後方互換性を取った方法(__projected_implとusingによるエイリアス)を提案しています。
- ADL can interfere even with uglified names - Arthur O’Dwyer
- Argument-dependent lookup - cppreference
- P2538 進行状況
P2540R0 Empty Product for certain Views
viewの空積は空のタプルになるべきという提案。
この提案の対象は明示されていませんが、おそらくviews::zipファミリやviews::cartesian_productを対象にしています。これらのviewは入力の2つ(以上)のrangeを1つのrangeに変換するものであり、入力のrangeが1つもない場合は共にstd::empty_view<std::tuple<>>となります。この提案は、この場合の結果はstd::tuple<>になるべきというものです。ただし、このことはzipに対して拡張しない(有用ではないため)としています。
以下、提案の説明の訳。
2つのものに対する積を3以上のものの積に拡張するのは自然なことで、$P=A×B$から$P = \prod_{i=0}^n a_i = a_1 ... a_n$へと拡張されます。多くの積では、空積の値は単位元に設定され、空積は積の恒等式となるようにしています。これによって、他の演算との整合性がとれるなど色々と都合がよくなります。
空積を恒等式要素に設定することで、fold 0はより健全な足場を得ます。基本ケースが自動的に単位元を提供するため、単位元を指定する必要はありません。
デカルト積は集合管の全ての関係の全体とみなすことができます。実際、集合間の関係はしばしばデカルト積の部分集合として定義され、集合間の関係はその関係に含まれる集合の要素同士を関連付けます。集合の無いデカルト積(空積)は$\empty \to \empty$から、ちょうど1つの関数、空関数が存在しています。このことは、集合の無いデカルト積の結果の基数(濃度)が0ではなく1であるべきことを示しています。
特に、zipはインデックス付き集合の内結合であり、デカルト積の対角線上の集合であるという性質を持っています。しかし、zipの恒等式要素は空のタプルの集合であり、空のタプルの無限回の繰り返しによる範囲となります。もし空の範囲のzipをその単位元にすることを許可したら、概念的に同じものを2つの異なる形式で表現し異なる結果を返すという矛盾をシステムに持ち込むことになり、これは良くないことです。
これらのことからこの提案では、空の範囲のデカルト積は1つの要素の範囲であり、それは空のタプル(std::tuple<>)であることを提案していますが、それをzipにまで拡張しないことを提案しています。空の範囲のzipはデカルト積の対角線になるはずですが、それはzipを消滅させるもので、実際には有用ではありません。空の範囲に対するほかの操作がそうであるように、これは未定義にしておくべき、と述べています。
P2542R0 views::concat
同じ要素型を持つ異なる型の範囲を連結するRangeファクトリ、views::concatの提案。
これは引数として受け取った任意個数の範囲を繋げて1つの範囲として扱うものです。
std::vector<int> v1{1,2,3}, v2{4,5}, v3{}; std::array a{6,7,8}; auto s = std::views::single(9); std::cout << fmt::format("{}\n", std::views::concat(v1, v2, v3, a, s)); // output: [1, 2, 3, 4, 5, 6, 7, 8, 9]
これはRangeアダプタではなくRangeファクトリなので、パイプ記法(|)の右辺で用いることはできません。
views::concatによって連結可能な範囲は、その全ての参照型(range_reference_tおよびrange_rvalue_reference_t)が共通の参照型(common_reference)を持ち、全ての値型(range_value_t)が共通の型(common_type)を持っている必要があり、さらに入力の範囲それぞれの参照型・値型間にcommon_referenceとrange_value_tの同様の要求と、変換可能性の要求があります。複雑ですが、とりあえず全部同じ型であれば意図通りに動作します。
なお、0引数views::concat()はコンパイルエラーとなり、1引数views::concat(r)はviews::all(r)と等価となります。
入力のrangeの列をRs...とすると、concat_viewの諸特性は次のようになります
reference:common_reference_t<range_reference_t<Rs>...>value_type:common_type_t<range_value_t<Rs>...>rangeカテゴリRsが全てrandom_access_range && sized_range:random_access_rangeRsの最後の範囲がbidirectional_rangeでありそれ以外の範囲がconstant-time-reversibleとなる場合 :bidirectional_rangerange型Rがconstant-time-reversibleとなるのは次のいずれかの場合bidirectional_range<R> && common_range<R>sized_range<R> && random_access_range<R>
Rsが全てforward_range:forward_range- それ以外 :
input_range
common_range: 次のいずれかの場合Rsが全てcommon_rangeRsが全てrandom_access_range && sized_range
sized_range:Rsが全てsized_rangeconst-iterable:Rsが全てconst-iterableであり、const Rsが全て連結可能(views::concat可能)である場合borrowed_range: ×
bidirectional_rangeとなるときは少し複雑ですが、少なくとも全ての範囲はbidirectional_rangeでなければなりません。その上で、Rsの最後の範囲(n番目とすると)の最初の要素から--するときのことを考えると、n-1番目の範囲のend() - 1の位置に移動しなければなりません。それが可能となるのは、n-1番目の範囲Rが、単にbidirectional_rangeであるときはcommon_rangeでなければならず(そうでないと--end()ができない)、Rがrandom_access_rangeならばsized_rangeでもある必要があります(common_rangeを要求せずにend() - 1の位置に行くにはサイズが必要となり、サイズを定数時間で求めるためにはsizedである必要がある)。そして、これは最後(n番目)の範囲を除いたRsの残りの全てについて同じことが言えます。そのため、views::concatの入力Rsの最後の範囲はbidirectional_rangeであることしか求められておらず、それ以外の全ての範囲はその条件をエンコードしたconstant-time-reversibleという制約を満たす必要があるわけです。
concat_viewは、入力の全ての範囲がborrowed_rangeであればborrowed_range(入力範囲のイテレータ有効性はその範囲オブジェクトのライフタイムから切り離されているrange)とすることができます。しかしその場合、concat_viewオブジェクトおよびconcat_view::iteratorは全ての入力範囲のイテレータを自身の内部に保存しておかねばならなくなります(concat_viewが構築されたその瞬間しか、入力の範囲の生存を仮定できないため)。これはイテレータサイズの肥大化を招き、実装が複雑になります。concat_viewが常にborrowed_rangeでないとすると実装はより単純になり、イテレータは常にアクティブな1つだけを保持し、境界を接続するためだけにconcat_viewオブジェクトを参照すれば良くなります。Range-v3の経験ではconcat_viewのborrowed_range性は重要とされないため、Range-v3およびこの提案ではborrowed_range性をドロップすることで安価な実装を選択しています。
P2544R0 C++ exceptions are becoming more and more problematic
C++の例外について、マルチスレッド環境のパフォーマンスおよび代替手段との比較についての報告。
ここでは、次のようなコードの入力データに確率的に例外を投げる値を挿入することで、例外発生確率ごとの全タスク実行時間を計測しています。
struct invalid_value {}; void do_sqrt(std::span<double> values) { for (auto& v : values) { if (v < 0) throw invalid_value{}; v = std::sqrt(v); } } // このようにして10万回実行 unsigned exceptionsSqrt(std::span<double> values, unsigned repeat) { unsigned failures = 0; for (unsigned index = 0; index != repeat; ++index) { try { do_sqrt(values); } catch (const InvalidValue& v) { ++failures; } } return failures; } // マルチスレッド時はexceptionsSqrt()を複数スレッドで走らせる
この入力(values)は基本的には全て1.0の100個の配列ですが、設定した確率に応じてランダムに-1が挿入されます。パフォーマンス計測のため、この関数を10万回実行します。
| 例外発生確率\スレッド数 | 1 | 2 | 4 | 8 | 12 |
|---|---|---|---|---|---|
| 0.0% | 19ms | 19ms | 19ms | 19ms | 19ms |
| 0.1% | 19ms | 19ms | 19ms | 19ms | 20ms |
| 1.0% | 19ms | 19ms | 20ms | 20ms | 23ms |
| 10% | 23ms | 34ms | 59ms | 168ms | 247ms |
傾向として、例外発生確率が高くなると実行時間が長くなっています。そして、スレッド数が増えるほど発生確率の上昇に対するパフォーマンスの低下が顕著に見られるようになります。
この数値はGCC11.2を使用したLinux環境で計測されたものですが、Clang13やWindowsのMSVCにおいても同じ傾向だったとのことです。また、上記計測はRyzen 9 5900Xを使用したもので、さらにスレッド数の多いEPYC 7713(128C/256T)で実行したのが次の結果です
| 例外発生確率\スレッド数 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
|---|---|---|---|---|---|---|---|---|
| 0.0% | 24 | 26 | 26 | 30 | 29 | 29 | 29 | 31 |
| 0.1% | 29 | 29 | 29 | 29 | 30 | 30 | 31 | 105 |
| 1.0% | 29 | 30 | 31 | 34 | 58 | 123 | 280 | 1030 |
| 10% | 36 | 49 | 129 | 306 | 731 | 1320 | 2703 | 6425 |
(単位は全てms)
この場合、1スレッドしか使用していないときでも0.1%の例外発生率からパフォーマンスの劣化が目立ち始めています。このことは、実際に使用しているスレッド数ではなく使用可能なスレッド数が増加することで例外処理のパフォーマンスが劣化することを示しています。
一方で、C++の例外は、例外が発生しない限りはオーバーヘッドが(ほぼ)ゼロであるという利点があります。このことは、呼び出しごとに余分な作業をほとんど行わない関数を大量に呼び出すようなコードで確認することができます。
struct invalid_value {}; unsigned do_fib(unsigned n, unsigned max_depth) { if (!max_depth) throw invalid_value(); if (n <= 2) return 1; return do_fib(n - 2, max_depth - 1) + do_fib(n - 1, max_depth - 1); }
このコードをn = 15、確率的にmax_depthが13に設定される条件で1万回実行し計測した結果は次のようになります
| 例外発生確率\スレッド数 | 1 | 2 | 4 | 8 | 12 |
|---|---|---|---|---|---|
| 0.0% | 12 | 12 | 12 | 14 | 14 |
| 0.1% | 14 | 14 | 14 | 14 | 15 |
| 1.0% | 14 | 14 | 14 | 15 | 15 |
| 10% | 18 | 20 | 27 | 64 | 101 |
(単位は全てms)
スレッド数が増えるほど/例外発生確率が増えるほど、パフォーマンスが低下するという傾向に変化はありません。
これから比較するC++例外の代替案では、sqrtよりもこのfibの方がコストがかかるため、例外の利点も合わせた比較のためにこちらの値を使用します。
この提案では、上記のような傾向を生じさせるC++例外の問題点として次の2つをあげています
- 例外オブジェクトは、継承構造のため、あるいは
std::current_exception()のような非ローカル性のため、動的メモリに確保される。これはthrowをgotoに最適化することを妨げている他、メモリ不足の状況でthrowが例外を投げるという問題がある。 - 現代のC++コンパイラが使用するテーブル駆動型のアンワインド(スタック巻き戻し)ロジックが、テーブルを同時変更から保護するためにグローバルミューテックスを取得するため、例外のアンワインド処理は実質的にシングルスレッド実行になる。これは、コア数の多い環境では特に問題となり、例外をほとんど使用できなくなる。
throw;(再スロー)やstd::current_exception()のような構文はプログラムのどの場所にも存在する可能性があり、特に、キャッチブロック内で呼び出される関数内(特に、インライン化されていない関数内)で呼び出される可能性があるため、例外オブジェクトの構築を単純に省略したりすることができません。そして、この(1つ目の)問題は言語仕様を変更しないと回避できません。
2つ目の問題は実装によって回避可能かもしれませんが(提案中ではGCC実装を変更することでこの問題が解決可能であることを確認しているが)、それは確実に大きなABIの変更をもたらすため、共有ライブラリを含めた関連するコンポーネント全てにおいて慎重な調整が必要となります。
C++に対しては、いくつかの例外を代替するものが提案されています。ここでは、次のものについて先ほどのsqrt, fibの計測を行なっています。
std::expectedboost::LEAF- throwing values(P0709R4)
それぞれ結果は次のようになります(これらの手法においてはマルチスレッド環境でのパフォーマンス劣化要因がないため、マルチスレッドの結果はシングルスレッドと同じとして省略します)
std::expected
| 計種別\例外発生確率 | 0.0% | 0.1% | 1.0% | 10% |
|---|---|---|---|---|
sqrt |
18 | 18 | 18 | 16 |
fib |
63 | 63 | 63 | 63 |
boost::LEAF
| 計種別\例外発生確率 | 0.0% | 0.1% | 1.0% | 10% |
|---|---|---|---|---|
sqrt |
18 | 18 | 18 | 16 |
fib |
23 | 23 | 23 | 22 |
このテストにおいては、-fno-exceptionsを使用した結果となっています。これがない(例外を有効にした)場合、例外が全く投げられない場合のfibケースは最低29msかかります。これは例外が真にゼロオーバーヘッドではないことを示しています(try-catchブロックによるものではなく、標準ライブラリなどのあらゆる場所で例外が投げられることを考慮したコードとなることによるオーバーヘッド)。
- throwing values(P0709R4)
これは提案中の機能で、任意の例外を許可せず、代わりに2つのレジスタだけを使用して効率的に受け渡すことのできる特定の例外クラス型を使用するものです。純粋なC++で実装できないため、ここではC++でエミュレートした場合(例外オブジェクトは最大でもポインタサイズ)と、インラインアセンブラによってハードコートされた実装の2つをテストしています。
C++エミュレーション
| 計種別\例外発生確率 | 0.0% | 0.1% | 1.0% | 10% |
|---|---|---|---|---|
sqrt |
18 | 18 | 18 | 16 |
fib |
19 | 18 | 18 | 18 |
| 計種別\例外発生確率 | 0.0% | 0.1% | 1.0% | 10% |
|---|---|---|---|---|
sqrt |
18 | 18 | 18 | 16 |
fib |
13 | 13 | 13 | 13 |
これらの代替案はsqrtケースでは例外処理を上回る一方で、fibケースではパフォーマンスにオーバーヘッドが見られます。これは、これらの代替案によって単純に例外機構を置き換えることができないことを示しています。
ただし、throwing values(P0709R4)はfibケースにおけるオーバーヘッドはかなり小さく、C++エミュの場合は25%、アセンブラ実装の場合は10%程度で済んでいます。失敗率が高くなると例外処理を上回り、マルチスレッド時のパフォーマンス劣化もありません。
throwing values(P0709R4)は、現在の例外機構の代替として非常に理想的なものですが、そのメカニズムを既存のコード、特に標準ライブラリに統合する方法が問題となります。新しいメカニズムを使用するためにソースの再コンパイルが必要という点は問題ではなく、ソースレベルの互換性をどう確保するかという点が問題となります。コンパイラフラグによる切り替え(例えば、stdからstd2への切り替えなど)はODR関連の問題を引き起こす可能性があり危険です。
したがって、例外機構代替の最善の戦略というものは現時点ではまだ明らかではありません。しかし、AMD/intelのCPUロードマップを見てもCPUコア数は今後確実に増加していくため、何か手を打つ必要があります。そうしなければ、例外を有効にすることによるパフォーマンス劣化を回避するために-fno-exceptionsとともに自前のソリューションを使用することが避けられなくなります。
P2545R0 Why RCU Should be in C++26
標準ライブラリにRead-Copy-Update(RCU)サポートを追加する提案。
これは現在Concurrency TS v2(未発行)に含まれているRCU関連のものをそのままC++26の標準ライブラリに含めようとする提案です。以前はP1122で議論されていたため、詳細はそちらの解説記事を参照してください。
基本的な主張は「P2530R0 Why Hazard Pointers should be in C++26」と同様で、FacebookのFollyというライブラリでこの提案のスーパーセットが実装され、実製品での使用経験があり、インターフェースは安定してるため、C++26に追加しようというものです。
参照カウンタ・ハザードポインタ・RCUの性質の比較。
| 性質 | Reference Counting | Hazard Pointers | RCU |
|---|---|---|---|
| リーダー(読み取り処理) | 遅くスケーラブルでない | 高速でスケーラブル | 高速でスケーラブル |
| 未回収オブジェクトの利用 | 制限あり | 制限あり | 制限なし |
| Traversal Retries? | オブジェクトが削除された場合 | オブジェクトが削除された場合 | しない |
| 回収にかかるレイテンシ | 高速 | 遅い | 遅い |
提案では、ハザードポインタは参照カウンタのスケーラブルな代替品であり、RCUはリーダー・ライターロックのスケラーブルな代替品であり、競合するものではないと述べられています。
P2546R0 Debugging Support
標準ライブラリにデバッグサポートの為のユーティリティを追加する提案。
この提案は、以前のP2514とP2515をマージした後継となるものです。
それぞれについては以前の記事を参照。
- P2514R0
std::breakpoint- [C++]WG21月次提案文書を眺める(2022年01月) - P2515R0
std::is_debugger_present- [C++]WG21月次提案文書を眺める(2022年01月)
この提案での変更は
std::breakpoint()の文言を変更して、デバッガの有無などの環境条件に左右されないようにした- デバッガが接続されている時だけブレークポイントを有効化する
std::breakpoint_if_debugging()の追加 - 機能テストマクロの追加
- 実装経験の拡充
std::is_debugger_present()が即時クエリであることを明記
などです。
P2547R0 Language support for customisable functions
カスタマイゼーションポイントの言語サポートの提案。
C++20のCPOと以前のADLベースカスタマイゼーションポイントの問題点についてはこちら
- [C++]カスタマイゼーションポイントオブジェクト(CPO)概論 - 地面を見下ろす少年の足蹴にされる私
- [C++] std::rangesの範囲アクセス関数(オブジェクト)の使いみち - 地面を見下ろす少年の足蹴にされる私
その上で、CPOには次のような問題がまだあります
- 定義のためのボイラープレートが多い
- 名前衝突の可能性がある
- 値で引数を渡した時、コピー省略されない
- CPOをラップして転送できるようなジェネリックラッパを書けない
コピー省略されないという問題は、CPOが引数を転送した上で内部で関数呼び出し行う2段階の関数呼び出しをしているために起きています。
// foo CPOの実体 namespace _foo { // Poison-pill オーバーロード void foo(); struct _fn { template<typename T, typename V> requires requires (T& obj, V&& value) { foo(obj, (V&&)value); } void operator()(T& obj, V&& value) const { foo(obj, (V&&)value); } }; } // foo CPOの定義 inline namespace _foo_cpo { inline constexpr _foo::_fn foo{}; } struct my_type { // foo CPOへのアダプト、stringを値で受け取る friend void foo(my_type& self, std::string value); }; void example() { my_type t; foo(t, std::string{"hello"}); // std::stringのムーブコンストラクタが1回呼ばれる }
my_type::foo()(Hidden friend関数)を直接呼び出した場合、2つ目の引数のstd::stringはコピー省略保証によって関数定義内で直接構築されるため、ムーブコンストラクタの呼び出しすら省略できます。しかし、CPOは引数を転送しているため(prvalueであることが忘れられることで)、それができません。
CPOの一部の問題を解決したアプローチとしてtag_invokeが提案されており、現在のP2300(Executor提案)はtag_invokeによるカスタマイゼーションポイントを多用しています。しかし、これにもまだ次のような問題があります
- CPOから
- 定義のためのボイラープレートが(まだ)多い
- 値で引数を渡した時、コピー省略されない
tag_invoke固有
P2279R0は、(上記のように)tag_invokeですらカスタマイゼーションポイントとして十分ではなく、理想的なカスタマイゼーションポイントのためには言語メカニズムが必要性であるとするものです。
この提案はそれに応えるもので、P2300で多用されているtag_invokeを置き換えるべく、P2300とともにC++26への導入を目指しています。
この提案では、既存のカスタマイゼーションポイントメカニズムに対して、次のような改善を行います
- 名前を広く予約することなく、カスタマイゼーションポイントを名前空間スコープに配置できる
- この提案の機能によって定義されるカスタマイゼーションポイントオブジェクト(CPO)を、汎用型消去ラッパや一部の操作をカスタマイズして他の操作を通過させるようなアダプタなどのラッパを通して、汎用的に転送できる
- CPOの定義と、それにアダプトする型にカスタマイズを追加する為の簡潔な構文
- カスタマイゼーションポイントに値として渡される引数のコピー省略サポート
tag_invokeと比較して、コンパイル時間が短縮される- 3層のテンプレートインスタンス化を回避し、実装関数を分離する為のSFINAEが不要になる
tag_invokeと比較して、エラーメッセージの改善tag_invokeはカスタマイゼーションポイントを区別しない(名前が全部tag_invokeになる)為、大量のオーバロードが発生しうる
これらのことを、次のような構文の導入によって達成します
- 名前空間スコープ関数宣言に対する
virtual指定による、カスタマイゼーションポイント関数の宣言- これを、Customisable Function Prototype(CFP)、あるいはCustomisable Functionと呼ぶ
= 0;で宣言することで、デフォルト実装を省略するdefault指定子付きでデフォルト実装を定義できる
- CFPの宣言は同名のCPOを導入する
- 特定のCFPにアダプトするためには、同名の関数を
override指定子付きで関数を定義する - 特定のCFPに対するアダプトを明示するために、CFPのフルスコープ名による関数定義構文
- ジェネリックな転送サポートのために、CFP(CPO)そのものを推論する機能
template <auto cpo, typename T> auto cpo(T&& object) override;のような構文
namespace std::execution { // execution::operation_state CFPの宣言 template<sender S, receiver R> virtual operation_state auto connect(S s, R r) = 0; }
CFPを宣言するには、名前空間スコープでvirtualで関数を宣言します。デフォルト実装が必要ない場合は最後に= 0;を付加します。これらの構文は、クラスの仮想関数と同様です。デフォルト実装が必要な場合は、default指定とともに定義します。
namespace std::ranges { // ranges::contains CFPの宣言およびデフォルト実装 template<input_range R, typename Value> requires equality_comparable_with<range_reference_t<R>, Value> virtual bool contains(R&& range, const Value& v) default { for (const auto& x : range) { if (x == v) return true; } return false; } }
このcontains()をカスタマイズするためには、override指定とともに同じ名前(スコープ名)で関数を定義します
namespace std { template<class Key, class Compare, class Allocator> class set { // ... private: // ranges::containsへのアダプト(カスタマイズ)、Hidden friend template<typename V> requires requires(const set& s, const V& v) { s.contains(v); } friend bool ranges::contains(const set& s, const V& v) override { return s.contains(v); } }; }
このカスタマイズは名前空間スコープ(クラス定義外)でも同様に行えます
namespace std { template<class Key, class Hash, class KeyEq, class Allocator> class unordered_set { ... }; // クラス定義外でのカスタマイズ template<class Key, class Hash, class Eq, class Allocator, class Value> requires(const unordered_set<Key,Hash,Eq, Allocator>& s, const Value& v) { s.contains(v); } bool ranges::contains(const unordered_set<K,H,Eq,A>& s, const Value& v) override { return s.contains(v); } }
このように宣言・定義されたCFPはフルスコープ名で普通に呼び出すことができ、引数に応じたカスタマイズを自動で(かつCPOのような2段階ディスパッチを行うことなく)解決してくれます
void example() { std::set<int> s = { 1, 2, 3, 4 }; for (int x : { 2, 5 }) { if (std::ranges::contains(s, x)) // std::setでカスタマイズされたものを呼び出す。 std::cout << x << " Found!\n"; } }
CFPはCPOと同様に、ADL以前の名前探索で見つかっているとADLを無効化します
void lookup_example() { std::set<int> s = { 1, 2, 3 }; contains(s, 2); // ADLによる探索が行われる // std::ranges::contains()は見つからない using std::ranges::contains; contains(s, 2); // containsの非修飾名探索でstd::ranges::contains()が見つかる // これはADLの代わりにCFPのオーバーロード解決ルールに従う }
CFPは同名のオブジェクトを導入しており、これは空のオブジェクトで値で渡すことができます(C++20 CPOと同様の性質を持つ)。このオブジェクトを関数呼び出しすると、対応するCFPのすべてのオーバーロードの集合から解決されます(すなわち、CFPを呼び出した時と同様の扱い)。
// frobnicate CFPの宣言 template<typename T> virtual void frobnicate(T& x) = 0; struct X { // frobnicateのカスタマイズ friend void frobnicate(X& x) override { ... } }; void example() { std::vector<X> xs = ...; std::ranges::for_each(xs, frobnicate); // "frobnicate"は対応するCFPの宣言に順じたCallabkeオブジェクトとして使用できる }
クラス内では、名前空間スコープの汎用カスタマイズ定義によって、CFPの集合全体に対してカスタマイズを定義することができます
// 特定のメンバ変数型を取得する template<typename Obj, typename Member> using member_t = decltype((std::declval<Obj>().*std::declval<Member Obj::*>())); // InnerでうけたCFPの呼び出し前にログ出力する template<typename Inner> struct logging_wrapper { Inner inner; // 呼び出されているCPO名を出力した後、Argsを使用してinnerで呼び出し可能なら // 最初の引数をlogging_wrapperとみなし、self.innerにargsを転送して呼び出す template<auto cpo, typename Self, typename... Args> requires std::derived_from<std::remove_cvref_t<Self>, logging_wrapper> && std::invocable<decltype(cpo), member_t<Self, Inner>, Args...> friend decltype(auto) cpo(Self&& self, Args&&... args) noexcept(/* ... */) override { std::print("Calling {}\n", typeid(cpo).name()); return cpo(std::forward<Self>(self).inner, std::forward<Args>(args)...); } }; void test(int x) { logging_wrapper log{ .inner = std::ranges::contains }; std::set<int> s = { 1, 2, 3, 4 }; std::ranges::contains(log, s, x); // logging_wrapperでカスタムされたcpo()を呼び出す // ログ出力後、std::ranges::contains(s, x);が呼び出される }
これ(logging_wrapperのcpo())は、非型テンプレートパラメータcpoを呼び出されたCFPに推論する事で可能となり、overrideキーワードがその目印となっています。
テンプレートなCFPは、明示的なテンプレートパラメータを使用して宣言することもできます(これを、template customisable functionと呼ぶ)。この場合、このテンプレートパラメータは明示的に与えられなければならず、CFPの特殊化それぞれに対して個別にCPOが作成されます。これは、std::getのようなカスタマイゼーションポイントを定義するのに使用できます
// CFPによるstd::getの実装例 namespace std { template<typename T, typename Obj> virtual auto get<T>(Obj&& obj) = 0; template<size_t N, typename Obj> virtual auto get<N>(Obj&& obj) = 0; template<size_t N, typename Obj> virtual auto get(Obj&& obj, std::integral_constant<size_t, N>) default -> decltype(auto) { return std::get<N>(std::forward<Obj>(obj); } } struct my_tuple { int x; float y; // 型名指定に対するカスタマイズ friend int& std::get<int>(my_tuple& self) noexcept override { return self.x; } friend float& std::get<float>(my_tuple& self) noexcept override { return self.y; } // インデックス指定に対するカスタマイズ friend int& std::get<0>(my_tuple& self) noexcept override { return self.x; } friend float& std::get<1>(my_tuple& self) noexcept override { return self.y; } };
変数や変数テンプレートと異なり、CFPの提供するCPOは比較可能ではないため、cpo-name<T>は明確にテンプレート名であり、<が比較演算子として認識されてしまうことはありません。これによって、CPOとCPO-templateは同じスコープに共存することができます。
P2279R0の比較軸に基づくと次のようになります
| 性質 | この提案 |
|---|---|
| Interface visible in code | ✔️ |
| Providing default implementations | ✔️ |
| Explicit opt-in | ✔️ |
| Diagnose incorrect opt-in | ✔️ |
| Easily invoke the customization | ✔️ |
| Verify implementation | ✔️ |
| Atomic grouping of functionality | ❌ |
| Non-intrusive | ✔️ |
| Associated Types | 🤷 |
| Customization Forwarding | ✔️ |
- Interface visible in code
- カスタマイズ可能な(あるいはその必要がある)インターフェース(関数など)がコードで明確に識別できる
- Providing default implementations
- デフォルト実装を提供し、なおかつオーバーライド可能
- Explicit opt-in
- インターフェースを明示的にオプトインできる(インターフェースへのアダプトが明示的)
- Diagnose incorrect opt-in
- インターフェースに意図せずアダプトしない
- Easily invoke the customization
- カスタマイズされたものを簡単に呼び出せる
- デフォルト実装がある場合、必ずカスタマイズされたものを呼び出す
- Verify implementation
- ある型がインターフェースを実装していることを簡単に確認できる(機能がある)
- Atomic grouping of functionality
- インターフェースにアダプトするために必要な最小の機能グループを提示でき、早期にそれを診断できる
- Non-intrusive
- 非侵入的(その型を所有していない人が後からカスタマイズできる)
- Associated Types
「Atomic grouping of functionality」および「Associated Types」に関しては意図的に含まれていません。それは、コンセプトを用いることによって解決することができ、組み合わせればRustのTraitsと同等の機能となります(提案中にはRustとの比較コードがあります)。また、この提案が将来的にそのような拡張をする余地をなくすものではないため、将来そのような方向性を探ることもできます。
P2549R0 std::unexpected should have error() as member accessor
std::unexpectedのエラー値取得関数をerror()という名前にする提案。
std::unexpected<E>はstd::expected<T, E>のEについてのラッパ型です。std::unexpected<E>はstd::expected<T, E>に暗黙変換することができ、主にstd::expectedを返すときにエラー値を返していることを明示するために使用します。
std::expected<int, std::errc> svtoi(std::string_view sv) { int value{0}; auto [ptr, ec] = std::from_chars(sv.begin(), sv.end(), value); if (ec == std::errc{}) { // 正常終了 return value; } // エラー return std::unexpected(ec); }
std::unexpected<E>を直接使用することはあまりなさそうですが、一応保持するEの値を取り出せるようになっており、それは.value()メンバ関数で行います。しかし、それをstd::expected<T, E>に変換するとその値は.error()で取り出すことができ、.value()は正常値Tを取り出す関数となります。このように、std::unexpected<E>の値アクセスはstd::expected<T, E>のものと矛盾しているため、std::unexpected<E>::value()をerror()にリネームするべき、という提案です。
P2550R0 ranges::copy should say output_iterator somewhere
ranges::copyをはじめとする出力系のアルゴリズムが、出力イテレータ型をoutput_iteratorという言葉を含むようなコンセプトで制約するようにする提案。
例えば、ranges::copyのイテレータペアを受け取るオーバーロードは次のように宣言されています。
template <input_iterator I, sentinel_for<I> S, weakly_incrementable O> requires indirectly_copyable<I, O> constexpr ranges::copy_result<I, O> ranges::copy(I first, S last, O result);
このうち出力操作を制約しているのはindirectly_copyableコンセプトで、それがイテレータっぽく使えることをweakly_incrementableが要求しています。とはいえ、この2つのコンセプトはoutput_iterator等よく知られた性質に比べると知名度がなく、診断(コンパイルエラーなど)に表示されてもあまり役立ちそうにありません。この提案は、これをoutput_iteratorという言葉を含むようなコンセプトに置き換えようとするものです。
単純には、output_iteratorを使用して次のように書き換えてしまえばこの問題は解決します。
template <input_iterator I, sentinel_for<I> S, output_iterator<iter_reference_t<I>> O> constexpr ranges::copy_result<I, O> ranges::copy(I first, S last, O result);
この二つの制約はoutput_iteratorに含まれている*i++ = std::forward<T>(t);(引数名を使って書くと、*result++ = *first;)という制約を除いて、同じことを制約しています。今日のranges::copy(およびその他出力系アルゴリズム)はこの構文を使用していないためこの要件を必要とせず、そのためoutput_iteratorを使用していません。
筆者の方の調査によれば、rangesの出力操作を行うアルゴリズムのうちoutput_iteratorを使用するのはranges::replace_copy, ranges::replace_copy_if, ranges::fill, ranges::fill_nの4種類だけだったようです。また、ranges::fill, ranges::generateの2つのrange型Rを受け取るオーバーロードではoutput_range<R>コンセプトが使用されていましたが、ranges::generateではイテレータペアに対して同様の制約がなされていなかったようです。
indirectly_copyable<I, O>コンセプトはIがindirectly_readableであり、Oがindirectly_writableであることを要求するもので、この2つを組み合わせただけのコンセプトです。出力系アルゴリズムでは、Iはすでにinput_iteratorで制約されており、ここにはindirectly_readable<I>がすでに含まれています。したがって、indirectly_copyable<I, O>はindirectly_writableに置き換えることができます。
template<input_iterator I, sentinel_for<I> S, weakly_incrementable O> requires indirectly_writable<O, iter_reference_t<I>> constexpr ranges::copy_result<I, O> ranges::copy(I first, S last, O result);
今は2022年であり、C++20に対する変更を行うには遅すぎます。そのため、output_iteratorコンセプトから*i++ = std::forward<T>(t);を取り除くことも、出力系アルゴリズムがoutput_iteratorを使用するように変更することもできません(後方互換を損ねるため)。この提案では、代わりにより弱いoutput_iteratorコンセプトを導入して、出力系アルゴリズムがそれを使うようにすることで、出力系アルゴリズムの出力イテレータに対する要件をoutput_iteratorという言葉を含んだ1つのコンセプトに統一することを提案しています。
ここまでの考察から、出力系アルゴリズムに必要なのはindirectly_writableであることと、既存の出力系アルゴリズムの制約がoutput_iteratorコンセプトと異なる点は*i++ = std::forward<T>(t);だけだということがわかっているので、これらの要件をまとめて最小のコンセプトに抽出したweak_output_iteratorコンセプトによってoutput_iteratorを書き直します
template<class I, class T> concept weak_output_iterator = input_or_output_iterator<I> && indirectly_writable<I, T>; template<class I, class T> concept output_iterator = weak_output_iterator<I, T> && requires(I i, T&& t) { *i++ = std::forward<T>(t); // not required to be equality-preserving };
weak_output_iteratorコンセプトは既存の出力系アルゴリズムの出力イテレータに対する制約と同等であり、かつoutput_iteratorという言葉を含んでいることで要求事項がより知名度のある概念によって表されています。これを用いて、ranges::copyは次のように書き直せます
template <input_iterator I, sentinel_for<I> S, weak_output_iterator<iter_reference_t<I>> O> constexpr ranges::copy_result<I, O> ranges::copy(I first, S last, O result);
この提案は、このweak_output_iteratorを追加しoutput_iteratorを書き換えた上で次のような変更を行います
weak_output_rangeコンセプトの新設とoutput_rangeコンセプトのそれを用いた変更mergeableコンセプトをweak_output_iteratorを使用するように変更- 全ての出力系アルゴリズムの出力操作に関する制約を
weak_output_iteratorを使用するように変更- ほとんどの場合は
weakly_incrementableとindirectly_writableを再指定するだけ(コンセプト名が変わるだけ) - 一部のアルゴリズムでは、
output_iteratorから変更されることで要件が弱まる(既存コードを壊すことはない)
- ほとんどの場合は
これによって、全ての出力系アルゴリズムではweak_output_iteratorコンセプトを出力操作の制約に一貫して使用するようになり、output_iteratorという言葉を表示するようになります。
P2551R0 Clarify intent of P1841 numeric traits
P1841R2で提案されている数値特性(numeric traits)取得ユーティリティについて、実装経験からの疑問点を報告する文書。
P1841の内容については以前の記事を参照。
この提案は、P1841の内容を実際に実装した経験より生じた、設計上の疑問点を報告するものです。
- ある数値型に対して、ある特性が無効となる(定義されない)のはどのような場合か?
- 現在の文言は、定数の表現が存在する場合は常に
valueを定義することを意図している - 文言は、動作の側面からそれが重要な役割を持つのかを明確にする必要がある
- 現在の文言は、定数の表現が存在する場合は常に
boolを数値型として扱い、特性を提供するのかを明確にすべき- 現在の文言は、
boolを数値型としてstd::numeric_limits<bool>と一致する特性を有効化している - 一般に、
boolは数値型として使用されない(コア言語では算術型扱いされているが)
- 現在の文言は、
- 数値特性のほとんどは浮動小数点数から来ており、整数型では意味をなさないものが多い。次の数値特性は整数型でも有効であることを意図しているか?
denorm_minepsilonnorm_minreciprocal_overflow_thresholdround_errormax_exponentmax_exponent10min_exponentmin_exponent10
reciprocal_overflow_threshold(T(1)/xがオーバーフローしない最も小さいTの正の値)の値はIEC559の型について、非正規化数をゼロとして扱う場合にどのように変化するか?- ハードウェアが非正規化数を0として扱う場合、
1/0 -> infとなりオーバーフローする。この場合は規定と一致しない。 - この特性は実行時のプロセッサの状態に依存することがあり、その場合コンパイル時定数として正しい値は何か?
- ハードウェアが非正規化数を0として扱う場合、
numeric_limits::max_digits10は整数型では0となる。対応するmax_digits10_v<int>はdigits10_v<int> + 1を返すべきか?浮動小数点数型に限定されるべきか?
この提案では、これらのことに関連した投票をLEWGで行い設計を決定するための投票項目のリストも記載しています。
P2552R0 On the ignorability of standard attributes
属性を無視できるという概念について、定義し直す提案。
新しい属性や属性likeな構文が提案される際には、ほぼ確実に不明な属性が無視可能であるという性質に言及がなされます。しかし、その性質については明文化されておらず、それが正確にどういう意味を持つのかについての一般的な理解はなく、現在ある種の紳士協定の上に成り立っているようです。
例えば、[[fallthrough(42)]]のような正しくない属性指定を無視するべきでしょうか?これはコンパイルエラーとするべきです(全ての主要なコンパイラはエラーとします)。このことは、属性は「無視できる」というよりも「属性を含めてプログラムがwell-definedであるならば、属性を無視してもプログラムの観測可能な振る舞いは変化しないはず」という性質を持っている事を示唆しています。例えば、ある実装が[[no_unique_address]]を実装していれば型のレイアウトが変更可能であるので、その効果は明らかに観測可能です(すなわち、無視できない)。
この提案は、このような属性の無視可能という性質についてその意味を明確に定義し規定しようとするものです。それによって、将来的に新規構文を属性とするべきか否かを判断する際の一助となるはずです。また、属性はC(C23)とC++の共通する機能であり、Cには標準属性の共通セマンティクスについての明確な規定があるため、その互換性を保つようにすることも意識しています。
この提案では、次のような「無視可能性」規定を追加する事を提案しています
well-definedな振る舞いをするwell-formedなプログラムは、特定の標準属性の全ての出現を省略すると、全ての観測可能な振る舞いが元のプログラムの正しい実行と一致するwell-formedなプログラムとなる。
このルールを適用するには、プログラムが属性を使用した上でwell-formedである必要があります。したがって、ill-formedな標準属性([[fallthrough(42)]]など)を無視できません。言い換えると、属性はそれ自体がwell-definedである場合、つまり属性が許可されている場所に正しい構文で現れている場合にのみ上記ルールによって無視可能となります。
例えば、[[maybe_unused]]や[[nodiscard]]は無視されてもされなくてもプログラムの観測可能な振る舞いに影響を与えないため、コンパイラはいつでも無視することが許可されます。[[no_unique_address]]は観測可能な振る舞いに影響を与えるため実装済みのコンパイラでは無視できず、未実装のコンパイラではそれは効果を持たないため観測可能な振る舞いに影響を与えず、無視することができます。
一方で、このルールを適用するためにはプログラムがその属性によって未定義動作をしないようにしなければなりません。つまり、属性の使用によって未定義動作を導入することは許可されますが、属性の削除(無視)によって未定義動作が導入されるのは許可されません。これは[[noreturn]]や[[assume(expr)]]などを許可する一方で、未定義動作を取り除くような属性(現在はない)が許可されない事を意味します。
P2553R0 Make mdspan size_type controllable
P0009で提案中のstd::mdspanについて、そのsize_typeを制御可能とする提案。
std::mdspanのsize_typeはExtentsテンプレートパラメータのsize_typeから継承されるもので、Extents<Is...>はmdspanの次元と要素数を指定するものです(sizeof...(Is)で次元を、各Isの値で要素数を指定)。そして、Extents::size_typeはその要素数を指定する値の型です。
Extents<Is...>::size_typeはstd::mdspanのレイアウトマッピングクラスでまで伝播し、レイアウトマッピングの処理において各Isの値が使用されることになります。例えば2次元配列なら、std::mdspan<double, std::extents<Width, Height>>のように指定し(Extentsはstd::extents<Width, Height>)、レイアウトマッピングクラスでは、インデックス(x, y)に対してi = y * Width + xのようなインデックス計算が行われます。
ここで問題となるのは、std::extents::size_typeの型がsize_t(多くの環境で64bit符号なし整数)に固定されていることで、これによって、64bit整数による計算が32bit整数の計算よりも遅い環境でパフォーマンス低下の原因となります。そのような環境には現在の多くのGPUが当てはまり、GPUでは32bit整数の64bit整数に対するパフォーマンス比は2~4倍(高速)である事が多いです。そして、mdspanはGPUが使用されることが多いHPCや機械学習、グラフィックスにおいて使用されることを想定しています。
この提案は、GPU等mdspanの主戦場でパフォーマンス低下を防ぐために、mdspan(ひいてはExtents)のsize_typeをユーザーが指定できるようにしようとするものです。
提案では、CUDAでmdspan(のリファレンス実装)を使用して3次元ステンシル計算を行うコードでループインデックスの型を変更したときのベンチマークを取っています。
// mdspan for(size_t i = blockIdx.x+d; i < s.extent(0)-d; i += gridDim.x) { for(size_t j = threadIdx.z+d; j < s.extent(1)-d; j += blockDim.z) { for(size_t k = threadIdx.y+d; k < s.extent(2)-d; k += blockDim.y) { value_type sum_local = 0; for(size_t di = i-d; di < i+d+1; di++) { for(size_t dj = j-d; dj < j+d+1; dj++) { for(size_t dk = k-d; dk < k+d+1; dk++) { sum_local += s(di, dj, dk); // インデックス計算が必要になるところ }}} o(i,j,k) = sum_local; // インデックス計算が必要になるところ } } } // 生ポインタ for(size_t i = blockIdx.x+d; i < x-d; i += gridDim.x) { for(size_t j = threadIdx.z+d; j < y-d; j += blockDim.z) { for(size_t k = threadIdx.y+d; k < z-d; k += blockDim.y) { value_type sum_local = 0; for(size_t di = i-d; di < i+d+1; di++) { for(size_t dj = j-d; dj < j+d+1; dj++) { for(size_t dk = k-d; dk < k+d+1; dk++) { sum_local += data[dk + dj*z + di*z*y]; // インデックス計算が必要になるところ }}} data_o[k + j*z + i*z*y] = sum_local; // インデックス計算が必要になるところ } } }
この例ではループインデックスの型をsize_tにしていますが、計測ではこれをunsigned(32bit符号なし整数)にした時とsize_tにした時で比較したところ、生ポインタの場合もmdspanの場合もunsigned : 31ms、size_t : : 56msのような結果が得られたようです。
また、ループインデックス型をsize_tのままでmdspanの要素アクセス()内でのインデックス計算において、extents.extent(r)(次元ごとの要素数取得)をunsignedにキャストするようにしたときでも、31msという結果が得られたようです。
使用したGPUについて記載はありませんが、この結果はExtents::size_typeをsize_tに固定するとパフォーマンス低下が起こる環境がある事を示しています。
mdspanにExtents::size_typeを指定する方法はいくつか考えることができます
std::extents<Is...>の各Isのcommon_typeをsize_typeとして取得する- (レイアウトにも依存する)オーバーフローの検知が困難
std::extentsがsize_typeを取るようにするstd::extentsを変更せず、size_typeとextentを受け取るbasic_extentsを導入する-
std::extentsはbasic_extentsのエイリアスとなる - Extent型とその値を推論するような関数テンプレートでの使用ができなくなる
-
- レイアウトポリシークラスが
size_typeを取るようにして、extent値をキャストする- オブジェクトのサイズが大きくなり、追加のキャストが必要となる
筆者の方は3番目の方法を推奨し、提案しています。
また、これは後から修正できないことからC++23に向けた提案としています。std::extentsをエイリアステンプレートとしてしまうと次のような推論ができなくなり、後方互換を損ねることから3番の変更は不可能となります。
// std::extentsが単一のクラス型である現在はこれが可能 template<class T, class L, class A, size_t ... Extents> void foo(std::mdspan<T, std::extents<Extents...>, L, A> a) { // ... }
P2554R0 C-Array Interoperability of MDSpan
生配列からのmdspan構築時に、その要素数に関する情報が失われてしまうのを修正する提案。
現在のmdspanでは、生配列を参照する際にポインタとして扱ってしまうことから、その要素数の静的な情報が伝わらない問題があります。
int a[6] = {1,2,3,4,5,6}; // 1次元配列からの構築 std::mdspan b(a); static_assert(decltype(b)::rank()==0); // 何も参照しないmdspanができている
この提案は、これを修正し次のように正しく情報が伝播するようにするものです。
{
int a[6] = {1,2,3,4,5,6};
std::mdspan b(a);
static_assert(decltype(b)::rank()==1);
static_assert(decltype(b)::static_extent(0)==6);
}
{
int a[6] = {1,2,3,4,5,6};
std::mdspan b(a,3);
static_assert(decltype(b)::rank()==1);
static_assert(decltype(b)::static_extent(0)==dynamic_extent;
// b.extent(0)==3
}
{
int a[6] = {1,2,3,4,5,6};
std::mdspan<int, std::extents<3>> b(a);
static_assert(decltype(b)::rank()==1);
static_assert(decltype(b)::static_extent(0)==3;
}
この問題は、現在のmdspanのコンストラクタおよび推論補助が生配列をポインタに変換(decay)して扱うために起こっています。そこでこの提案では、mdspanのコンストラクタと推論補助に生配列用のものを追加したうえで、制約によって単にポインタが渡された時に選択されないようにすることで、1次元配列からの構築時にその要素数が静的に伝達されるように修正しています。
また、別の問題として、mdspanは多次元配列からの構築ができないようにされています。これは、多次元配列をその要素型のポインタから操作することはUBとなるためそれを禁止するもので、ユーザーにとっては意外なことかもしれませんが正当な仕様です・
int a[3][2] = {1,2,3,4,5,6}; std::mdspan<int, std::dextents<2>> b(a,3,2); // error! std::mdspan<int, std::extents<3,2>> c(a); // error!
ただし、このことは実際には少なくとも2つのコンパイラ(GCCとclang)で正しく動作しているようです。この提案ではこの問題の解決を含めてはいませんが、コア言語の変更によってUBとならなくすることで多次元配列でもmdspanを動作させることができるとしています。
P2555R0 Naming improvements for std::execution
P2300で提案されている、senderファクトリ及びsenderアダプタの一部のものについて、名前を改善する提案。
P2300のsender/receiverは3つのチャネルを使用して値やエラー、キャンセルなどの情報をやり取りします。あるsenderアルゴリズムの操作がそれら3つのチャネルすべてで使用可能である場合、一貫した方法で特定のチャネルを呼び出すようにすべきです。その時、valueチャネルがデフォルトであり明示的に名前を付ける必要が無いと考えられる場合は常に名前を付けるべきではありません。
現在のP2300の命名においては常にチャネル名を明示する方向性に見えますが、just/just_error/just_stopped(senderチェーンの起点として各チャネルのシグナルを挿入する)とlet_value/let_error/let_stopped(senderチェーンの途中で各チャネルのシグナルを挿入する)を比較すると矛盾していることが分かります。
また、thenのファミリ(各チャネルの継続をチェーンする、あるいは各チャネルの値を変換する)の場合はthen/upon_error/upon_stoppedとなっており、ここでも矛盾が見られます。
この提案は、これらの名前付けについて次の2つの事を提案するものです
just, just_error/just_stoppedをset_value/set_error/set_stoppedへ変更upon_error/upon_stoppedをthen_error/then_stoppedへ変更することを検討する
また、let_*系の操作についてもforkやspawnといった呼び方が好まれているように見える、transfer_justやtransfer_when_allなどの複合操作は実装の最適化として残した方がよい、などの事も書いていますが、P2300に関する経験の不足からこれらの事については提案していません。
P2557R0 WG21 2022-02 Virtual Meeting Record of Discussion
2022年2月7日(北米時間)に行われたWG21全体会議の議事録。
各投票においての発言などが記録されています。