文書の一覧
SG22のWG14からのものを除いて、全部で84本あります。
- N4928 Working Draft, Standard for Programming Language C++
- N4929 Editors' Report - Programming Languages - C++
- N4933 WG21 November 2022 Kona Minutes of Meeting
- N4934 2023 WG21 admin telecon meetings
- N4935 2023 Varna Meeting Invitation and Information
- N4936 2023-11 Kona meeting information
- N4937 Programming Languages — C++ Extensions for Library Fundamentals, Version 3
- N4939 Working Draft, C++ Extensions for Library Fundamentals, Version 3
- N4938 Editor's Report: C++ Extensions for Library Fundamentals, Version 3
- P0260R5 C++ Concurrent Queues
- P0342R1 What does "current time" mean?
- P0792R12 function_ref: a non-owning reference to a Callable
- P1383R1 More constexpr for <cmath> and <complex>
- P1673R11 A free function linear algebra interface based on the BLAS
- P1684R4 mdarray: An Owning Multidimensional Array Analog of mdspan
- P1883R2 file_handle and mapped_file_handle
- P1928R2 Merge data-parallel types from the Parallelism TS 2
- P1967R10 #embed - a simple, scannable preprocessor-based resource acquisition method
- P2013R5 Freestanding Language: Optional ::operator new
- P2047R5 An allocator-aware optional type
- P2075R2 Philox as an extension of the C++ RNG engines
- P2164R9 views::enumerate
- P2169R3 A Nice Placeholder With No Name
- P2198R6 Freestanding Feature-Test Macros and Implementation-Defined Extensions
- P2198R7 Freestanding Feature-Test Macros and Implementation-Defined Extensions
- P2338R3 Freestanding Library: Character primitives and the C library
- P2363R4 Extending associative containers with the remaining heterogeneous overloads
- P2406R1 Fix counted_iterator interaction with input iterators
- P2406R2 Add lazy_counted_iterator
- P2407R2 Freestanding Library: Partial Classes
- P2508R2 Exposing std::basic-format-string
- P2530R2 Why Hazard Pointers should be in C++26
- P2537R2 Relax va_start Requirements to Match C
- P2545R2 Why RCU Should be in C++26
- P2570R2 Contract predicates that are not predicates
- P2591R2 Concatenation of strings and string views
- P2616R3 Making std::atomic notification/wait operations usable in more situations
- P2630R2 Submdspan
- P2636R2 References to ranges should always be viewable
- P2642R2 Padded mdspan layouts
- P2656R1 C++ Ecosystem International Standard
- P2659R2 A Proposal to Publish a Technical Specification for Contracts
- P2675R1 LWG3780: The Paper (format's width estimation is too approximate and not forward compatible)
- P2677R2 Reconsidering concepts in-place syntax
- P2680R1 Contracts for C++: Prioritizing Safety
- P2689R1 atomic_accessor
- P2700R1 Questions on P2680 "Contracts for C++: Prioritizing Safety"
- P2713R0 Escaping improvements in std::format
- P2713R1 Escaping improvements in std::format
- P2714R0 Bind front and back to NTTP callables
- P2717R0 Tool Introspection
- P2723R1 Zero-initialize objects of automatic storage duration
- P2724R0 constant dangling
- P2725R1 std::integral_constant Literals
- P2728R0 Unicode in the Library, Part 1: UTF Transcoding
- P2729R0 Unicode in the Library, Part 2: Normalization
- P2730R0 variable scope
- P2732R0 WG21 November 2022 Kona meeting Record of Discussion
- P2733R0 Fix handling of empty specifiers in std::format
- P2734R0 Adding the new 2022 SI prefixes
- P2736R0 Referencing the Unicode Standard
- P2737R0 Proposal of Condition-centric Contracts Syntax
- P2738R0 constexpr cast from void*: towards constexpr type-erasure
- P2739R0 A call to action: Think seriously about "safety" then do something sensible about it
- P2740R0 Simpler implicit dangling resolution
- P2741R0 user-generated static_assert messages
- P2742R0 indirect dangling identification
- P2743R0 Contracts for C++: Prioritizing Safety - Presentation slides of P2680R0
- P2746R0 Deprecate and Replace Fenv Rounding Modes
- P2747R0 Limited support for constexpr void*
- P2748R0 Disallow Binding a Returned glvalue to a Temporary
- P2750R0 C Dangling Reduction
- P2751R0 Evaluation of Checked Contracts
- P2752R0 Static storage for braced initializers
- P2756R0 Proposal of Simple Contract Side Effect Semantics
- P2757R0 Type checking format args
- P2758R0 Emitting messages at compile time
- P2759R0 DG Opinion on Safety for ISO C++
- P2762R0 Sender/Receiver Interface For Networking
- P2763R0 layout_stride static extents default constructor fix
- P2764R0 SG14: Low Latency/Games/Embedded/Finance/Simulation virtual meeting minutes 2023/01/11
- P2765R0 SG19: Machine Learning Virtual Meeting Minutes 2022/12/08-2023/01/12
- P2766R0 SG16: Unicode meeting summaries 2022-10-12 through 2022-12-14
- P2769R0 get_element customization point object
- おわり
N4928 Working Draft, Standard for Programming Language C++
N4929 Editors' Report - Programming Languages - C++
↑の変更点をまとめた文書。
11月のKona会議で採択された提案とコア言語/ライブラリのIssue解決が適用されています。
N4933 WG21 November 2022 Kona Minutes of Meeting
2022年11月7-12日にハワイのKonaで行われた、WG21全体会議の議事録。
開催期間中の各グループの活動報告や、CWG/LWG/LEWGの投票の様子などが記載されています。
N4934 2023 WG21 admin telecon meetings
2023年(今年)のWG21管理者ミーティングの予定表。
N4935 2023 Varna Meeting Invitation and Information
2023年6月にブルガリアのヴェルナで開催される予定のWG21全体会議のインフォーメーション。
主に開催場所やその注意点などが記載されています。
N4936 2023-11 Kona meeting information
2023年11月にハワイのKonaで開催される予定のWG21全体会議のインフォーメーション。
同上。
N4937 Programming Languages — C++ Extensions for Library Fundamentals, Version 3
次期標準ライブラリ機能候補の実装経験を得るためのTSである、Library Fundamental TS v3のFDIS。
N4939 Working Draft, C++ Extensions for Library Fundamentals, Version 3
次期標準ライブラリ機能候補の実装経験を得るためのTSである、Library Fundamental TS v3のドラフト文書。
おそらく内容はN4937と同一です。
N4938 Editor's Report: C++ Extensions for Library Fundamentals, Version 3
↑の変更点を記した文書。
この版での変更は、typoの修正などです。
P0260R5 C++ Concurrent Queues
標準ライブラリに並行キューを追加するための設計を練る提案。
キューはシステムコンポーネント間のデータのやり取りの方法を提供する基礎的なものです。現在のC++標準ライブラリにもstd::dequeなどが用意されていますが、それらは全てシーケンシャルなデータ構造であり、その要素アクセスとキューの操作を並行に行うことができません。そのため、並行キューを導入するためには、それらとは別のものが必要となります。
さらに、並行性の要求はパフォーマンスとそのセマンティクスに新たな評価軸を追加し、並行キューにおいては競合しない操作のコスト、競合する操作のコスト、要素の順序保証をトレードオフにする必要があり、これによって既存のキューよりもセマンティクスが弱くなります。
そのような対立軸にはたとえば
などがあります。
この提案は今の所、そのような並行キューのインターフェースのベースとなる概念的なインターフェースの要件を定義しています。
基本操作
並行キューイングの問題に対する本質的な解決策は、参照ベースではなく値ベースの操作へ移行することです。そのために次の2種類の基本操作を定義しています
// 要素をキューイングする void queue::push(const Element&); void queue::push(Element&&); // 要素をキューから取り出す // 要素はコピーではなくムーブされる void queue::pop(Element&);
ここでのqueueは特定のキューを示すものではなく、コンセプト的なプレースホルダです。
これらの操作はまたブロッキングを伴う操作でもあり、キューが満杯/空の場合に待機し、操作の競合を回避するためにブロックされる可能性があります。
即時操作
満杯/空のキューで待機すると操作が完了するまでにしばらく時間を要する可能性があり、機会費用がかかります。この待ち時間を回避することで、満杯/空のキューで操作の完了を待機する代わりに他の作業を行うことができます。そのために、次の2種類の即時操作(待機しない操作)を定義しています
// キューが満杯/クローズ状態の場合はその状態を返し、そうではない場合にキューイングしqueue_op_status::successを返す queue_op_status queue::try_push(const Element&); // キューが満杯/クローズ状態の場合はその状態を返し、第一引数を第二引数へムーブする // そうではない場合にキューイングしqueue_op_status::successを返す queue_op_status queue::try_push(Element&&, Element&); // キューが空ならqueue_op_status::emptyを返し // そうではない場合に要素をキューから取り出し(コピーではなくムーブされる)、queue_op_status::successを返す queue_op_status queue::try_pop(Element&);
queue_op_statusは次のようなスコープ付き列挙型です
enum class queue_op_status { success, empty, full, closed };
これらの操作はキューが満杯/空の場合にブロックしませんが、操作の競合を回避するためにブロックされる可能性があります。
キューのクローズ
通信にキューを使用しているスレッドでは、キューが不要になった場合にそのキューを使用している他のスレッドにそのことを通知するメカニズムが必要になる場合があります。典型的には、それはキューとは別の条件変数やアトミック変数などの帯域外信号が使用されます。ただし、このアプローチでは、そのキューで待機している他のスレッドを起床しなければならない問題があり、そのためにキューの満杯/空のブロッキングに使用される条件変数にアクセスする必要が出てくるなど、インターフェースの複雑さと危険性を増大させます。また、ミューテックスやアトミック変数を使用することでパフォーマンスに影響が及ぶ可能性もあります。
そのため、この提案ではそのようなシグナルをキュー自体でサポートすることを選択しており、これによってコーディングがかなり簡素化されます。
このシグナルのために、キューはクローズ(close())を行うことができます。あるスレッドでキューがクローズされると新しい要素をそのキューに挿入(push)することができなくなります。クローズ済キューに対する挿入操作はqueue_op_status::closedを返すか例外としてスローします。キューに存在する要素は取り出し(pop)が可能ですが、キューが空でクローズされている場合、取り出し操作はqueue_op_status::closedを返すか例外としてスローします。
// キューを閉じる void queue::close() noexcept; // キューが閉じられていればtrueを返す bool queue::is_closed() const noexcept; // キューが閉じられていればqueue_op_status::closedを返す // そうでないならば、要素をキューイングする queue_op_status queue::wait_push(const Element&); queue_op_status queue::wait_push(Element&&); // キューが空で閉じられていればqueue_op_status::closedを返す // そうではなく、キューが空ならばqueue_op_status::emptyを返す // それ以外の場合、キューから要素を取り出しqueue_op_status::successを返す queue_op_status queue::wait_pop(Element&);
wait_とあるpush/pop操作は、キューが閉じられている場合に例外を回避するためのインターフェースです。この操作はキューが閉じられておらず満杯/空の場合に待機し、操作の競合を回避するためにブロックされる可能性があります。
クローズ後のキューを再開したいユースケースがあり、この提案ではそのためのインターフェースも定義しています
// キューをオープンする void queue::open();
キューを再開する機能が困難になる実装は現在把握されてはいませんが、存在する可能性があります。また、キューの再開は通常キューが閉じていて空の場合にのみ呼び出すことができ、これによってクリーンな同期ポイントを提供することができます。ただし、空でないキューでopen()を呼び出すことは可能です。
is_closed()がfalseを返す場合でも、他のスレッドがキューを同時にクローズする可能性があるため、後続の操作でキューが閉じられている保証はありません。
オープン操作が利用できない場合、キューが閉じられるとキューは閉じたままになるという保証があります。したがってその場合、プログラマが他のすべてのスレッドがキューを閉じないように細心の注意を払わない限りは、is_closed()の戻り値はtrueのみが意味を持ちます。
キューの再開にはこれらの問題があるため、この提案ではこのインターフェースを提示するにとどめ提案していません。
要素型の要件
上記の操作のためには、要素型にはコピー/ムーブコンストラクタ、コピー/ムーブ代入演算子、及びデストラクタが必要になります。
コンストラクタと代入演算子は例外を投げる可能性がありますが、後続の操作のためにはオブジェクトを有効な状態のままにしておく必要があります。
例外ハンドリング
基本操作の2つの操作(push()/pop())はキューの状態によって例外を投げる可能性があります。その例外オブジェクトはstd::exceptionの派生クラスであり、queue_op_stateの値を含んでいる必要があります。
他のスレッドがキューの状態を監視している時に変更を透過的に元に戻すことができないため、並行キューは要素型がスローした例外の影響を完全に隠すことはできません。そのような例外は要素型のコピー/ムーブコンストラクタ及びコピー/ムーブ代入演算子から投げられる可能性があります。
それ以外の場合、キューは、メモリ確保、ミューテックス、条件変数から例外を再スローする可能性があります。
要素のコピー/ムーブが例外を投げる可能性がある場合、一部のキュー操作には追加の動作が定義されています
- 構築時は例外を再スローし、構築しようとしていた要素を破棄する
- 挿入操作は再スローし、キューの状態は変化しない
- 取り出し操作は再スローし、取り出そうとしていた要素はキューから取り除かれる(要素は実質的に失われる)
この提案ではこれらの要件に沿った具体的なキューを提案してはいませんが、P1958R0でその一つであるbuffer_queueが提案されている他、google-concurrency-libraryにこの提案の初期のインターフェースをベースとした実装があります。
この提案は、フィードバックを得るためにConcurrency TS v2入りを目指しています。
P0342R1 What does "current time" mean?
<chrono>の時計型のnow()が最適化によって並べ替えられないようにする提案。
<chrono>の時計型(steady_clockなど)はその静的メンバ関数now()によってその時計の示す現在の時刻(current point in time)を取得することができます。しかし、この現在の時刻が何を指すのか不明瞭であり、必ずしもコードに記述した実行地点での現在時刻を取得しないことがあります。
提案より、サンプルコード
#include <chrono> #include <atomic> #include <iostream> std::size_t fib(std::size_t n) { if (n == 0) return n; if (n == 1) return 1; return fib(n - 1) + fib(n - 2); } int const which{42}; int main() { // fib()の実行にかかる時間を計測する auto start = std::chrono::high_resolution_clock::now(); // #1 auto result = fib(which); // #2 auto end = std::chrono::high_resolution_clock::now(); // #3 std::cout << "fib(" << which << ") is " << result << std::endl; std::cout << "Elapsed time is " << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << "ms" << endl; return 0; }
このようなコードはかなり基本的なものですが、少なくともMSVCは最適化を有効にすると#2 #3の順番を入れ替えて、#1 -> #3 -> #2のように実行してしまい、結果0msが出力されます。このような最適化は標準の範囲内で許可されているため、この最適化自体は合法です。
これはシングルスレッドプログラムにおける実行順序の並べ替えであるため、標準の範囲内で回避するのは難しいようです。ファイルを分割することで回避できるようですが、それもプログラム全体の最適化やリンク時最適化を考慮すると確実なものとは言えません。また、この問題はコンパイラによっては起こらないかもしれず、回避策を含めたこのようなコードの移植性を損ねています。
プログラム中で現在のタイムスタンプを取得するという単純な処理にすらこのような罠が潜んでいて回避が難しいというのは大きな問題であり、この提案はその改善のためのものです。
この提案ではこの問題の解決のためにいくつかの方法を挙げています
- 標準を変更はしないが、ガイダンスを充実させる
- SG20で配布可能なガイダンスを作成するだけでも教育者には大きな助けになる
- 編集上の変更を加える
- ↑のガイダンスを標準に記述する
now()の並べ替えを禁止する- このアプローチはR0の議論において実装可能性について懸念があった
- シングルスレッドフェンスを導入する
- この問題が発生するのは時刻取得に止まらないと考えられるため、このユースケースに応えるためにより一般的なソリューションを提供する
- このアプローチはR0で提案していたものだったが、実装可能性について懸念があった
ただし、現在のところどれかを選択してはいません。
この提案のR0ではこの問題の解決のためのシングルスレッドフェンスを提案していましたが、2016年にレビューされた際にはその実装可能性の懸念などから受け入れられず、提案の追求はストップしていました。しかし、2022年のKona会議におけるSG1のミーティング中にこの問題が取り上げられ、この提案の改訂版が望まれたことで、とりあえず問題を整理したR1(このリビジョン)が再度提出されました。
著者の方やSG1のメンバは、現在の時刻の取得という単純なタスクでプログラマが直面するこの問題は、現状の改善をより広く検討するのに十分に深刻だと考えているようです。
P0792R12 function_ref: a non-owning reference to a Callable
Callableを所有しないstd::functionであるstd::function_refの提案。
以前の記事を参照
- P0792R6 function_ref: a non-owning reference to a Callable - [C++]WG21月次提案文書を眺める(2022年01月)
- P0792R8 function_ref: a non-owning reference to a Callable - [C++]WG21月次提案文書を眺める(2022年02月)
- P0792R9 function_ref: a non-owning reference to a Callable - [C++]WG21月次提案文書を眺める(2022年05月)
- P0792R10 function_ref: a non-owning reference to a Callable - [C++]WG21月次提案文書を眺める(2022年06月)
- P0792R11 function_ref: a non-owning reference to a Callable - [C++]WG21月次提案文書を眺める(2022年09月)
このリビジョンでの変更は、LWGのフィードバックによる文言の調整と、メンバ変数ポインタを誤って処理していた推論補助の修正です。
この提案は次のリビジョン(未公開)がLWGのレビューをパスして、次の全体会議にかけられることが決まっています(C++26ターゲットです)。
P1383R1 More constexpr for <cmath> and <complex>
<cmath>と<complex>の数学関数をconstexprにする提案。
<cmath>の数学関数をはじめとする浮動小数点数を扱うものをconstexpr対応させるにあたって問題となっているのは、同じ浮動小数点数値に対するある関数の結果がコンパイラの設定やプラットフォーム、実行タイミング等のコンテキストによって等しい必要があるのか?という点です。明らかにそうなって欲しいのですが、浮動小数点数の特性などの事情によってそれは実際には困難であり、そうするとそれら関数の実行結果についてどのように規定するのか、あるいはどのような保証を与えるのか?が問題となります。
C++23におけるP0533R9による<cmath>等の関数のconstexpr対応にあたってもそのような問題の議論を回避するために、四則演算(+ - * /)よりも(その事情の下では)複雑でないとみなされる関数のみがconstexpr対応されました。
この提案は次のような設計指針によって、<cmath>と<complex>にあるほぼすべての数学関数をconstexpr対応させようとしています
- 数学関数の実行結果が実行時とコンパイル時で異なることを許容する
- 数学関数の定数実行が異なるプラットフォームで異なることを許容する
<cmath>内の既存関数に正確な動作を義務付けるのではなく、QoIの定量化を奨励することが望ましい
そもそも実行時における現在の<cmath>の数学関数や浮動小数点演算は、異なるコンパイラやプラットフォームの間、あるいは異なるコンパイラオプション(-ffast-mathなど)の間で結果が一致しないことは長い間許容されています。また、定数式では数学関数を呼び出さない浮動小数点演算は可能であり、規格も利用者もその結果の実行時とコンパイル時の差異を許容しています(実行時における丸めモードの変更やFMAの利用など)。
costexprな数学関数にのみ過剰な正確性や結果の一貫性を要求することは、実装の困難さを高めるとともにそれそのものが実行時とコンパイル時の出力差の原因となります。そのためこの提案では、許容されている現在の実行時の振る舞いをベースとした設計指針によって数学関数をconstexpr対応させる方針を押しています。
P1673R11 A free function linear algebra interface based on the BLAS
標準ライブラリに、BLASをベースとした密行列のための線形代数ライブラリを追加する提案。
以前の記事を参照
- P1673R3 A free function linear algebra interface based on the BLAS - [C++]WG21月次提案文書を眺める(2021年04月)
- P1673R4 A free function linear algebra interface based on the BLAS - [C++]WG21月次提案文書を眺める(2021年08月)
- P1673R5 A free function linear algebra interface based on the BLAS - [C++]WG21月次提案文書を眺める(2021年10月)
- P1673R6 A free function linear algebra interface based on the BLAS - [C++]WG21月次提案文書を眺める(2021年12月)
- P1673R7 A free function linear algebra interface based on the BLAS - [C++]WG21月次提案文書を眺める(2022年04月)
- P1673R8 A free function linear algebra interface based on the BLAS - [C++]WG21月次提案文書を眺める(2022年05月)
- P1673R9 A free function linear algebra interface based on the BLAS - [C++]WG21月次提案文書を眺める(2022年06月)
- P1673R10 A free function linear algebra interface based on the BLAS - [C++]WG21月次提案文書を眺める(2022年10月)
このリビジョンでの変更は
in_{vector,matrix,object}*_tがユニークなレイアウトを持つという要件を削除in_{vector,matrix,object}*_tに対する名前付き要件を説明専用コンセプトに変更- 対称なHermitian updateアルゴリズムを制約するために、説明専用コンセプト
possibly-packed-inout-matrixを追加 - 新しい説明専用コンセプトと重複する制約を削除
- 全てのアルゴリズムの制約から、
mdspanがユニークなレイアウトを持つという制約を削除 - ベクトル/行列オブジェクトのテンプレートパラメータが
mdspanへのconst左辺値参照もしくは非const右辺値参照を推論する可能性があるという要件を削除 - 両方のベクタ型を含めるように
dotの要件を修正 mdspanのelement_typeエイリアスの代わりにvalue_typeエイリアスを使用するように、いくつかの関数の規定を修正matrix_vector_productのテンプレートパラメータ順序と仮引数の順序を合わせた- LEWGのガイダンスに従って、効果と制約を数学的に記述するようにした
matrix_one_normの事前条件(要素のabs()の結果がTに変換可能であること)を制約に変更vector_abs_sumの事前条件(init + abs(v[i])の結果がTに変換可能であること)を制約に変更- Bikeshedの代わりにPandocを使用するようにした
conjugated-scalarのconjugatable<ReferenceValue>を適格要件ではなく制約に変更- “If an algorithm in [linalg.algs] accesses the elements of an out-vector, out-matrix, or out-object, it will do so in write-only fashion.”という文言を削除
- P2642の内容をR2にアップデート
- 全てのタグ型の
default実装デフォルトコンストラクタにexplicitを付加 givens_rotation_setupを出力パラメータではなく新しいgivens_rotation_setup_result構造体の値を返すように変更
などです。
P1684R4 mdarray: An Owning Multidimensional Array Analog of mdspan
多次元配列クラスmdarrayの提案。
- P1684R1 mdarray: An Owning Multidimensional Array Analog of mdspan - [C++]WG21月次提案文書を眺める(2022年03月)
- P1684R2 mdarray: An Owning Multidimensional Array Analog of mdspan - [C++]WG21月次提案文書を眺める(2022年04月)
- P1684R3 mdarray: An Owning Multidimensional Array Analog of mdspan - [C++]WG21月次提案文書を眺める(2022年07月)
このリビジョンでの変更は、size constructible container要件を削除し、関連するコンストラクタでは事前条件を使用するようにしたことです。
P1883R2 file_handle and mapped_file_handle
ファイルI/Oライブラリの提案。
この提案のファイルI/Oライブラリはllfioというライブラリをベースとしたもので、llfioは現代の高性能ストレージに対するI/Oで理論性能値に迫るパフォーマンスを引き出すことができることを謳っています。また、llfioはPOSIX(Linux/Mac等)とWindowsにおけるI/Oを抽象化して扱うクロスプラットフォームなライブラリでもあります。
この提案では、そのllfioからfile_handleとmapped_file_handleを中心としたファイル毎のI/O機能を標準ライブラリへ導入しようとしています(llfio自体はネットワークI/Oやファイルシステム操作などより広い機能を持っています)。
llfioではファイルやファイルシステムの要素などをハンドルという次のような7階層の階層構造によって抽象化しています
handle- オープン/クローズ、パスの取得、クローン、追加のみのset/unset、キャッシュの変更、などの特性を提供する
fs_handle- inode番号を持つ
handle
- inode番号を持つ
path_handle- ファイルシステムの一部分への競合の無いアンカー
directory_handle- ファイルシステムを列挙する
io_handle- 同期スキャッタ/ギャザーI/O、バイト範囲ロックを提供する
file_handle- ファイルのオープン/クローズ、最大サイズの設定/取得を提供する
mapped_file_handle- メモリマップされたファイルに対する低レインテンシのスキャッタ/ギャザーI/Oを提供する
この階層構造はこのままクラスの継承関係に対応しています。
file_handleとmapped_file_handleは6,7階層に位置するもので、ファイルという対象に対する実際のI/O操作を提供します。主役がこの2つであるだけで、下の5階層のクラスも一緒に導入されます。
提案文書より、スキャッタ書き込みのサンプルコード
// 上記階層構造によって、file_handleでもmapped_file_handleでも使用可能 void write_and_close(file_handle &&fh) { // ファイルの最大サイズを設定 // mapped_file_handleはファイルサイズが固定のために必要 fh.truncate(12).value(); // 書き込むデータのバッファ const char a[] = "hel"; const char b[] = "l"; const char c[] = "lo w"; const char d[] = "orld"; // ギャザー書き込み(バラバラのバッファからのスキャッタ書き込み)を行う // file_handleの場合 : max_buffers() >= 4ならばこの書き込みは並行する読み取りに対してアトミック // そのような読み取りは何も読まないか、完了した結果を読むかのどちらか(破損はない) // mapped_file_handleの場合 : 書き込みに伴う同期は行われず、読み書きは並行するリーダ/ライターに対して競合するため、追加の同期が必要になる fh.write( // ギャザーリストの指定 { // 入力はstd::byteで行われるためキャストが必要 { reinterpret_cast<const byte*>(a), sizeof(a) - 1 }, { reinterpret_cast<const byte*>(b), sizeof(b) - 1 }, { reinterpret_cast<const byte*>(c), sizeof(c) - 1 }, { reinterpret_cast<const byte*>(d), sizeof(d) - 1 }, } // デフォルトのタイムアウトは無限 ).value(); // 失敗した場合、filesystem_error例外をスローする // ファイルのクローズに失敗する場合に備えて、明示的にファイルをクローズする fh.close().value(); } // 書き込み用にファイルをオープン // 必要に応じてファイルを作成、キャッシュをスルーして書き込み write_and_close(file( {}, // 子要素(↓)を探索するベースディレクトリのpath_handle(この場合はカレントディレクトリを意味する) "hello", // ベースディレクトリ(↑)からの相対的なパスフラグメントへのpath_view(ファイル名) file_handle::mode::write, // 書き込みアクセスを要求 file_handle::creation::if_needed, // 必要ならファイルを新規作成 file_handle::caching::reads_and_metadata // ストレージに到達するまで書き込み(デフォルトはnone ).value()); // 失敗した場合、filesystem_error例外をスローする const path_handle& somewhere; // メモリマップを使用して既存ファイルを更新する例 write_and_close(mapped_file( somewhere, // 子要素(↓)を探索するベースディレクトリのpath_handle "hello2", // ベースディレクトリ(↑)からの相対的なパスフラグメントへのpath_view(ファイル名) file_handle::mode::write, // 書き込みアクセスを要求 file_handle::creation::open_existing // 既存ファイルを開くのみ、ファイルがない場合に失敗する // デフォルトは全てキャッシュを使用する ).value()); // 失敗した場合、filesystem_error例外をスローする
mapped_file_handleはメモリにマップされたファイルの抽象であり、ファイル書き込みに伴ってファイルサイズの自動延長が行われないなどの制約があります。一方で、file_handleはもっと広いファイルの抽象であり、通常ファイルの自動延長機能を持ちます。
各I/O操作やハンドル作成の結果でvalue()を呼んでいるのは、それぞれの操作がresult<T>型を返しており、その成功結果を取得するためです。result<T>はエラー型がstd::error(P1028R4)に固定されたstd::expectedのような型で、同じようなインターフェースを持っています。
file_handleとmapped_file_handleのfileとはUNIXにおけるファイルという概念のようなもので、必ずしもファイルシステム上のファイルだけを意味するのではなく、ファイルとして扱えるもの全体を指しています。例えば、ASIOがソケットベースのI/Oライブラリであるとすると、このライブラリはファイルベースのI/Oライブラリです。
このライブラリは次のような設計原則を謳っています
- デフォルトパラメータや設定はパフォーマンスよりもセキュリティを重視する。
- これはいつでも明示的にオプトアウトできる
- 実行されるI/Oの種別に関係なく、基礎となるシステムコールのラインタイムオーバーヘッドを超える(ライブラリの)統計的に計測可能なラインタイムオーバーヘッドはない
- ホストOSの並行I/Oに関する保証を可能な限りそのまま提供する
- POSIXのrace free filesystem path lookup拡張を中心として設計されている
- システム内でのどこでも、C++I/Oと最終ストレージデバイスの間の全てのメモリコピーを常に回避可能である必要がある
- カーネルI/Oキャッシュ制御および仮想メモリ制御機能を提供する
- ファイルシステムの競合を検知して回避する機能を提供し、少なくともホストOSが許可する範囲で第三者によるファイルシステム同時変更によって導入される競合が完全にないコードを記述可能にする
筆者の方(llfio開発者の方)によれば、llfioの中でfile_handleとmapped_file_handle周りのAPIおよびABIは2020年ごろから安定しており、市場取引のデータ処理において数年間の使用実績があり、現在も1TB/日のデータを処理している、とのことです。
この提案は現在のところ機能や設計についてのレビューを受けている段階であり、具体的な文言はありません。
- ned14/llfio P1031 low level file i/o and filesystem library for the C++ standard
- LLFIO: Mainpage
- P1883 進行状況
P1928R2 Merge data-parallel types from the Parallelism TS 2
std::simd<T>をParallelism TS v2から標準ライブラリへ移す提案。
以前の記事を参照
このリビジョンでの変更は
- 浮動小数点数ランクに対応したコンストラクタの
explicit指定の追加 - 新しいABIタグの同じもしくは異なるセマンティクスについて追記
- セクション4導入段落を修正
simd::sizeをstd::integral_constant<size_t, N>型のstatic constexpr変数に変更- APIの
constexpr対応についてドキュメントを追記 constexprを提案する文言に追加- ABI境界を越えて
std::simdをやり取りするためのABIタグを削除 - キャストインターフェースの変更を適用
などです。
P1967R10 #embed - a simple, scannable preprocessor-based resource acquisition method
コンパイル時(プリプロセス時)にバイナリデータをインクルードするためのプリプロセッシングディレクティブ#embedの提案。
以前の記事を参照
- P1967R3
#embed- a simple, scannable preprocessor-based resource acquisition method - [C++]WG21月次提案文書を眺める(2021年04月) - P1967R4
#embed- a simple, scannable preprocessor-based resource acquisition method - [C++]WG21月次提案文書を眺める(2021年06月) - P1967R5
#embed- a simple, scannable preprocessor-based resource acquisition method - [C++]WG21月次提案文書を眺める(2021年04月) - P1967R6
#embed- a simple, scannable preprocessor-based resource acquisition method - [C++]WG21月次提案文書を眺める(2022年05月) - P1967R7
#embed- a simple, scannable preprocessor-based resource acquisition method - [C++]WG21月次提案文書を眺める(2022年06月) - P1967R8
#embed- a simple, scannable preprocessor-based resource acquisition method - [C++]WG21月次提案文書を眺める(2022年07月) - P1967R9
#embed- a simple, scannable preprocessor-based resource acquisition method - [C++]WG21月次提案文書を眺める(2022年10月)
このリビジョンでの変更は、ファイルが空であることを検知するための__has_embedとsuffix/prefix/if_emptyの指定をオプショナルな機能から提案する機能に移動したことなどです。
P2013R5 Freestanding Language: Optional ::operator new
フリースタンディング処理系においては、オーバーロード可能なグローバル::operator newを必須ではなくオプションにしようという提案。
以前の記事を参照
- P2013R1 : Freestanding Language: Optional
::operator new- [C++]WG21月次提案文書を眺める(2020年04月) - P2013R3 : Freestanding Language: Optional
::operator new- [C++]WG21月次提案文書を眺める(2020年09月) - P2013R3 : Freestanding Language: Optional
::operator new- [C++]WG21月次提案文書を眺める(2021年05月)
このリビジョンでの変更は、LWGのフィードバックを反映したことです。
この提案はすでにLWGのレビューを終えており、次の全体会議で投票にかけられる予定です。
P2047R5 An allocator-aware optional type
Allocator Awareなstd::optionalである、std::pmr::optionalを追加する提案。
以前の記事を参照
- P2047R1 An allocator-aware optional type - [C++]WG21月次提案文書を眺める(2021年02月)
- P2047R2 An allocator-aware optional type - [C++]WG21月次提案文書を眺める(2021年08月)
- P2047R3 An allocator-aware optional type - [C++]WG21月次提案文書を眺める(2022年07月)
- P2047R4 An allocator-aware optional type - [C++]WG21月次提案文書を眺める(2022年10月)
このリビジョンでの変更は、提案する文言の調整、デフォルトのアロケータ型の引数にstd::remove_cv_tを通すようにしたこと、make_~関数の削除(文言からは消えてない?)などです。
この提案はどうやら、これ以上議論に時間を費やさないことになったようです。
P2075R2 Philox as an extension of the C++ RNG engines
<random>に新しい疑似乱数生成エンジンを追加する提案。
以前の記事を参照
このリビジョンでの変更は
- Philoxだけに着目したAPIの文言をシンプルにした
- カウンタベースエンジンのAPIを拡張した
- Design considerationsを追加
- エンジン型に
set_counter()メンバ関数を追加 counter_based_engineのcテンプレートパラメータの削除
などです。
P2164R9 views::enumerate
元のシーケンスの各要素にインデックスを紐付けた要素からなる新しいシーケンスを作成するRangeアダプタviews::enumerateの提案。
以前の記事を参照
- P2164R0 views::enumerate - [C++]WG21月次提案文書を眺める(2020年5月)
- P2164R1 views::enumerate - [C++]WG21月次提案文書を眺める(2020年6月)
- P2164R2 views::enumerate - [C++]WG21月次提案文書を眺める(2020年9月)
- P2164R3 views::enumerate - [C++]WG21月次提案文書を眺める(2020年11月)
- P2164R4 views::enumerate - [C++]WG21月次提案文書を眺める(2021年02月)
- P2164R5 views::enumerate - [C++]WG21月次提案文書を眺める(2021年06月)
- P2164R6 views::enumerate - [C++]WG21月次提案文書を眺める(2022年08月)
- P2164R7 views::enumerate - [C++]WG21月次提案文書を眺める(2022年10月)
- P2164R8 views::enumerate - [C++]WG21月次提案文書を眺める(2022年11月)
このリビジョンでの変更は、提案する文言の修正のみです。
この提案は2023年2月のIssaquah会議でC++23に向けて採択されています。
P2169R3 A Nice Placeholder With No Name
宣言以降使用されず追加情報を提供するための名前をつける必要もない変数を表すために_を言語サポート付きで使用できる様にする提案。
以前の記事を参照
- P2169R0 A Nice Placeholder With No Name - WG21月次提案文書を眺める(2020年5月)
- P2169R1 A Nice Placeholder With No Name - WG21月次提案文書を眺める(2022年7月)
- P2169R2 A Nice Placeholder With No Name - WG21月次提案文書を眺める(2022年9月)
このリビジョンでの変更は、提案する文言を追加したこと、名前空間スコープでは複数回の使用を禁止した(以前は名前付モジュール本文の名前空間スコープでのみ複数回使用可能としていた)ことなどです。
P2198R6 Freestanding Feature-Test Macros and Implementation-Defined Extensions
↓
P2198R7 Freestanding Feature-Test Macros and Implementation-Defined Extensions
フリースタンディング処理系でも使用可能なライブラリ機能について、機能テストマクロを追加する提案。
以前の記事を参照
- P2198R0 Freestanding Feature-Test Macros and Implementation-Defined Extensions - [C++]WG21月次提案文書を眺める(2020年07月)
- P2198R1 Freestanding Feature-Test Macros and Implementation-Defined Extensions - [C++]WG21月次提案文書を眺める(2020年10月)
- P2198R2 Freestanding Feature-Test Macros and Implementation-Defined Extensions - [C++]WG21月次提案文書を眺める(2021年07月)
- P2198R3 Freestanding Feature-Test Macros and Implementation-Defined Extensions - [C++]WG21月次提案文書を眺める(2021年11月)
- P2198R4 Freestanding Feature-Test Macros and Implementation-Defined Extensions - [C++]WG21月次提案文書を眺める(2021年12月)
- P2198R5 Freestanding Feature-Test Macros and Implementation-Defined Extensions - [C++]WG21月次提案文書を眺める(2022年04月)
R6での変更は、
- 最新のワーキングドラフトへの追随
- 次のC++23機能テストマクロをフリースタンディング指定
__cpp_lib_forward_like__cpp_lib_modules__cpp_lib_move_iterator_concept__cpp_lib_ranges_as_const__cpp_lib_ranges_as_rvalue__cpp_lib_ranges_cartesian_product__cpp_lib_ranges_repeat__cpp_lib_ranges_stride__cpp_lib_start_lifetime_as
このリビジョン(R7)での変更は、LWGのフィードバックの反映のみです。
この提案は既にLWGのレビューを終えており、次の全体会議で投票にかけられる予定です(C++26ターゲットです)。
P2338R3 Freestanding Library: Character primitives and the C library
<charconv>とstd::char_traitsをはじめとするいくつかのヘッダをフリースタンディングライブラリ指定する提案。
以前の記事を参照
- P2338R0 Freestanding Library: Character primitives and the C library - WG21月次提案文書を眺める(2021年03月)
- P2338R1 Freestanding Library: Character primitives and the C library - WG21月次提案文書を眺める(2021年07月)
- P2338R2 Freestanding Library: Character primitives and the C library - WG21月次提案文書を眺める(2021年11月)
このリビジョンでの変更は提案する文言の調整などです。
この提案は、C++26をターゲットとしてLEWGからLWGへ転送されています。
P2363R4 Extending associative containers with the remaining heterogeneous overloads
連想コンテナの透過的操作を、さらに広げる提案。
以前の記事を参照
- P2363R0 Extending associative containers with the remaining heterogeneous overloads - WG21月次提案文書を眺める(2021年04月)
- P2363R1 Extending associative containers with the remaining heterogeneous overloads - WG21月次提案文書を眺める(2021年09月)
- P2363R2 Extending associative containers with the remaining heterogeneous overloads - WG21月次提案文書を眺める(2021年12月)
- P2363R3 Extending associative containers with the remaining heterogeneous overloads - WG21月次提案文書を眺める(2022年01月)
このリビジョンでの変更は、set/unordered_setの.insert()に追加するオーバーロードが曖昧にならないように制約を追加したことです。
この提案はLWGでレビュー中ですが、C++26をターゲットにしています。
P2406R1 Fix counted_iterator interaction with input iterators
↓
P2406R2 Add lazy_counted_iterator
std::counted_iteratorを安全に使用可能にする提案。
以前の記事を参照
R1での変更は、フィードバックに基づく提案全体の修正などです。
このリビジョン(R2)での変更は
- P2578への参照を削除
- 提案する設計について修正
- いくつかの代替案の提示
この提案はR1以降、問題を解決したcounted_iteratorをlazy_counted_iteratorとして追加し、それを使用するバージョンのviews::take/views::countedとしてlazy_take/lazy_countedを追加することを提案しています。
その上で、その設計について提示されているオプションは次のものです
lazy_counted_iteratorを可能な限りcounted_iteratorに近づけるlazy_counted_iteratorは最も強くてもforward_iteratorとする- これによって、デクリメントを考慮しなくても良くなる
- 0カウントで構築された時は、あらゆる読み取りを許可しない
- 可能なのは、カウント値の読み取り(
.count())と終端チェック(==)のみ
- 可能なのは、カウント値の読み取り(
- 間接参照時に基底のイテレータをインクリメントする
- これによって、逆参照が
const操作ではなくなり、イテレータをコピーしてからインクリメントするとコピー元が無効になる - 対策として、
lazy_counted_iteratorをコピー不可とする
- これによって、逆参照が
また、lazy_counted_iteratorではそのカウント値に依存して基底のイテレータの状態が非線形に変化することから、基底イテレータを取得するbase()をどうするかも問題となり、そのためのオプションを提示されています
.base()を提供しないlazy_counted_iteratorをコピー不可とする- 実装は、
.base()の呼び出し時に必要に応じて(0カウントの時)イテレータをインクリメントして返す .base()の呼び出しは遅延操作ではないlazy_counted_iteratorをコピー不可とすることで、lazy_counted_iteratorの無効化について考慮しなくて良くなる
- 実装は、
.base()を提供するが、それによって他のコピーが無効となることを指定する- 実装は、
.base()の呼び出し時に必要に応じて(0カウントの時)イテレータをインクリメントして返す
- 実装は、
SG9の投票では、lazy_counted_iteratorそのものについてはオプション1と2が選択され、.base()に関してはオプション1が選択されたため、R2の文言はそれを反映したものになっています。
LEWGのレビューと投票では、lazy_counted_iteratorに対する変更をcounted_iteratorに直接適用することに弱いながらもコンセンサスが得られている様です。
P2407R2 Freestanding Library: Partial Classes
一部の有用な標準ライブラリのクラス型をフリースタンディング処理系で使用可能とする提案。
以前の記事を参照
- P2407R0 Freestanding Library: Partial Classes - WG21月次提案文書を眺める(2021年07月)
- P2407R1 Freestanding Library: Partial Classes - WG21月次提案文書を眺める(2021年11月)
このリビジョンでの変更は、提案をHTMLにしたこと、フリースタンディング対象外のメンバ関数はdeleteされると注釈をつけた(対象のものには注釈しないようにした)こと、std::forward_likeへの言及、フリースタンディング指定をまとめて行うような文言の追加、などです。
この提案は、LWGのレビュー中で、C++26をターゲットにしています。
P2508R2 Exposing std::basic-format-string
説明専用のstd::basic-format-string<charT, Args...>をユーザーが利用できるようにする提案。
以前の記事を参照
- P2508R0 Exposing
std::basic-format-string- WG21月次提案文書を眺める(2021年12月) - P2508R1 Exposing
std::basic-format-string- WG21月次提案文書を眺める(2022年01月)
このリビジョンでの変更は提案する文言の調整のみです。
この提案は2022年11月のkona会議で全体投票をパスしており、C++23ワーキングドラフトに含まれています。
P2530R2 Why Hazard Pointers should be in C++26
標準ライブラリにハザードポインタサポートを追加する提案。
以前の記事を参照
- P2530R0 Why Hazard Pointers should be in C++26 - WG21月次提案文書を眺める(2022年02月)
- P2530R1 Why Hazard Pointers should be in C++26 - WG21月次提案文書を眺める(2022年10月)
このリビジョンでの変更は、使用例をtony-tableにして、使用しない時としたときの比較ができるようにしたことです。
この提案は、LEWGの投票をパスしてLWGに転送されています(C++26ターゲットです)。
P2537R2 Relax va_start Requirements to Match C
可変長引数関数を0個の引数で宣言できるようにする提案。
以前の記事を参照
- P2537R0 Relax
va_startRequirements to Match C - WG21月次提案文書を眺める(2022年02月) - P2537R1 Relax
va_startRequirements to Match C - WG21月次提案文書を眺める(2022年08月)
このリビジョンでの変更は、C23の仕様(N2975、C23に導入済み)に合わせた2つの文言を用意したことと、CWG/EWGによって選択されなかった方の文言を巻末に移動させたことです。
この提案は、C++26をターゲットとしてCWGでレビュー中です。
P2545R2 Why RCU Should be in C++26
標準ライブラリにRead-Copy-Update(RCU)サポートを追加する提案。
以前の記事を参照
- P2545R0 Why RCU Should be in C++26 - WG21月次提案文書を眺める(2022年02月)
- P2545R1 Why RCU Should be in C++26 - WG21月次提案文書を眺める(2022年10月)
このリビジョンでの変更は、提案する文言の改善、使用例をtony-tableにして、使用しない時としたときの比較ができるようにしたこと、将来的に想定される機能の拡張方向についてを記述したことなどです。
この提案では、RCU機能の将来的な拡張や改善について想定されるものとして次のものを挙げています
- 削除処理が呼び出されるコンテキストとそのタイミングを制御する方法の提供
- RCUを介した型安全メモリ
- Linuxの
SLAB_TYPESAFE_BY_RCUのようなもの
- Linuxの
std::thread以外のスレッドの手動登録方法の提供rcu_retire()のメタデータ処理に関する、実装者とユーザーに対するアドバイスの提供- メモリリーク検出器との相互作用について
この提案は、LEWGの投票をパスしてLWGに転送されています(C++26ターゲットです)。
P2570R2 Contract predicates that are not predicates
コントラクト注釈に指定された条件式が副作用を持つ場合にどうするかについて、議論をまとめた文書。
以前の記事を参照
- P2570R0 On side effects in contract annotations - WG21月次提案文書を眺める(2022年06月)
- P2570R1 On side effects in contract annotations - WG21月次提案文書を眺める(2022年11月)
このリビジョンでの変更は
- 設計基準セクションを拡張。特に、UBが無いことを安全と同義としていないことを強調
- P2680R0のアプローチが正しいコードを壊す例を追記
- 契約条件が副作用を持つことがなぜ問題なのかを説明するセクションを追記
- 副作用を評価することを保証することが、将来考えられるビルドモード(事前条件のみ評価)を妨げる可能性がある事を追記
- 副作用が排除されるC++の他の場所の例を追記
などです。
P2591R2 Concatenation of strings and string views
std::stringとstd::string_viewを+で結合できるようにする提案。
以前の記事を参照
- P2591R0 Concatenation of strings and string views - WG21月次提案文書を眺める(2022年05月)
- P2591R1 Concatenation of strings and string views - WG21月次提案文書を眺める(2022年06月)
このリビジョンでの変更は
- 提案する
operator+のシグネチャを変更std::string_viewに変換可能なものを取るのではなく、std::string_viewそのものを取るようにした
提案する
operator+をhidden friendsにした
P2616R3 Making std::atomic notification/wait operations usable in more situations
std::atomicのnotify_one()とwait()操作を使いづらくしている問題を解消する提案。
以前の記事を参照
- P2616R0 Making std::atomic notification/wait operations usable in more situations - WG21月次提案文書を眺める(2022年07月)
- P2616R2 Making std::atomic notification/wait operations usable in more situations - WG21月次提案文書を眺める(2022年11月)
このリビジョンでの変更は、atomic_notify_tokenをnotify_tokenに名前を変更した事、notify_tokenのテンプレートパラメータを任意の型からatomic型に変更したことなどです。
P2630R2 Submdspan
std::mdspanの部分スライスを取得する関数submdspan()の提案。
以前の記事を参照
このリビジョンでの変更は
- カスタマイゼーションポイント選択に関する議論を追加
strided_index_rangeをstrided_sliceにリネームsubmdspan_mappingの戻り値型のために、マッピングとオフセットを持つ名前付き構造体を導入- mandatesの冗長な制約を削除し、よりよりエラーメッセージを得られるようにした
- レイアウトポリシー型の保存ロジックを修正
- 特に、ランク0マッピングのレイアウトを保存し、スライス指定のいずれかが
stride_index_rangeである場合にlayout strideを作成するようにした
- 特に、ランク0マッピングのレイアウトを保存し、スライス指定のいずれかが
- エクステントがstrideより小さい場合の
strided_sliceのサブマッピングエクステントの計算を修正- 依然として、サブマッピングエクステントは1となる
strided_slice指定のサブマッピングストライド計算を修正strided_sliceのstrideが0の場合に対処するために事前条件を追加
などです。
この提案は現在LEWGのレビュー中で、C++26ターゲットに変更されています。
P2636R2 References to ranges should always be viewable
ムーブオンリーなrangeの左辺値参照をviewable_rangeとなるようにする提案。
以前の記事を参照
- P2636R0 References to ranges should always be viewable - WG21月次提案文書を眺める(2022年09月)
- P2636R1 References to ranges should always be viewable - WG21月次提案文書を眺める(2022年10月)
このリビジョンでの変更は主に説明や例の拡充や修正ですが、この提案はLEWGでコンセンサスを得られなかったため、追求は停止されています。
P2642R2 Padded mdspan layouts
std::mdspanでpadding strideをサポートするためのレイアウト指定クラスを追加する提案。
以前の記事を参照
- P2642R0 Padded mdspan layouts - WG21月次提案文書を眺める(2022年09月)
- P2642R1 Padded mdspan layouts - WG21月次提案文書を眺める(2022年10月)
このリビジョンでの変更は
layout_{left,right}_paddedの特殊化は、レイアウトマッピングポリシー要件を満たし、トリビアル型であるという規定を追加layout_{left,right}_padded::mappingのコンストラクタの事前条件の単純化layout_{left,right}_padded::mappingのデフォルトコンストラクタを追加layout_{left,right}_padded::mappingにlayout_(left,right)::mappingからの変換コンストラクタを追加layout_{left,right}_padded::mappingにlayout_stride::mappingからの変換コンストラクタを追加layout_{left,right}_padded::mappingにoperator==を追加- 既存のコンストラクタ
layout_stride::mapping(const StridedLayoutMapping&)のexplicit条件内のレイアウトマッピング型のリストにlayout_{left,right}_paddedを追加layout_{left,right}_padded::mappingからlayout_stride::mappingへの変換はexplicitではない
などです。
P2656R1 C++ Ecosystem International Standard
C++実装(コンパイラ)と周辺ツールの相互のやり取りのための国際規格を発効する提案。
以前の記事を参照
このリビジョンでの変更は、IS発行のためのタイムラインとプロセスを追加したことなどです。
Ecosystem ISは2023年から始まる2年ごとのリリースサイクルで発効していくことを目指していて、最初のISを発効するためのスケジュールを次のようにしています
- 2023/02 : 計画
- 最初のISの開発計画の完了
- 初版に何が含まれるかを検討
- 2023/03 : 最初のドラフト作成
- 最初の最小限のドラフトを作成
- このドラフトには、最低1つの提案が統合されていて、のこりのものも概要が記載されている
- 作業のチェックポイントとするために、EWGの承認を得る
- 2024/02 : 提案
- 最初のIS発効のための正式な提案を作成する
- そこには、最初のISのドラフトのほぼ完全なものが含まれる
- 2025/01 : CD作成完了
- NBコメント募集のためのCommittee Draftを承認する
- 2025/02 : DIS作成完了
- 寄せられたNBコメントを解決したFinal Draft International Standardを承認する
この後、2年ごとに同様のスケジュールでEcosystem ISを改善していく予定です。C++本体と比較すると次のようになります

この作業のためのWG21におけるプロセスは、WG21の現在のプロセスに親和するように次の2つのプロセスを提案しています
- ブートストラップ
- Tooling Study Group (SG15)で初期開発及びレビュー
- その後、EWG/LEWGでのレビューと承認
- そこから、文言プロセスの定期的なレビューと承認が続く
- 並行
- 開発及びレビューは、適宜既存のSGから開始できる
- 続いて、Tooling Working Group (TWG)によるレビューと承認が行われる
- TWGはIS事態の文言の検討も行い、WG21全体投票のための作業も担う
ブートストラッププロセスは最初のISを作成するために使用し、その後は並行プロセスに切り替えます。
並行プロセスは、現在のWG21作業フローをベースに次のようなものになります
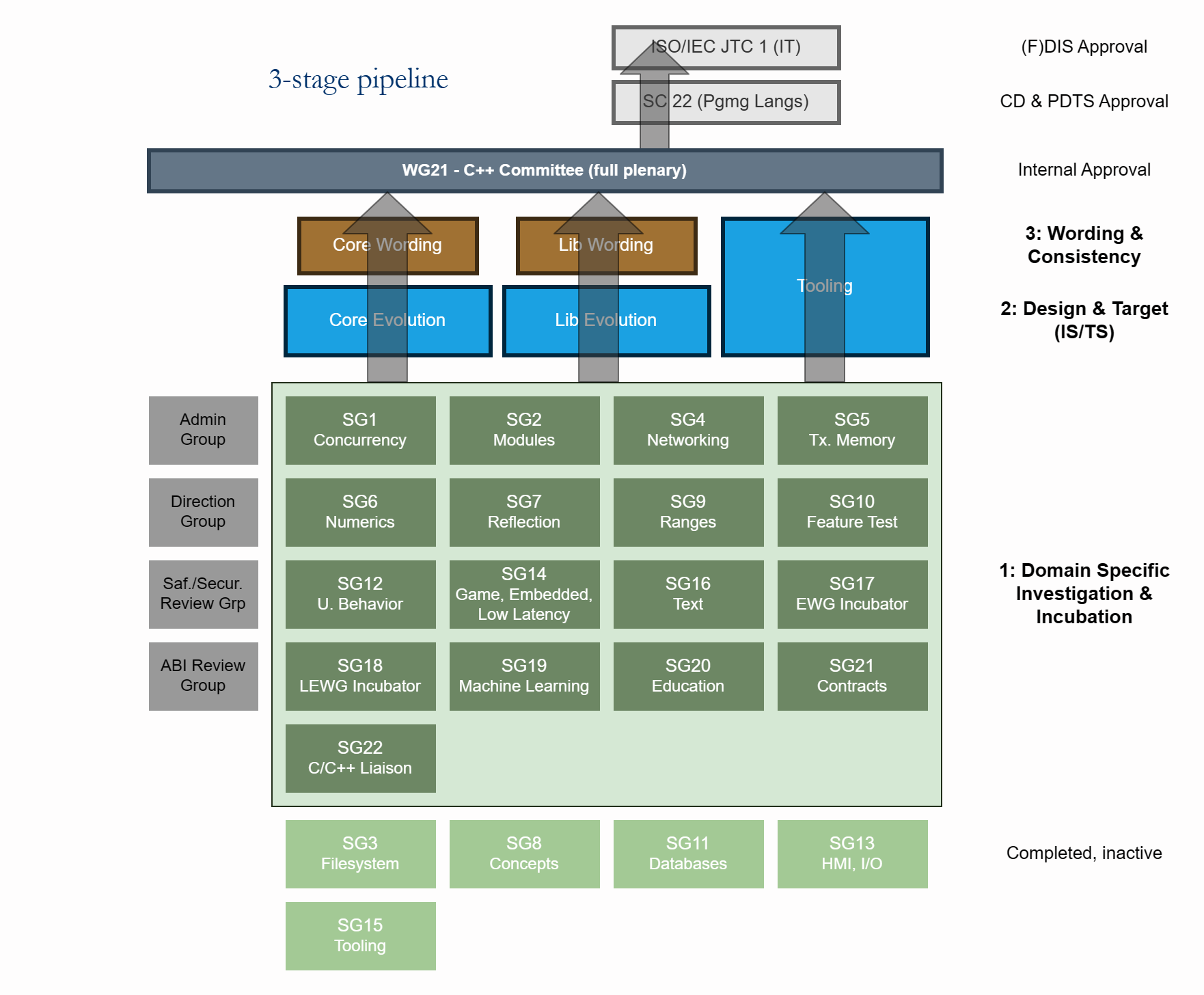
P2659R2 A Proposal to Publish a Technical Specification for Contracts
契約プログラミング機能に関するTechnical Specificationを発効する提案。
以前の記事を参照
- P2659R0 A Proposal to Publish a Technical Specification for Contracts - [C++]WG21月次提案文書を眺める(2022年10月)
- P2659R1 A Proposal to Publish a Technical Specification for Contracts - [C++]WG21月次提案文書を眺める(2022年11月)
このリビジョンでの変更は
- GCCが契約機能を実装したのを受けて、MotivationとAppendixを更新
- タイムラインのアップデート
などです。
P2675R1 LWG3780: The Paper (format's width estimation is too approximate and not forward compatible)
std::formatの文字幅の規定を改善する提案。
以前の記事を参照
このリビジョンでの変更は
- 標準がワイドとして予約するコードポイントはそのように扱わないことを明示
- サンプルとして示した結果の生成に使用したファイルへのリンクを追加
- 関連する、既存のターミナルにおける実装へのリンク追加
- 有用ではなかったスクリーンショットを削除
などです。
P2677R2 Reconsidering concepts in-place syntax
autoによる簡易関数宣言構文において、型名を取得可能にする提案。
以前の記事を参照
このリビジョンでの変更は
- 推奨するシンボルを
~から:に変更 - 可能な表記方法についての追加の議論を追記
- ユニバーサル参照(フォワーディングリファレンス)についての議論の追記
この提案のR1は公開されていませんが、どうやらそこではautoから型名を取得する構文としてauto~Tのようなものを提案していたようです。これはR0で提案していたauto{T}がdecay-copy構文(auto{x})と衝突することによるもので、このリビジョンではそれを:に置き換えています。
// R0(auto{x}、decay-copyと衝突する) [](auto{T}&& x) { return f(std::forward<T>(x)); } // R1 [](auto~T && x) { return f(std::forward<T>(x)); } // R2 [](auto:T && x) { return f(std::forward<T>(x)); }
まだ確定ではなく、この提案では他の選択肢として$や@、ダッシュのほか、auto<T>やT:autoなどを候補として挙げています。
P2680R1 Contracts for C++: Prioritizing Safety
C++の契約プログラミング機能は安全第一で設計されるべき、という提言。
以前の記事を参照
このリビジョンは、基本的なところは変わっていないようですがほとんどR0と別物になっています。特に、巻末にP2700の問に対する回答が記されています。
- P2700R0 Questions on P2680 “Contracts for C++: Prioritizing Safety” - WG21月次提案文書を眺める(2022年11月)
- P2680 進行状況
P2689R1 atomic_accessor
アトミック操作を適用した参照を返すmdspanのアクセッサである、atomic_accessorの提案。
以前の記事を参照
このリビジョンでの変更は
- 特定のメモリオーダーを指定する
std::atomic_refであるatomic-ref-boundedを説明専用テンプレートとして追加 atomic_ref_relaxed, atomic_ref_acq_rel, atomic_ref_seq_cstの3つのエイリアスを追加basic-atomic-accessor説明専用テンプレートを追加atomic_accessor_relaxed, atomic_accessor_acq_rel, atomic_accessor_seq_cstの3つのテンプレートを追加
R0では、atomic_accessorで使用するstd::atomic_refのデフォルトのメモリオーダーが過剰で、それが変更できないことが問題になっていました。
このリビジョンではその対応のために、メモリオーダー指定をテンプレートパラメータで受け取るバージョンのstd::atomic_refをatomic-ref-boundedとして説明専用で追加し、その設定済みエイリアスとしてatomic_ref_relaxed, atomic_ref_acq_rel, atomic_ref_seq_cstを追加します。
そして、使用するatomic_refを追加のテンプレートパラメータとして受け取ることでメモリオーダーを指定するbasic-atomic-accessorを追加し、atomic_accessor及びatomic_accessor_relaxed, atomic_accessor_acq_rel, atomic_accessor_seq_cstはその設定済みエイリアステンプレートとして定義されます。
namespace std { // メモリオーダー指定を受けることのできるatomic_ref(説明専用) template <class T, memory_order MemoryOrder> struct atomic-ref-bounded { ... }; // 特定のメモリオーダーによるatomic_ref(これらは説明専用ではない) template<class T> using atomic_ref_relaxed = atomic-ref-bounded<T, memory_order_relaxed>; template<class T> using atomic_ref_acq_rel = atomic-ref-bounded<T, memory_order_acq_rel>; template<class T> using atomic_ref_seq_cst = atomic-ref-bounded<T, memory_order_seq_cst>; // atomic_accessorのベース型(説明専用) template <class ElementType, class ReferenceType> struct basic-atomic-accessor { ... }; // デフォルトのatomic_accessor、std::atomic_refを使用 template <class ElementType> using atomic_accessor = basic-atomic-accessor<ElementType, atomic_ref<ElementType>>; // メモリオーダーをカスタムしたatomic_accessor template <class ElementType> using atomic_accessor_relaxed = basic-atomic-accessor<ElementType, atomic_ref_relaxed<ElementType>>; template <class ElementType> using atomic_accessor_acq_rel = basic-atomic-accessor<ElementType, atomic_ref_acq_rel<ElementType>>; template <class ElementType> using atomic_accessor_seq_cst = basic-atomic-accessor<ElementType, atomic_ref_seq_cst<ElementType>>; }
atomic_ref_relaxed, atomic_ref_acq_rel, atomic_ref_seq_cstの3つは、メモリオーダーが変更されたstd::atomic_refとして追加され、ユーザーが使用することができます。
P2700R1 Questions on P2680 "Contracts for C++: Prioritizing Safety"
P2680R0で提唱されている契約条件の副作用の扱いについて、幾つかの疑問点を提出する文書。
以前の記事を参照
このリビジョンでの変更は
- 緩和された契約条件とそうでないものの両方の存在を説明するための修正
- Q1.4, Q5.1, Q5.2, Q5.9について、明確化したり質問を拡張
- Q5.10に新しい質問を追加
などです。
これ(多分R0)に対する回答は、少し上のP2680R1でなされています。
P2713R0 Escaping improvements in std::format
↓
P2713R1 Escaping improvements in std::format
std::formatのエスケープ出力(?)時の出力方法を修正する提案。
std::formatの?指定は、C++23でrange出力サポート(P2286R8)と同時に、ロギングやデバッグ時の出力のために追加されたものです。
?による指定は特に文字/文字列の出力時に有効なもので、入力の文字列をそのまま(人間の視認性を優先して)出力します。出力はまず、出力文字列全体が"にくくられて出力され、入力された文字で対応するエスケープシーケンスがある文字(\t \n \r " \の5つ)は対応するエスケープシーケンスに置換されて出力されます。また、ユニコード文字の中でも出力できない(見えない)ものなどや、無効な文字となるものもエスケープされて(\u{xxxx}の形で)出力されます。
int main() { std::cout << std::format("{:?}", "hello") << std::endl; // "hello"と出力 std::cout << std::format("{:?}", R"("hello"\n)") << std::endl; // "\"hello\"\n"と出力 }
このフォーマット時のエスケープの振る舞いは、入力文字列を1文字づつ見ていって、文字が置換条件に合致した場合に対応する表現に置換(エスケープ)されて出力する、ような形で記述されています。
ただ、このフォーマット方法は、何を目的としてフォーマットするのかが不明瞭だったようです。つまり、このエスケープは、入力文字列を人間にとって読みやすい形で出力することを意図しているのか、元のエンコーディングにおける文字表現を視認可能な形で出力することを意図しているのか、が不透明で、それによって一部の文字の最適なエスケープが変化します。これはC++23 CDに対するアメリカ/フランスからのNBコメントによって指摘されました。
この提案は、?によってエスケープされた出力文字列の意図が、入力文字/文字列をC++コード上で文字/文字列リテラルとして記述した場合の文字列を再現することにあることを明確化するために、エスケープ方法を修正するものです。
この提案はこの問題に関するSG16の投票によって確認された事項に対して標準の文言を提供するもので、SG16では次のことが確認されました
?によってエスケープされた文字列はそのまま文字/文字列リテラルとして使用できる- エスケープされた文字列は視覚的に明確な(人間にとって読み取りやすい)文字列を生成しない
- 区切り文字や表示できない文字は引き続きエスケープされる
これによる主な変更は、次のようになります
提案文書より、サンプルコード
string s0 = format("[{}]", "h\tllo"); // s0の結果文字列は [h llo] (非エスケープ出力) string s1 = format("[{:?}]", "h\tllo"); // s1の結果文字列は ["h\tllo"] (タブ文字が\tにエスケープ) string s3 = format("[{:?}, {:?}]", '\'', '"'); // s3の結果文字列は ['\'', '"'] (\ と " はエスケープされて出力される) // 次の例ではUTF-8エンコーディングを仮定 string s4 = format("[{:?}]", string("\0 \n \t \x02 \x1b", 9)); // s4の結果文字列は ["\u{0} \n \t \u{2} \u{1b}"] string s5 = format("[{:?}]", "\xc3\x28"); // s5の結果文字列は ["\x{c3}("] (不正なUTF-8文字列のケース) string s6 = format("[{:?}]", "\u0301"); // s6の結果文字列は ["\u{301}"] string s7 = format("[{:?}]", "\\\u0301"); // s7の結果文字列は ["\\\u{301}"] string s8 = format("[{:?}]", "e\u0301\u0323"); // s8の結果文字列は ["ẹ́"]
この提案において振る舞いが明確化されたのは、下の3つの例(s6, s7, s8)です。まず、\u0301と\u0323はダイアクリティカルマークという結合文字(アルファベットの上下につく文字)です。
s6は、結合文字に非結合文字(結合対称)が先行していないため、エスケープされて出力されています。s7は、エスケープされた文字が先行しているため、エスケープされて出力されています。s8はエスケープされない文字(e)が先行しているため\u0301(上付きの,)が結合し、結合した結合文字が先行しているため\u0323(下付きの.)も結合して出力され、結果は見た目1文字になり、エスケープされる文字はありません。
- FR 005-134 22.14.6.4 [format.string.escaped] Aggressive escaping
- US 38-098 22.14.6.4p1 [format.string.escaped] Escaping for debugging and logging
std::format- cpprefjp- P2286R8 Formatting Ranges
- P2713 進行状況
P2714R0 Bind front and back to NTTP callables
std::bind_frontとstd::bind_backにNTTPとして呼び出し可能なものを渡すオーバーロードを追加する提案。
これは、P2511で提案されていたstd::nontypeのアプローチ(メンバポインタをNTTPとして渡す)をstd::bind_frontとstd::bind_backでできるようにしようとするもので、バインドするCallableオブジェクトを第一引数からテンプレートパラメータへ移動させます。
struct S { int func(int, char, std::string_view); }; int main() { // 現在(C++20 auto bf1 = std::bind_front(&S::func, 20, 'a'); // この提案 auto bf2 = std::bind_front<&S::func>(26, 'a'); }
このテンプレートパラメータにはメンバポインタだけでなくCPOのようなものも使用できます。
#include <compare> int main() { // 現在(C++20 auto bf1 = std::bind_front(std::strong_order, 20); // この提案 auto bf2 = std::bind_front<std::strong_order>(26); }
この提案によるメリットは
- ストレージ容量の削減
- 実装の単純化とデバッグ情報のスリム化
std::bind_frontとstd::bind_backの可読性向上invoke(func, a, b, ...)のような呼び出しはC++において一般的になりつつあるが、依然としてfunc(a, b, ...)の方がより関数呼び出しの表現として自然だと感じる人が多いと思われる- そのため、
bind_front(func, a, b)よりもbind_front<func>(a, b)の方が自然であると感じるかもしれない - また、callableターゲットとそこに束縛する引数が視覚的に分離されているため、見やすくなる
この提案では、同様の変更をstd::not_fnに対しても行うことを提案しています。
- P2511R0 Beyond operator(): NTTP callables in type-erased call wrappers - [C++]WG21月次提案文書を眺める(2022年01月)
- P2714 進行状況
P2717R0 Tool Introspection
C++周辺ツールが、Ecosystem ISにどれほど準拠しているのかを互いに通信する手段を標準化する提案。
Ecosystem ISはC++のツール(コンパイラ、ビルドシステムやパッケージマネージャ、静的解析ツールなど)環境を整備するための独立した標準規格で、P2656で方向性が提案されています。Ecosystem ISにWG21として取り組んでいくことは合意されているようです。
Ecosystem ISは既存のツールを否定しWG21でツールを作り上げるものではなく、ツールとツールの間の相互通信に必要な部分を標準化しようとするものです。
Ecosystem ISもC++そのものと同様に徐々に進化していくことを考えると、Ecosystem ISにもバージョンが生まれ、Ecosystem ISに準拠したC++ツールはある時点では特定バージョンのEcosystem ISを実装することになるでしょう。Ecosystem ISの目的はそのようなツールの相互のやり取りの標準化にあるので、互いが想定するEcosystem ISバージョンが異なる場合にそれを知る手段がないことは問題となります。
この提案は、ツールが実装するEcosystem ISのバージョン情報を取得できるメカニズムをEcosystem ISに最初から組み込んでおくことを提案するとともに、あるツールが別のツールのEcosystem ISの機能を使用する場合にどのバージョンを想定しているのかを同時に伝達できるメカニズムについても提案しています。
この提案は次の2つの機能を提案しています
- イントロスペクション(Introspection)
- 実装するバージョンについて相手に報告する
- 宣言(Declaration)
- 必要とするバージョンとエディションを相手に指定する
イントロスペクションによって、ツールは相手のツールが特定の機能を実装しているかを問い合わせることができます。問い合わせを受けたツールはサポートしている機能の範囲で応答するか何も応答しません。応答があった場合、その情報を使用して、Ecosystem IS標準に従って相手ツールとのさらなるやり取りを進めることができます。
宣言によって、ツールは特定の機能によってやり取りする時のその機能についてのバージョンを指定できます。相手ツールがその宣言を受け入れた場合は、その機能を使用してやり取りを進めることができます。
どちらの機能の場合も、これはツールのコマンドライン引数で渡し、返答はJSONで返します。
イントロスペクションの場合は--std-infoというコマンドライン引数を使用します
tool --std-info
これに対する応答は例えば次のようになります
{ "$schema": "https://raw.githubusercontent.com/cplusplus/ecosystem-is/release/schema/std_info-1.0.0.json", "std:info": "[1.0.0,2.5.0]" }
この問い合わせはEcosystem ISの全ての機能について行われ、結果もすべての機能について帰ってきます。しかし、場合によっては特定の機能についてだけ問い合わせをした方が効率的な場合がり、そのための制限付きの問い合わせをサポートしています
制限付き問い合わせも--std-infoで行いますが、機能を示す名前とバージョンを同時に指定します
tool "--std-info=std:info==[1.0.0,2.1.0)"
これは--std-infoそのもののバージョンの問い合わせです
これに対する応答は例えば次のようになります
{ "$schema": "https://raw.githubusercontent.com/cplusplus/ecosystem-is/release/schema/std_info-1.0.0.json", "std:info": "[1.5.0,2.0.0]" }
この場合、相手のツールは要求されたバージョン(1.0.0 ~ 2.1.0)のサブセット(1.5.0 ~ 2.0.0)しか実装していないといっています。
また複数同時に問い合わせることもできます
tool "--std-info=std:info=[1.0.0,2.1.0)" "--std-info=gcc:extra[2.0.0,2.1.0]"
この結果は例えば次のようになります
{ "$schema": "https://raw.githubusercontent.com/cplusplus/ecosystem-is/release/schema/std_info-1.0.0.json", "std:info": "[1.0.0,2.0.0)", "gcc:extra": "2.1.0" }
この結果を受けて、使用する機能のバージョンを指定(宣言)するには、使用する機能と共に--std-declにその機能と要求バージョンを指定するようにします。
tool "--std-decl=std:info=2.0.0" "--std-decl=gcc:extra=2.1.0" --std:info --gcc:extra...
ここでは、--std:infoは2.0.0を使用し、--gcc:extraは2.1.0を使用するように相手ツールに要求しています。
これらの返答のフォーマットやバージョン指定のフォーマットなどは、この提案ではJSON Schemaの形で規定することを提案しています。
P2723R1 Zero-initialize objects of automatic storage duration
自動記憶域期間の変数が初期化されない場合に常にゼロ初期化されるようにする提案。
以前の記事を参照
このリビジョンは、基本的なところは変わっていませんがR0から全体的に大きく書き直されています。特に、オプトアウト(未初期化のままにしておく)の方法についての検討や言語の変更ではない別の手段によって達成することについてなどが追加されています。
2月のイサクア会議におけるEWGのレビューでは、オプトアウトの方法としてはstd::uninitializedという特別なライブラリ変数によるものが好まれているようです。
P2724R0 constant dangling
現在ダングリング参照を生成しているものについて、定数初期化可能なものを暗黙的/明示的に定数初期化する提案。
この提案は、以前のP2658とP2623の提案から、定数初期化関連の部分をマージするものです。それぞれについては以前の記事を参照
- P2623R0 implicit constant initialization - WG21月次提案文書を眺める(2022年07月)
- P2658R0 temporary storage class specifiers - WG21月次提案文書を眺める(2022年10月)
ほとんど定数と同等でありながら定数ではないためにふとした使い方の間違いでダングリング参照を生成し安全性を損ねているケースがC++のあちこちで見られます。そのような定数とみなせるものを定数初期化(コンパイル時に初期化)することで静的ストレージに配置し、ダングリング参照を回避するのがこの提案の目的です。
std::string_view sv1 = "hello world"; // ok // 共にダングリング参照となる std::string_view sv2 = "hello world"s; // UB、この提案によって暗黙定数初期化 std::string_view sv3 = constinit "hello world"s; // 明示的に定数初期化を行う
struct X { int a, b; }; const int& get_a(const X& x) { // 入力によってはダングリング参照を返す return x.a; } const int& a = get_a({4, 2}); // UB、aはダングリング参照となる a; // この提案によって修正されると4を保持
std::generator<char> each_char(const std::string& s) { for (char ch : s) { co_yield ch; } } int main() { auto ec = each_char("hello world"); // コルーチンから制御が戻った時点でダングリング参照となる。この提案によって暗黙定数初期化 for (char ch : ec) { std::print(ch); } }
この例で問題となっている個所は全て、この提案による暗黙定数初期化によってダングリング参照を生成しなくなります。
この提案はこれらの例を防止できるようになる一方で、同じようにダングリング参照を生成する全ての場合にそれを防止できるわけではありません。あくまで、一部のケースでダングリング参照の生成を抑止し、ダングリング参照の出現機会を減少させるものです。
また、この提案による暗黙/明示的定数初期化は定数初期化そのものは既存の仕組みを使用します。すなわち、クラス型の構築に使用されるコンストラクタがconstexprコンストラクタである(かつ、そのメンバをすべて定数式で初期化する)場合はこの提案の恩恵を受けられるようになります。それはすなわちconstexprの利点として安全性の向上が加わるようになり、クラスの初期化やそれに伴う処理をconstexpr対応させておくことの重要性が高まることになります。
P2725R1 std::integral_constant Literals
std::integral_constantの値を生成するユーザー定義リテラルの提案。
以前の記事を参照
このリビジョンでの変更は
などです。
この提案は、constexpr_tというより堅牢な定数型を追加して、それに対してユーザー定義リテラルを提供する方向(P2725R0)が好まれたため、そちらと統合された別の提案(P2781)に作業が引き継がれます。
P2728R0 Unicode in the Library, Part 1: UTF Transcoding
標準ライブラリにユニコード文字列の相互変換サポートを追加する提案。
ユニコードは文字コードの規格としてデファクトスタンダードとなっており、日常的にソフトウェアを使用する非常に多くのユーザーにとって重要なものです。しかし、C/C++は本質的にユニコードをサポートしていない数少ない主要なプログラミング言語となっています。
この提案はその状況の修正のために、まずUTF(ユニコードにおける文字表現)の相互変換機能を標準ライブラリに追加することを目指すものです。
この提案による変換インターフェースは次のような設計を選択しています
<ranges>との親和性。番兵や遅延ビューのサポートなど- (レガシーな)イテレータのサポート。任意のイテレータ型を考慮する
- ポインタのサポート。SIMDを用いるような最速の変換方法はポインタを介して行われる
- 変換はブラックボックスではない。入力文字列中の、エンコーディングの切れ目や壊れたエンコーディング個所などの状態をユーザーが調査できるユーティリティを提供する
- null終端された文字列を特別扱いしない
- 同じテキストを異なるタイミングでコードユニット(UTFエンコーディングの1単位の整数値)として表示したい場合とコードポイント(ユニコード空間上の32bit整数値)として表示したいことがよくある。そのため、変換イテレータは変換済みのコードユニットの元のデータにアクセスする簡便な方法を提供する。
この提案はそこそこ巨大ですが主に次のものから構成されています
また、これらのものは基本的にstd::uc名前空間に定義されています
提案文書より、サンプルコード
バッファからバッファへのパフォーマンス重視の変換
// UTF-8 -> UTF-16 へ変換する // バッファのサイズを同じにすることで、変換に余裕があるようにする char utf8_buf[buf_size]; char utf16_buf[buf_size]; char * read_first = utf8_buf; while (true) { // UTF-8シーケンスを読み取る(ネットワークなど) // 末尾に部分的なUTF-8シーケンスが現れうる char* buf_last = read_into_utf8_buffer(read_first, utf8_buf + buf_size); if (buf_last == read_first) continue; // 有効なUTF-8シーケンスを特定する(部分的なシーケンスを除外する) char* last = buf_last; auto const last_lead = std::ranges::find_last_if(utf8_buf, buf_last, std::uc::lead_code_unit); if (!last_lead.empty()) { auto const dist_from_end = buf_last - last_lead.begin(); assert(dist_from_end <= 4); if (std::uc::utf8_code_units(*last_lead.begin()) != dist_from_end) { last = last_lead.begin(); } } // std::ranges::copy()と同じインターフェースで、変換しながらコピーする auto const result = std::uc::transcode_to_utf16(utf8_buf, last, utf16_buf); // 変換結果(UTF-16)を使って何かする send_utf16_somewhere(utf16_buf, result.out); // 末尾にあった部分的なシーケンスを次の処理バッファの先頭へ移動 read_first = std::ranges::copy_backward(last, buf_last, utf8_buf).out; }
オブジェクトからのなるべく高速な変換
struct my_string; // ポインタインターフェースを持たない文字列型 // UTF-8文字列の取得 my_string input = get_utf8_input(); // 出力バッファ std::vector<uint16_t> input_as_utf16(input.size()); // Reserve some space. // UTF-16 -> UTF-8 変換 auto const result = std::uc::transcode_to_utf16(input, input_as_utf16.data()); input_as_utf16.resize(result.out - input_as_utf16.data()); // Trim unused space.
オブジェクトからのなるべく簡単な変換
struct my_string; // ポインタインターフェースを持たない文字列型 // UTF-8文字列の取得 my_string input = get_utf8_input(); // 出力バッファ std::vector<uint16_t> input_as_utf16; // UTF-16 -> UTF-8 変換 std::ranges::copy(input, std::uc::from_utf8_back_inserter(input_as_utf16));
// UTF-16シーケンスを受ける関数テンプレート template<class UTF16Iter> void process_input(UTF16Iter first, UTF16Iter last); // UTF-8文字列の取得 std::string input = get_utf8_input(); // std::stringにUTF-8文字列を詰めて使用 // UTF-8 -> UTF-16 変換しつつ、関数に渡す(遅延評価) process_input(std::uc::utf_8_to_16_iterator(input.begin(), input.begin(), input.end()), std::uc::utf_8_to_16_iterator(input.begin(), input.end(), input.end())); // viewの利用によるさらなる簡単化 auto const utf16_view = std::uc::as_utf16(input); process_input(utf16_view.begin(), utf16.end());
既存のRange APIへのアダプト
// UTF-16シーケンスを受ける関数テンプレート template<class UTF16Range> void process_input(UTF16Range && r); // UTF-8文字列の取得 std::string input = get_utf8_input(); // std::stringにUTF-8文字列を詰めて使用 // UTF-8 -> UTF-16変換しつつ、関数に渡す(遅延評価) process_input(std::uc::as_utf16(input));
この例では(おそらくWindows環境で頻出する)UTF-8からUTF-16への変換のみを扱っていますが、提案としてはUTF-8/16/32の全ての相互変換を含んでいます。
この提案の提供する機能は、Boost.TextとしてBoostに提案中のライブラリの一部として5年ほどの実装経験があります。
P2729R0 Unicode in the Library, Part 2: Normalization
標準ライブラリにユニコード文字列の正規化サポートを追加する提案。
この提案は↑の提案に引き続いて、ユニコードサポート改善のためにユニコード正規化機能を標準ライブラリに追加しようとするものです。
ユニコードの正規化とは、同じ意味を持つ複数の文字(コードポイント)をある1つの文字(コードポイント)に変換することを言います。例えば、半角全角や、丸文字などを対応する通常の文字へ変換します。
この提案による正規化インターフェースは次のような設計を選択しています
<ranges>との親和性。番兵や遅延ビューのサポートなど- (レガシーな)イテレータのサポート。任意のイテレータ型を考慮する
- ポインタのサポート。SIMDを用いるような最速の変換方法はポインタを介して行われる
- 変換はブラックボックスではない。入力文字列中の、エンコーディングの切れ目や壊れたエンコーディング個所などの状態をユーザーが調査できるユーティリティを提供する
- null終端された文字列を特別扱いしない
- UTFの形式ごとに最適なアルゴリズムへのディスパッチ
- パフォーマンスのため
- 使用するUTF形式が変わった時でも、同じコードを利用することができるようにする
- 煩雑なユニコードの詳細を隠蔽する、より高レベルの抽象化を提供する
この提案は主に次のものから構成されています
- ユニコードバージョン定数
- ストリームセーフな操作
- ストリームセーフなアルゴリズム
- ストリームセーフなイテレータ
- ストリームセーフな
view - APIを制約するためのコンセプト
- サポートする正規化形式の列挙型
- 汎用の正規化アルゴリズム
- 一度に複数の出力を行うアルゴリズム
std::stringのための正規化操作
また、これらのものは基本的にstd::uc名前空間に定義されています
提案文書より、サンプルコード
コードポイントのシーケンスをNFCに正規化する
std::string s = /* ... */; // std::stringにUTF-8文字列を詰めて使用 // 正規化されていないことを確認 assert(!std::uc::is_normalized(std::uc::as_utf32(s))); // 出力バッファ char * nfc_s = new char[s.size() * 2]; // 正規化はコードポイントで動作するため、まずUTF32に変換する(as_utf32()によって)必要がある auto out = std::uc::normalize<std::uc::nf::c>(std::uc::as_utf32(s), nfc_s); // null終端 *out = '\0'; // 正規化されていることを確認 assert(std::uc::is_normalized(nfc_s, out));
string-likeなコンテナへ出力する
std::string s = /* ... */; // std::stringにUTF-8文字列を詰めて使用 // 正規化されていないことを確認 assert(!std::uc::is_normalized(std::uc::as_utf32(s))); // 出力先 std::string nfc_s; nfc_s.reserve(s.size()); // 正規化はコードポイントで動作するため、まずUTF32に変換する(as_utf32()によって)必要がある std::uc::normalize_append<std::uc::nf::c>(std::uc::as_utf32(s), nfc_s); // 正規化されていることを確認 assert(std::uc::is_normalized(std::uc::as_utf32(nfc_s)));
この場合、normalize_append()によってある程度纏めて出力されることで、より高速になる可能性があります。
正規化を維持したまま正規化済み文字列を更新する
std::string s = /* ... */;// std::stringにUTF-8文字列を詰めて使用 // 正規化されていることを確認 assert(std::uc::is_normalized(std::uc::as_utf32(s))); // 挿入したい文字列(正規化されていないかもしれない std::string insertion = /* ... */; // 正規化しながら挿入 normalize_insert<std::uc::nf::c>(s, s.begin() + 2, std::uc::as_utf32(insertion)); // 正規化されていることを確認 assert(std::uc::is_normalized(std::uc::as_utf32(nfc_s)));
この提案の提供する機能もまた、Boost.TextとしてBoostに提案中のライブラリの一部として5年ほどの実装経験があります。
P2730R0 variable scope
ローカルスコープの一時オブジェクトの寿命を文からスコープまで延長する提案。
この提案は、以前のP2658とP2623の提案から、ローカル一時オブジェクトの寿命延長関連の部分を抽出したものです。それぞれについては以前の記事を参照
- P2623R0 implicit constant initialization - WG21月次提案文書を眺める(2022年07月)
- P2658R0 temporary storage class specifiers - WG21月次提案文書を眺める(2022年10月)
ただし、この提案ではP2658に含まれていたvariable_scopeなどの指定は含まれておらず。P2623に加えてP2658に含まれていたvariable_scopeと同等の寿命延長を提案しています。
次のような関数がああったとき
const std::string& f(const std::string& defaultValue) { return defaultValue; }
この関数の内部からは、引数のdefaultValueがどういう寿命を持つのかは分かりません。それの参照を戻り値で返すことには問題がありますが、それは必ずしもおかしいことでもありません。
このf()に一時オブジェクトを渡して呼び出すと、暗黙的なスコープが追加される形になります。
int main() { // 先ほどのf()のこのような呼び出しは { f("Hello World"s); } // このような呼び出しとなる { { auto anonymous = "Hello World"s; f(anonymous); } } }
この時、戻り値を受けていると
int main() { // 先ほどのf()のこのような呼び出しは { const std::string& value = f("Hello World"s); } // このような呼び出しとなる { const std::string& value; // 実際には初期化子が必要 { auto anonymous = "Hello World"s; value = f(anonymous); } } }
コンパイラは通常のC++としてはかけないコードに書き換えたかのようにコンパイルします。これによって、一時オブジェクトanonymousのスコープは他の変数とは異なることになり、プログラマの期待とも一致しなくなります。
この時、最も自然なのはanonymousのスコープが戻り値を受けているvalueと同じになることです。この場合のvalueのスコープのことをこの提案ではブロックスコープと呼び、関数呼び出し時のこのような一時オブジェクトの寿命を現在の文からブロックスコープまで延長することを提案しています。
これによって、参照セマンティクスを持つクラスによっておこるダングリング参照も抑制されます。
int main() { std::string_view sv = "Hello World"s; ... std::cout << sv; // ok }
ただしこのような場合には、一時オブジェクトのブロックスコープへの寿命延長が機能しない場所があります
std::string_view sv = "initial value"s; if (randomBool()) { sv = "if value"s; } else { sv = "else value"s; }
この場合、"if value"sや"else value"sの寿命はif節とelse節のそれぞれのブロックスコープまでは延長していますが、svに束縛することによってその外側に持ち出されてしまうと依然としてダングリング参照となります。
この場合に、これらの一時オブジェクトが変数svと同じスコープを持っていればこの問題は解決されます。この提案ではそのようなスコープのことを変数スコープ(variable scope)と呼び、一時オブジェクトが直接別の変数に代入される場合にその寿命を代入先の変変数スコープまで延長することを提案しています。
これによって、関数内部で発生しうる直接的なダングリング参照の発生を抑制します。
結局、この提案は次の2つのことを提案します
- ローカル変数の一時変数は変数スコープを取得する
- 関数引数の一時変数はブロックスコープを取得する
これと同等なことは、例えばCの複合リテラルに見ることができますが、C++においてもconst auto&やauto&&による一時オブジェクト寿命延長時に行われているため、実装にあたって大きな問題があるわけではないと思われます。
P2732R0 WG21 November 2022 Kona meeting Record of Discussion
2022年11月7-12日にハワイのKonaで行われた、WG21全体会議の議事録。
N4933との違いはよく分かりません。
P2733R0 Fix handling of empty specifiers in std::format
std::format()のフォーマット文字列内の置換フィールドが空である場合に、パースを行わなくてもよくする提案。
フォーマット文字列内の置換フィールド{}には{:+3}などのように出力を調整するためのオプション(フォーマット引数)を指定することができます。この解析のためにはstd::formatter<T>::parse()が使用され、ユーザー定義型に対するフォーマットのカスタマイズではこの関数でオリジナルオプションをパースすることで自作の型にオリジナルのオプションを指定してフォーマットすることができるようになります。
とはいえ、多くの場合はオプション無しの{}のまま使用されることが多いようで、その場合に、現在の規定はフォーマット引数の有無にかかわらずstd::formatter<T>::parse()を呼び出すことを要求しています。
struct S {}; // ↑のSをstd::format()可能にする template <> struct std::formatter<S> { auto parse(format_parse_context& ctx) { return ctx.begin(); } auto format(S, format_context& ctx) const { return ctx.out(); } }; int main() { auto s1 = fmt::format("{}", S()); // (1) フォーマット引数指定なし auto s2 = fmt::format("{:}", S()); // (2) フォーマット引数は空 }
(1)と(2)の例はいずれもフォーマット引数は存在していないため、parse()を呼び出す意味がありません。{fmt}ライブラリでの実装経験によれば、このオーバーヘッドは実際にrangeのフォーマットにおいて悪影響を与えていることが確認できたようです。それはフォーマット文字列のコンパイル時検査等、parse()を呼び出す必要のある他のコンテキストにおいても同様である可能性があります。
また、C++23のrangeではフォーマットオプション中で:...のようにして要素型に対するオプション指定を行うことができ、そこでも同様の問題が発生します。
int main() { auto s3 = std::format("{}", std::vector<S>(2)); // vector : なし、S : なし auto s4 = std::format("{:}", std::vector<S>(2)); // vector : 空、 S : なし auto s5 = std::format("{::}", std::vector<S>(2)); // vector : 空、 S : 空 // ^ 要素型Sに対する空のフォーマット引数指定 }
これはいずれのケースでも、外側のstd::vectorと要素型のSに対してフォーマットオプションを指定していません。現在の規定ではフォーマットオプションの指定なしと空は区別されていたようですが、rangeの要素型に対するフォーマットオプション指定においてはパースの都合上(ほぼ:の有無だけで要素型に対するフォーマットオプション有無が決まるので)この2つの違いを区別することができません。そのため、この提案ではこの2つのケースは同等に扱われるようになります。
この問題はLWG Issue 3776で指摘され、その解決のためには提案が必要になるということで、この提案が書かれました。この修正は、省略することを許可するものの必須ではない、となるようになっています。
また、類似の問題の解決として、std::tupleに対するフォーマット時に要素型に対するデバッグ出力を有効化できていなかったバグの修正も同時に行われます。
std::tupleに対するフォーマットでは要素型に対するオプション指定が無いため、要素型に対するオプションのparse()は常に省略されていました。一方で、要素型の文字/文字列型に対してデバッグ出力オプション(?)が常に有効になっており、そのために要素型のフォーマットオプションのparse()でstd::formatter::set_debug_format()の呼び出しが必要になる、というある種の矛盾状態に陥っていました(本来、set_debug_format()はparse()内で?オプションをパースしたときに呼び出されることでデバッグ出力を有効化します)。
この提案ではこれを解決し、std::tupleに対するフォーマットではネストした要素型でデバッグ出力が可能な場合にset_debug_format()を正しく呼ぶように規定を修正します。
auto s = fmt::format("{}", std::make_tuple(std::make_tuple('a'))); // Before : ((a)) // Aftter : (('a'))
std::format()- cpprefjpstd::formatter::set_debug_format()- cpprefjp- LWG Issue 3776. Avoid parsing format-spec if it is not present or empty
- P2733 進行状況
P2734R0 Adding the new 2022 SI prefixes
2022年に追加された新しいSI接頭辞に対応するstd::ratio特殊化を追加する提案。
<ratio>ヘッダにはコンパイル時有理数型std::ratioと、SI接頭辞(ミリとかマイクロ、キロやギガなど)に対応するその事前定義型エイリアスが定義されています。
SI接頭辞は長らく更新されていませんでしたが、2022年に新しく次の4つが追加されました
- quecto : $10^{-30}$
- ronto : $10^{-27}$
- ronna : $10^{27}$
- quetta : $10^{30}$
この提案は、この4つに対応する設定済みのstd::ratioエイリアスを追加するものです。名前はSI接頭辞名と同じで提案されています。
ただし、既存のstd::yoctoやstd::yotta等と同様に、itmax_t型で値を表現可能な場合(64bitを超える幅の整数型を提供していない場合)は定義しなくてもよいようにされています。
P2736R0 Referencing the Unicode Standard
ISO 10646(UCS)の代わりにユニコード標準を参照するようにする提案。
現在のC++はユニコードのサポートのためにユニコード標準とISO 10646の両方を参照しています。この2つはほとんど同じ内容ではあるものの別々の規格です。
ユニコード標準は単に文字コードを定めるだけでなく、正規化や比較、大文字と小文字の変換など、ユニコード文字を扱うためのアルゴリズムも含んでいるなど、ISO 10646に比べてより広い規格になっています。また、ユニコード標準の定め提供するそれらのものは、参照するユニコード標準のバージョンを厳密に指定しているため、異なるバージョンでは動作が保証されませんが、ISO 10646とユニコードのリリースサイクルが異なることからそれを厳密に一致させることが困難になります。
また、ISO 10646とユニコード標準では使用する用語にも微妙に差異があり、その違いや影響について評価するためにSG19(ユニコードに関する作業部会)の時間を無駄に消費しています。さらに、ユニコード標準は関連するユニコードデータをツールに使用しやすいようなフォーマットで提供していますが、ISO 10646はただのPDFであり、実装者にとってもISO 10646対応の検証などは重荷になっています。
C++では、言語とライブラリの両方でユニコードのサポートを進めており、そこではユニコードの参照が必要となります。今後それを進めていくにあたってISO 10646対応のために(規格化と実装の)時間を消費するのを回避し、標準の依存関係を減らして標準を明確化するために、ISO 10646への参照を完全にユニコードへの参照で置き換えようとする提案です。
この提案は標準の文書からISO 10646の参照を削除し、それに関連する文言をユニコード標準を参照するように書き換えるだけのものなので、実装には影響はありません。
ただ、__STDC_ISO_10646__という事前定義マクロだけは影響を受けますが、これについてはユニコードの任意のコードポイント値をwchar_tオブジェクトを格納できることのような定義にし(実質現在と変更はない)、その値を実装定義とすることでISO 10646への参照を回避するようにしています。
- ISO/IEC 10646 - Wikipedia
__STDC_ISO_10646__| Programming Place Plus C言語編 標準ライブラリのリファレンス- P2736 進行状況
P2737R0 Proposal of Condition-centric Contracts Syntax
新しいキーワードによる条件中心な契約構文の提案。
現在検討中の契約プログラミングのための構文は、C++20で削除された時から変わらず属性を利用したものが主流です。ただし、これはまだ確定したものではなく、他にもクロージャを意識した構文(P2461R1)が提案されています。
| 属性 | クロージャ |
|---|---|
int select(int i, int j) [[pre: i >= 0]] [[pre: j >= 0]] [[post r: r >= 0]] { [[assert: _state >= 0]]; if (_state == 0) return i; else return j; } int pre; // OK int assert; // OK int post; // OK |
int select(int i, int j) pre{i >= 0} pre{j >= 0} post(r){r >= 0} { assert{_state >= 0}; if (_state == 0) return i; else return j; } int pre; // OK int assert; // ??? int post; // OK |
この提案では3つ目の候補として、precond, postcond, incond(順に、事前条件、事後条件、アサート)の3つのキーワードを用いた条件中心な構文を提案するものです。
| 属性 | この提案 |
|---|---|
int select(int i, int j) [[pre: i >= 0]] [[pre: j >= 0]] [[post r: r >= 0]] { [[assert: _state >= 0]]; if (_state == 0) return i; else return j; } int pre; // OK int assert; // OK int post; // OK |
int select(int i, int j) precond(i >= 0) precond(j >= 0) postcond(result >= 0) { incond(_state >= 0); if (_state == 0) return i; else return j; } int precond; // ERROR int incond; // ERROR int postcond; // ERROR |
この提案はP2521R2にある契約機能のMVPについて次の変更を加えます
- アサーションの構文を
assertからincondに変更 precond, postcond, incondを完全な(文脈依存ではない)キーワードとして追加- 条件指定は
()の中に式を指定するprecond(expr), incond(expr), postcond(expr)
- 事後条件(
postcond)では、定義済みの変数resultによって戻り値を参照する変数が暗黙的に導入される
incondは事前条件(処理の前に満たすべき条件)と事後条件(処理の後で満たすべき条件)からの類推で、処理の途中で満たすべき条件を表す造語です。これは、2分木の探索順序を表す3つの単語preorder, inorder, postorderを参考にして作られた言葉でもあります。
アサーション(assert)を置き換えたい動機は次のようなものです
- assertionは他の2つ(precondition、postcondition)と一貫していない
- 条件は満たさないことを違反したと言うが、アサーションは失敗したと言われる
- 3つの事柄の互いの関連性が明確であることが重要
- 既存のアサーションとの混同
assertはキーワードとして登録できない- 少なくともC assertと競合する
incondというワードはこの3つのいずれの問題もクリアしている新しい造語です。
この新しいキーワードはACTCD19というC/C++コードベース調査で1000件程度しかヒットしないため新しいキーワードとして使用できる、と主張しています(使われ方にもよりますが1000件は多いのではと思わないでもないですが)。
- P2461R0 Closure-based Syntax for Contracts - [C++]WG21月次提案文書を眺める(2021年10月)
- P2487R0 Attribute-like syntax for contract annotations - [C++]WG21月次提案文書を眺める(2021年11月)
- P2521R2 Contract support - Working Paper - [C++]WG21月次提案文書を眺める(2022年03月)
- 二分木のpre-order, in-order, post-orderの簡単でわかりやすい説明 - CTOを目指す日記
- P2737 進行状況
P2738R0 constexpr cast from void*: towards constexpr type-erasure
定数式において、void*からポインタ型への変換を許可する提案。
背景やモチベーションは後の方のP2747R0と共通するのでそちらをご覧ください。
この提案では主に、std::formatのconstexpr対応のために、型消去ユーティリティをコンパイル時に使用可能とすることを目的としています。
#include <string_view> struct Sheep { constexpr std::string_view speak() const noexcept { return "Baaaaaa"; } }; struct Cow { constexpr std::string_view speak() const noexcept { return "Mooo"; } }; // 型消去ユーティリティの実装例 // speak()メンバ関数をもつ任意の型のviewとなる class Animal_View { private: // オブジェクトの型を消去して保持するポインタ const void *animal; // 関数ポインタ std::string_view (*speak_function)(const void *); public: template <typename Animal> constexpr Animal_View(const Animal &a) : animal{&a} // オブジェクトポインタをvoid*へキャストし保存(これは定数式で行える) , speak_function{[](const void *object) { // 実際に渡されたAnimal型をラムダ式内に保存し、ラムダ式は関数ポインタへ変換して保存 // 実際の型情報を用いてvoid*からAnimal*を復帰するので、常に正しいキャスト return static_cast<const Animal *>(object)->speak(); // ここをコンパイル時に実行できない }} {} constexpr std::string_view speak() const noexcept { // このクラスが正しく構築されていれば、この呼び出しは常に正しく元のオブジェクトをvoid*から復帰させてspeak()メンバを呼び出す return speak_function(animal); } }; // Animal_Viewの要求するインターフェースを持つ任意の型のオブジェクトを渡すことができる std::string_view do_speak(Animal_View av) { return av.speak(); } int main() { constexpr Cow cow; // cannot be constexpr because of static_cast [[maybe_unused]] auto result = do_speak(cow); return static_cast<int>(result.size()); }
このような型消去ユーティリティがやっていることは、ほとんど仮想関数によるポリモルフィズムと同様です。その大きな違いは、要求するインターフェースに準拠するクラスは必ずしもこれにアダプトするための作業をする必要がなく(非侵入的であり)、個別のクラスごとに仮想関数テーブルを必要としないことにあります。そして、このような型消去は、テンプレートのインスタンス化を抑制しコンパイル時間を削減するなどのメリットがあります。
これと同様のアプローチは、std::format()の実装において使用されている(フォーマット対象引数の文字列化のために)ほか、std::function_refの実装においても使用されます。
ただし、この例を見てわかるように、このような型消去の肝はオブジェクトポインタをvoid*へ落とした後で必要になったタイミングでvoid*から復帰するところにありますが、void*からポインタ型へのキャストは現在定数式で明示的に禁止されているため、これらの型消去テクニックはコンパイル時に使用可能ではありません。
この提案は、この制限を取り除くことでこのような型消去をコンパイル時に使用可能とし、std::format()やstd::function_refをconstexpr対応するための障害を取り除くものです。
ただし、ここで提案されているのは、void* -> T*の変換時にそのポインタが正しくTのオブジェクトを指している場合にのみ変換を許可することで、ポインタ相互互換性(pointer interconvertible)や全く異なるポインタへの変換を許可するものではありません。
現在のほとんどのコンパイラの定数式の実装においては、未定義動作排除などのためにポインタとそれが指すオブジェクトの状態をその実行に当たって追跡しています。そのためvoid*からのキャスト時にその正しさのチェックを行うことは可能であり、提案ではClang/GCC/MSVC/EDGの実装者からこの提案の実装が問題ない事を確認しています(筆者の方はClangで実装して確認しているようです)。
P2739R0 A call to action: Think seriously about "safety" then do something sensible about it
C++の安全性向上のための行動を呼びかける文書。
2022年11月ごろに出されたNSA(アメリカ国家安全保障局)のレポート(Software Memory Safety - Department of Defense)において、C++はCとともにメモリ安全な言語ではなく他のメモリ安全な言語に移行することが望ましい、と名指しされました。この文書はそれを受けて、筆者の方(Bjarne Stroustrup先生)のこれまで及びこれからのC++の安全性向上のための取り組みを説明し、C++標準化委員会としても行動していくことを促すものです。
取り組みとしてはコアガイドラインの整備やそれをベースとした静的解析ツールの整備、コアガイドライン基準の静的解析アノテーションの提案(P2687R0)などが挙げられています。
NSAの文書は安全をメモリ安全性に限定していますが安全性とはそれだけではなく、安全性を実現するための方法も一通りではありません。また、安全性は重要ではありますが誰もが安全性だけを重視するわけではなく、安全性よりも他の事項(例えばパフォーマンス)が重視される場合もあります。また、モダンなコードだけを安全にしたとしても、現在の多くのC++コードがそうなるわけではなく、それらの過去のコードは安全なコード(あるいは安全なプログラミング言語)から呼び出されて使用されます。
安全性の問題を放置すればC++のコミュニティの大部分が損なわれ、委員会で行われている多くの作業が無駄になってしまいますが、安全性だけを重視しすぎても同様の結果を招くことになります。
この文書では、まず安全性の問題と考えられることのリストを作成し、P2687R0の枠組みの中でそれをどのように改善できるかを考えていくことを提案しています。これはまた、Bjarne先生の今後の方針でもあります。
- Software Memory Safety - Department of Defense
- P2687R0 Design Alternatives for Type-and-Resource Safe C++ - WG21月次提案文書を眺める(2022年10月)
- P2739 進行状況
P2740R0 Simpler implicit dangling resolution
関数からローカル変数の参照を返してしまうケースをコンパイルエラーにする提案。
C++23では、P2266R3の採択によって一部のローカル変数の参照を返す関数がコンパイルエラーとなるようになります。
// 参照を返す関数 int& f(bool b, int i) { static int s; if (b) { return s; // OK } else { return i; // error : C++23から } } // reference_wrapperを返す関数 std::reference_wrapper<int> g() { int w; return w; // error : C++23から }
この変更は画期的なものですが、P2266の主目的はあくまで暗黙のムーブ対象の拡大にあったのでこれは副次的な効果に過ぎず、完全なものではありません。例えば、上記それぞれの場合においての参照に当たるものをreturnで返す場合は、その参照先がローカル変数でもエラーになりません。
この提案はここからさらに進んで、追加でいくつかの場合もコンパイルエラーにしようとするものです。
1つ目は参照ではなくポインタを返す関数の場合です。
int* h(bool b, int i) { static int s; if (b) { return &s; // OK } else { return &i; // error: iは戻り値のポインタよりも先に寿命が尽きる } }
(ここでのerrorとはエラーにすることを提案しているという意味で、以降も同様です)
これと同様のことは、関数の本体内でも起こり得ます。
void h(bool b, int i) { int* p = nullptr; if (b) { static int s; p = &s; // OK } else { int i = 0; p = &i; // error: iは戻り値のポインタよりも先に寿命が尽きる } // ... }
このために、この提案では次のようなルールを提案しています
ポインタまたは参照の寿命が尽きる前にその参照するオブジェクトの寿命が尽きる場合、オブジェクトのアドレスをポインタまたは参照に代入できない
ただしこれは、一段階の間接化だけを対象としています。つまり、すでに何かを参照している参照/ポインタを新しい参照/ポインタに代入する(returnする)ような場合はこのルールに該当しません。それをしようとすると、コンパイラはローカル変数と参照/ポインタの依存関係グラフを作成することになり、これはコンパイル時間増大と実装の複雑化を招きます。
次に、ラムダ式やコルーチンがローカル変数を参照キャプチャしていて、それを内包するオブジェクトを返す場合をコンパイルエラーとします。
auto lambda() { int i = 0; return [&i]() -> &int { return i; }; // error: iは戻り値のラムダよりも先に寿命が尽きる } auto coroutine() { int i = 0; return [&i]() -> generator<int> { co_return i; }; // error: instance `i` dies before the returned coroutine }
このために、この提案では次のようなルールを提案しています
ローカル変数へのポインタ/参照をキャプチャするラムダ式またはコルーチンを関数から返すことはできない
これは前項の提案から一段階だけ進んだ間接化の中でも言語機能による特殊なケースを処理するものです。これ以上の間接化を処理しようとすることは、前項と同様の理由により提案していません。
コンパイラは、関数が戻り値としてオブジェクトを返すのかその参照(ポインタ)を返すのかを知っていて、その関数内でのローカル変数とそれを参照する(一段階の)ポインタや参照を認識しています。二段階以上の間接化を処理しようとするとローカル変数の依存関係グラフを構築する必要が出てきてしまいますが、一段階の間接化(と一部の特殊ケース)だけなら全てのコンパイラが簡単に検証できるはずです。
この提案によって、追加の静的解析ツールを必要とすることなくC++の言語内で多くのダングリング参照を防止できるようになります。完全なものではありませんが、この修正は大きな改善です。また、Cコードを(この提案を実装した)C++としてコンパイルすることで、Cのポインタの安全性を検証することもできるなど、C/C++エコシステム全体の改善に貢献することができます。
P2741R0 user-generated static_assert messages
static_assertの診断メッセージ(第二引数)に、コンパイル時に生成した文字列を指定できるようにする提案。
static_assertの診断メッセージには現在文字列リテラルを直接指定することしかできず、定数式で生成した任意の文字列を指定することができません。これによって、コンパイル時の診断メッセージの柔軟さが損なわれています。
この提案は、static_assertの診断メッセージとして定数式で生成された文字列を指定してエラーメッセージとして出力可能とすることで、static_assertによるコンパイル時のエラー報告を改善しようとするものです。
この提案が通れば、将来的にstd::format()を使用可能となるでしょう。
static_assert(sizeof(S) == 1, std::format("Unexpected sizeof: expected 1, got {}", sizeof(S)));
ただし、この提案ではstatic_assertの診断メッセージに指定可能なものを広げることをだけを念頭に置いていて、std::format()のconstexpr対応については提案していません。
また、この提案によって指定可能になる文字列とはstd::stringを指すのではなく、次のような特性を持つ型の値を文字列と見做して出力可能とすることを提案しています。
.size()メンバ関数を持つ- 戻り値型は整数型
.data()メンバ関数を持つ- 戻り値型は
char*かchar8_t*のどちらか(CV修飾はあってもいい)
- 戻り値型は
- 診断メッセージに指定されたオブジェクトを
msgとすると、[msg.data(), msg.data() + msg.size())は有効な範囲であること
std::stringだけでなく、std::string_viewやstd::vector<char>なども使用可能です。
P2742R0 indirect dangling identification
戻り値の参照やポインタの有効期間が別の変数の生存期間に依存していることを表明する属性の提案。
この提案は、関数の戻り値で発生するダングリング参照の防止・削減を目的としており、上の方で出ていたP2724R0やP2730RO、P2740R0とよく似た目的で同じ作者による提案です。
この提案では、parameter_dependencyという新しい属性を提案していて、これはdependent引数として文字列でその有効期間が他に依存しているものを指定し、providers引数に文字列で依存先のものを指定します。"return"で戻り値を指定することができるほか、依存先として"this"で*thisオブジェクトを指定できます。
[[parameter_dependency(dependent{"return"}, providers{"this", "left", "right", "first", "second", "last"})]]
providers引数は文字列の配列で、dependent1つにつき複数の依存先を指定できます。
parameter_dependency属性は関数(フリー関数及びメンバ関数)に指定するもので、これによってdependentに指定したものの有効期間がprovidersに指定したものの生存期間に依存していることを表明します。
// 戻り値の参照の有効期間は引数iに依存している [[parameter_dependency(dependent{"return"}, providers{"i"})]] int& f(bool b, int& i) { static int s; if (b) { return s; } else { return i; } } // 戻り値の参照の有効期間は引数left/rightに依存している [[parameter_dependency(dependent{"return"}, providers{"left", "right"})]] int& g(bool b, int& left, int& right) { if (b) { return left; } else { return right; } } class Car { private: Wheel wheels[4]; public: // 戻り値の参照の有効期間は*thisオブジェクトに依存している [[parameter_dependency(dependent{"return"}, providers{"this"})]] const Wheel& getDriverWheel() const { return wheels[0]; } }
この属性は参照とオブジェクトの依存関係を手動で表明するものであって、その依存関係を確立し参照が参照しているオブジェクトの生存期間を延長するものではありません。
このような属性はライブラリのAPIにおいてドキュメントや仕様記述として使用できます。ヘッダオンリーなライブラリであれば静的解析など他の手段によってその依存関係を知ることができるかもしれませんが、翻訳単位が分かれている場合のABI境界の関数宣言においてはこのような属性の有効性は高まります。
また、コンパイラや静的解析ツールがこの属性を認識することで、ライフタイム解析の手助けをすることができます。例えば先ほどのCar::getDriverWheel()では
const Wheel& f() { Car local; return local.getDriverWheel(); // error? }
この属性が無い(無視される)場合、getDriverWheel()から返される参照の有効期間は分からず、追加の解析なしではこの例が正しいのかどうかを判断できません(ABI境界の向こう側に実装がある場合、そのような解析は不可能かもしれない)。しかし、parameter_dependency属性によって戻り値は*thisの生存期間に依存していることがわかるため、*thisすなわちローカルのCarオブジェクトlocalの寿命に依存していることがわかり、コンパイラや静的解析器はこの関数の外側にその戻り値を持ち出すのは間違っていることを認識できるかもしれません。
上の方のP2740R0ではローカル変数依存関係の解析が必要となるため困難だった多段階の間接化によるダングリング参照生成も、この提案による属性指定によって手動ではありますがコンパイラが認識可能になるかもしれません。また、これはポインタでも機能し、C23からは属性構文がC++と同等になったため、この属性をCとの共通コードに書くこともでき、間接的にCコードの安全性向上にも役立つ可能性があります。
P2743R0 Contracts for C++: Prioritizing Safety - Presentation slides of P2680R0
P2680R0の紹介と解説スライド。
P2680R0は、C++をより安全な言語に進化させていくことの第一歩として契約プログラミングに焦点を当て、副作用やUBの扱いについて議論のある契約条件式の実行モデルをconstexprの実行モデルと同じものにしようとするものです。
このスライドはSG21のメンバに向けてその内容を紹介するとともに背景などを解説するもののようです。
- P2680R0 Contracts for C++: Prioritizing Safety - WG21月次提案文書を眺める(2022年10月)
- P2700R0 Questions on P2680 “Contracts for C++: Prioritizing Safety” - WG21月次提案文書を眺める(2022年11月)
P2746R0 Deprecate and Replace Fenv Rounding Modes
浮動小数点環境の丸めモード指定関数std::fesetround()を非推奨化して置き換える提案。
std::fesetround()には次のような問題があり、移植可能でも効果的でもないようです
FENV_ACCESSを#pragmaしていない場合、コンパイラは丸めモードを無視した最適化を実行する。しかし、そのマクロはC++ではサポートされていないため、C++ではfesetround()が正しく動作することを保証できない- 丸めモードを変更した状態で、標準の数学関数やユーザー定義関数を呼び出した結果は一貫性が無く、予測可能ではない
- 丸めモードはコードの領域に対して指定するのではなく、それぞれの演算に対して指定する必要がある
- 様々な丸めモードを試すことで浮動小数点数の誤差をある程度把握することができるが、3と同じ理由によりそれはランダムに結果を擾乱するよりもわずかにマシ程度のもの
- また、プログラムロジックが丸めモードに依存している場合やコードが丸めモードを変更している場合、このアプローチはうまくいかない
- コンパイラは定数式においては丸めモードを無視する傾向にあり、プログラマが実際の結果を予測することを困難にしている
- もし丸めモードを適用したうえで結果を確定させたいならば、定数式においても丸めモードを考慮しなければならない。しかし、これはCでは禁止されている
- 特にC++では、そもそも正しく丸められていない演算に対する丸めモードの意味が不明確。IEEE標準は正しい丸めを要求しているが、C++実装は適合していない
CのFENV_ROUNDもstd::fesetround()よりは良い振る舞いをしますが、結局上記のいずれかは問題となります。
これらの理由により、std::fesetround()は実際にはほとんど使用されていません。想定されるユースケースは区間演算や、それのように計算結果の上限と下限を得る必要がある場合ですが、そのような用途はあまり一般的ではありません。また、fenv.hはC++と相性が悪く、Cの改訂に追いついておらず、Cでさえその有用性が疑問視されているようです。
特に、この機能は数学関数のconstexpr化の作業の際に多くの問題を引き起こしており、全ての数学関数はfesetround()による暗黙の丸めモード引数を持ってしまっており、この値はコンパイラによって予測不可能となるため、ユーザーが期待する最適化を混乱させることになります。C++では、数学ライブラリが丸めモードを尊重すべきかどうか、あるいは非標準の丸めモードにおいて合理的なことを行うべきかが不透明です。
このような理由から、この提案ではstd::fesetround()とstd::fegetround()を非推奨にしたうえで、IEEE標準の指定する正しい丸めに従った浮動小数点演算結果を生成する代替機能を追加することを提案しています。
提案する代替機能はcorrectly_roundedというクラスで、メンバ関数としてIEEE準拠の浮動小数点演算を行う各種関数が提供されます。
template<floating_point F> class correctly_rounded { explicit correctly_rounded(F plain_value); // Other expected constructors, destructor, assignment; F to_plain() const; ... // IEEE準拠の四則演算 correctly_rounded<F> operator+(correctly_rounded<F> y) const; template<float_round_style r = round_to_nearest> correctly_rounded<F> add(correctly_rounded<F> y) const; correctly_rounded<F> operator*(correctly_rounded<F> y) const; template<float_round_style r = round_to_nearest> correctly_rounded<F> multiply(correctly_rounded<F> y) const; ... // IEEE準拠の数学関数 template<float_round_style r = round_to_nearest> correctly_rounded<F> sqrt() const; ... }; correctly_rounded<double> operator"" _d_round_to_nearest(const char *); correctly_rounded<double> operator"" _d_round_toward_infinity(const char *);
correctly_rounded<F>は浮動小数点数型Fの値をラップして、正しい丸めを行う各種操作を提供するクラスです。コンストラクタに値を渡すか、ユーザー定義リテラルを使用して生成し、各種演算の際に非型テンプレートパラメータとしてfloat_round_styleの値をしていすることで丸めモードをコンパイル時に指定します。
std::fesetround()- cpprefjp<cfenv>- cpprefjp- FENV_ACCESS | Programming Place Plus C言語編 標準ライブラリのリファレンス
- P2746 進行状況
P2747R0 Limited support for constexpr void*
定数式において、void*からポインタ型への変換を許可する提案。
現在、定数式においてはvoid*型のポインタを任意のT*にキャストすることは明示的に禁止されており、仮にそのポインタが正しくTのオブジェクトを指している場合でも許可されません。
このルールは定数式において不正なポインタの読み替え(type punning)が起こらないようにするためであり、constexprをC++の安全なサブセットとする方針に基づいたものです。ただし、void*からの変換がいつも危険というわけではなく、中には安全と分かっているものもあり、一律に禁止されていることによっていくつかの便利なツールをコンパイル時に使用できなく居しています。
- 型消去ユーティリティ
- 例えば、
function_refは型消去して保持している呼び出し可能なものへのポインタを復帰するためにvoid*からの変換が必要
- 例えば、
- 配置
new- 配置
newはオブジェクトを構築する領域ポインタをvoid*で受ける std::construct_at()ではnew式で可能な全ての初期化をカバーできておらず(デフォルト初期化できないなど)、コピー省略を妨げる
- 配置
- オブジェクトの遅延初期化(未初期化配列など)
- 配置
newが必要となる - 配置
new回避のためには未初期化オブジェクトが問題となる - 現在、
static_vectorのconstexpr対応で問題となっている
- 配置
これらのユースケースのサポートのために、この提案では現在定数式でvoid*からT*へのキャストを禁止している一文を削除することで、void*からのポインタの復帰を定数式でも可能とすることを提案しています。
ただし、void* -> T*への変換を行うポインタは予めT*からstatic_cast<void*>で得られたものである必要があり、他の場合は許可されません。すなわち、ポインタが実際に指すオブジェクトの型に応じたポインタ型への変換のみを許可し、type punningのようなことを可能にするわけではありません。
また、未初期化配列(遅延初期化可能なTの配列)サポートのために、unionのメンバとなっている配列に対する配置newが暗黙的に配列全体の生存期間を開始することも提案しています。
この提案の想定される実装上の懸念は、そのようなポインタ変換を検証するコストです。定数式におけるポインタの追跡コストが高くつくようになってしまうと、コンパイル時間の増大を招きます。しかし、void* -> T*への変換が禁止されていることによって型消去ユーティリティや配置newなどを直接的に利用できないために、それが必要となった時に個別にstd::construct_atのようなものを導入する必要があります。このコスト(規格化やコンパイラ実装の手間)に比べれば、この提案を実装するコストは低いと筆者の方は主張しています。
P2748R0 Disallow Binding a Returned glvalue to a Temporary
glvalueが暗黙変換によって一時オブジェクトとして参照に束縛される場合をコンパイルエラーとする提案。
次のコードには一箇所バグがあります。
struct X { const std::map<std::string, int> d_map; const std::pair<std::string, int>& d_first; X(const std::map<std::string, int>& map) : d_map(map) , d_first(*d_map.begin()) {} };
コンストラクタのmapは常に1要素以上あるとして、問題があるのは先頭要素の参照をd_firstに取っているところです。
std::map<K, V>の要素型はstd::pair<const K, V>なのでd_firstの型std::pair<std::string, int>は間違っています。ところがこのこと自体はコンパイルエラーにならず、暗黙変換によってstd::pair<std::string, int>の一時オブジェクトが生成され、その一時オブジェクトがd_firstに束縛されます。そして、その一時オブジェクトの寿命はコンストラクタ呼び出しと共に終了し、d_firstはダングリング参照となります。
とはいえこの例は、コンストラクタ初期化子リスト内で一時オブジェクトの参照への束縛が起こった場合はill-formed、というルールによってコンパイルエラーとなります。
ただし、コンストラクタの外で同じことが起こるとコンパイルエラーにはなりません。
struct Y { std::map<std::string, int> d_map; const std::pair<std::string, int>& first() const { return *d_map.begin(); // 一時オブジェクトが生成される } };
このfirst()は常にダングリング参照を返します。先程と同様の理由によりstd::map<std::string, int>の先頭要素はstd::pair<std::string, int>に暗黙変換され、return文ではその一時オブジェクトが参照に束縛され、その参照がreturnされます。ところが、return文で生成された一時オブジェクトの寿命はそのreturn文の終了までと規定されているため、この場合に一時オブジェクトの寿命は延長されず、この関数は常にダングリング参照を返します。
このようなコードは必ずしもC++初学者だけが書くコードではなく、経験豊富なC++プログラマでも書いてしまう恐れがあります。そのため、コンストラクタの初期化子リスト(及びデフォルトメンバ初期化子)と同様に、このような変換による一時オブジェクトの参照への束縛が起こる場合をコンパイルエラーにしようとする提案です。
この提案では、参照を返す関数のreturn文で一時オブジェクトが参照に束縛される場合をill-formedとすることを提案しています。現在存在しているこのような関数は常にダングリング参照を生成しており、未定義動作に陥っています。従って、この提案による影響はUBをコンパイルエラーとするだけです。
コンストラクタ初期化子とデフォルトメンバ初期化子で同じことが起こる場合をill-formedにしたCWG 1696の議論では、同じ理由により論争が起こることなく採択されており、この提案の根拠はその時と同等以上に強いものであると思われます。
提案より、サンプルコード
auto&& f1() { return 42; // コンパイルエラー } const double& f2() { static int x = 42; return x; // コンパイルエラー } auto&& id(auto&& r) { return static_cast<decltype(r)&&>(r); } auto&& f3() { return id(42); // OK, ただしバグと思われる }
P2750R0 C Dangling Reduction
Cの言語機能の範囲で発生するダングリングポインタを抑制する提案。
これは、上の方で出ていたP2724R0やP2730R0、P2740R0、P2742R0の内容を参照ではなくポインタに対して適用するものです。そちらの提案でも同様のソリューションはポインタに対しても提案しているので内容はほぼ同一です。この提案はそれらの提案からCのポインタ向けの部分をまとめたもののようです。
この提案で提案されている事をまとめると次のようなものです
- ポインタの寿命が尽きる前にその参照するオブジェクトの寿命が尽きる場合、オブジェクトのアドレスをポインタに代入できない
- ポインタを返す関数から、ローカル変数のポインタを直接
returnする場合をコンパイルエラーにする - 同様のことが関数内のローカルスコープで起こる場合をエラーにする
- ポインタを返す関数から、ローカル変数のポインタを直接
- 1段階の間接化を処理
- ポインタを返す関数から、ローカル変数の構造体メンバのポインタを直接
returnする場合をエラーにする - ポインタを返す関数から、ローカル変数へのポインタが代入されたポインタ変数を
returnする場合をエラーにする
- ポインタを返す関数から、ローカル変数の構造体メンバのポインタを直接
parameter_dependency属性の導入- 一時オブジェクトの寿命を複合リテラルの寿命(variable scope)と同じにする
- ローカル定数一時オブジェクトが必ず定数化されるようにする
constな一時オブジェクトがコンパイラによって定数化されるかもしれない、となっているところを定数化される、と変更する
1の例
int* f() { return & 1; // エラー } int* g() { int local = 1; return &local; // エラー } struct Point { int x; int y; }; Point* h() { Point local = {1, 3}; return &local; // エラー } void i(bool b, int i) { int* p = nullptr; if (b) { static int s = 0; p = &s; // OK } else { int i = 0; p = &i; // エラー } ... }
2の例
struct Point { int x; int y; }; int* f() { Point local = {1, 3}; return &local.y; // エラー } Point* f() { Point local = {1, 3}; Point* p = &local; return p; // エラー }
3の例
struct Point { int x; int y; }; [[parameter_dependency(dependent{"return"}, providers{"point"})]] Point* obfuscating_f(Point* point) { return point; } Point* f() { Point local = {1, 3}; return obfuscating_f(&local); // エラー }
4の例
void f() { int* i = &5; // or uninitialized if (whatever) { i = &7; } else { i = &9; } // iを安全に使用できる(間接参照も含めて) }
5の例
const int* f() { return & 1; // ダングリングではない、グローバル変数と同等 } const int* f() { const int local = 1; return &local; // ダングリングではない、グローバル変数と同等 } struct Point { int x; int y; }; const Point* f() { const Point local = {1, 3}; return &local; // ダングリングではない、グローバル変数と同等 } struct Point { int x; int y; }; const int* f() { const Point local = {1, 3}; return &local.y; // ダングリングではない、グローバル変数と同等 }
P2751R0 Evaluation of Checked Contracts
契約条件のチェックに関する細かいルールの提案。
C++26に向けて契約機能を固めていくにあたって、契約条件の各式がどのように評価されるのかについての詳細は重要な事項であり、現在の議論の中心でもあります。この提案は、契約条件の評価をしっかりと規定し、契約違反がいつ発生したかを判断するためのルールを提案するものです。
この提案の概要は次のようなものです
- 契約条件は文脈的に
bool変換可能な式であり、評価する際は式の評価に関するC++の通常のルールに従う - 契約条件の評価が完了し、その結果が
trueでは無い時、契約違反が発生している- 契約条件式の評価結果が
trueとなる場合は契約違反を意味せず、それ以上のアクションは発生しない - 契約条件式の評価結果が
falseとなる場合は契約違反が発生している - 契約条件式の評価時に例外が投げられる場合は契約違反が発生している
- 契約条件式がUBを含む場合、欠陥が発生する
- 実装は、欠陥(UB)を契約違反として扱うことを推奨する
- 正常に評価されないその他の契約条件は正常に動作する
bool変換に失敗した場合など、式の評価に関するC++の通常のルールに従う
- 契約条件式の評価結果が
- 契約条件が評価される回数は未規定。違反の検出のために0回以上、違反の処理のために1回以上評価されうる
- 契約条件を1回だけ評価することは許可される
- 契約条件を0回だけ評価することは許可される
- 条件式に副作用がない場合、その評価をスキップすることが許可されている
- コンパイラが同じ違反を検出する同等の式を識別できる場合、その代替式の評価で条件式を置き換えることができる(as-ifルールに基づく)
- 契約条件を複数回評価することは許可される
- 複数の契約条件が連続して評価される場合、それらは相互に並べ替えて評価される可能性がある
特に3つ目の規則は、副作用を実質的に禁止しつつ、契約条件の他の利用法などまだ議論の最中にあるユースケースを許容することを意図しています。
P2752R0 Static storage for braced initializers
std::initializer_listの暗黙の配列がスタックではなく静的ストレージに配置されるようにする提案。
std::initializer_list<E>のオブジェクトは、実装によって生成された要素数Nのconst Eの配列オブジェクトを参照するようなオブジェクトで、その暗黙の配列の各要素は初期化子の対応する要素からコピーされて初期化されます。std::initializer_listを初期化子に使用する場合、そのような暗黙配列の各要素からさらにコピーされて初期化されます。
struct X { X(std::initializer_list<double> v); }; void f() { // このコードは X x{ 1,2,3 }; // こう書いたかのように初期化される const double __a[3] = {double{1}, double{2}, double{3}}; X x(std::initializer_list<double>(__a, __a+3)); }
標準では、実装はこの暗黙配列をリードオンリーメモリー(すなわち静的ストレージ)に配置して使い回すことができることを示唆しています。しかし、それは実質的に不可能となっているようです。
void f(std::initializer_list<int> il); void g() { // この{1, 2, 3}の配列は静的ストレージに配置できるか? f({1,2,3}); } int main() { g(); } /// どこか別の翻訳単位で定義されているとする void g(); void f(std::initializer_list<int> il) { static const int *ptr = nullptr; if (ptr == nullptr) { ptr = il.begin(); g(); } else { // C++準拠実装はこのアサートを常にパスする assert(ptr != il.begin()); } }
C++23に準拠した実装はこのコードで生成される2つの暗黙配列(1つはmain()のg()呼び出しで生成されるもの、もう一つはネストしたf()の中でのg()呼び出しで生成されるもの)がそれぞれ異なるアドレスを持つようにコンパイルしなければなりません(実際、clang/GCC/MSVCはそのようにコンパイルします)。
これによって、std::initializer_listの暗黙の配列を静的ストレージに配置する最適化は実質的に不可能になっています。
std::initializer_listの暗黙の配列が静的ストレージに配置されることがないということは、std::initializer_listを初期化に使う場合には目には見えない2回のコピーが常に行われていることになります。
#include <vector> int main() { // vectorのこのような初期化において、各要素は2回のコピーを伴う std::vector vec = {1, 2, 3, 4, ...}; }
1回目のコピーは定数({1, 2, 3, 4})からstd::initializer_listの暗黙の配列へのコピーで、この定数は即値であるか静的ストレージに配置されたものです。2回目のコピーは、std::initializer_listの暗黙の配列からstd::vectorの各要素へのコピーです。
#include <vector> int main() { // このコードは次のようなコードと等しい std::vector vec = {1, 2, 3, 4, ...}; // 1. 静的ストレージ(定数)から暗黙配列へのコピー const int __a[] = {int{1}, int{2}, int{3}, int{4}, ...}; // 2. 暗黙配列からvectorのストレージへのコピー std::vector<int> vec(__a.begin(), __a.end()); }
このようなコピーは無駄でありできれば削減したいものですが、一方でリスト初期化を行う際はその要素数はそれほど大きくない場合が多く、実際にはそこまで気にしなくても良いかもしれません。
ところが、C++26では#embedによってこの問題は一層深刻になります
void f() { std::vector<char> v = { #embed "2mb-image.png" }; }
ファイル2mb-image.pngが2MBのサイズのファイルだとすると、このコードはまず2MBの暗黙配列を作成します。それによって関数のスタックが2MB消費されることになります。スタックオーバーフローを起こさなくても、2MB×2回のコピーは十分なオーバーヘッドとして観測されるでしょう。しかも、この問題はコード上から隠されており、std::initializer_listの振る舞いをよく知らないと気づくことが困難です。
この提案は、この問題の解決のために、std::initializer_listが導入する暗黙の配列を静的ストレージに配置する実装を明示的に許可するように標準の規定を調整するものです。
void f(std::initializer_list<double> il); void g(float x) { f({1, x, 3}); } void h() { f({1, 2, 3}); } // これらの初期化は、おおよそ次のようなコードと等価になる void g(float x) { const double __a[3] = {double{1}, double{x}, double{3}}; // スタックに配置 f(std::initializer_list<double>(__a, __a+3)); } void h() { static constexpr double __b[3] = {double{1}, double{2}, double{3}}; // 静的ストレージに配置 f(std::initializer_list<double>(__b, __b+3)); }
スタックではなく静的ストレージに配置されるようになることでスタックの消費を回避することができ、定数->スタックへの1回目のコピーを消し去ることができます。
ただし、この提案ではこのような実装を強制するのではなく、あくまでこうする(h()の例のように実装する)ことを許可するに留めています。
この提案の方向性は、初期化子リスト({...})のセマンティクスを文字列リテラルと一致させることにあり、現在文字列リテラルで許可されている最適化を(コンパイラが実装可能であれば)初期化子リストでも許可しようとするものでもあります。
std::initializer_list<int> i1 = { #embed "very-large-file.png" // OK }; void f2(std::initializer_list<int> ia, std::initializer_list<int> ib) { PERMIT(ia.begin() == ib.begin()); // 静的ストレージに配置した同じは配列の使い回しを許可する } int main() { f2({1,2,3}, {1,2,3}); }
const char *p1 = "hello world"; const char *p2 = "world"; PERMIT(p2 == p1 + 6); // 現在許可されている振る舞い std::initializer_list<int> i1 = {1,2,3,4,5}; std::initializer_list<int> i2 = {2,3,4}; PERMIT(i1.begin() == i2.begin() + 1); // この提案によって許可される振る舞い
P2756R0 Proposal of Simple Contract Side Effect Semantics
契約条件式に含まれる副作用の扱いについて、C++の他の場所と同じ扱いにする提案。
この提案は、P2521R0にあるMVP仕様をベースとして、現在議論の中心にある契約条件式に含まれる副作用の取り扱いについて他のC++の式と差別化しないことを提案するもので、「副作用の禁止」や「2回以上呼ばれる可能性を規定する(ことによる副作用への依存の禁止)」を提案しないものです。
この提案では
- 契約条件式はあらゆる種類の副作用を持ちうる
- 副作用について、不適格・未定義動作・実装定義の動作、などとしない
- 他のC++の式の標準的な動作と同じ動作をする
- 契約の2つの実行モードは、コンパイル前に実装定義の方法によって決定される
この提案の下でも、as-ifルールに従って実装は観測可能な振る舞い(observable behavior)が変化しない限り契約条件式の実行を並べ替えたり省略したりすることは許可されます。この提案の意図は、そういったところも含めて、契約条件式を特別扱いしないことにあります。
int x = 0; void f() PRE(++x) // 事前条件指定とする { ... } int main() { f(); return x; }
この提案では、このプログラムはill-formedではなく未定義動作も含みません。そして、No_evalモードでは0を返し、Eval_and_abortモードでは1を返します。契約条件を特別扱いする他の提案の場合は、Eval_and_abortモードで0, 1, 2のいずれかを返します(結果が1つに定まることが標準によって保証されない)。
この提案による契約記述時の契約条件式のセマンティクスは、現在のC++における普通の式とほとんど同じ振る舞いをするため単純かつ直観的であり、ユーザーの期待と異なる振る舞いをしないため(他の提案と比べて)使いやすいものになっています。
P2757R0 Type checking format args
std::format()のフォーマット文字列構文について、幅/精度の動的な指定時の型の検証をコンパイル時に行うようにする提案。
std::format()ではフォーマット後文字列の幅の指定と、浮動小数点数フォーマット時の精度(小数点を除いた数値の桁数)を指定することができます。
int main() { // 文字幅の指定 std::cout << std::format("|{:3}|\n", 10); // 精度の指定 double v = 3.141592653589793; std::cout << std::format("{:.5}\n", v); }
出力例
| 10| 3.1416
これはまた、実行時の動的指定を簡単に行うために、追加の引数によって指定することができます。
int main() { // 幅の指定を引数で行う std::cout << std::format("|{:{}}|\n", 10, 4); // 幅4が設定される // 精度の指定を引数で行う double v = 3.141592653589793; std::cout << std::format("{:.{}}\n", v, 3); // 精度3桁が設定される }
出力例
| 10| 3.14
この置換フィールド({})内にネストした置換フィールド内のオプションには使用する引数のインデックス指定のみが有効で、それ以外のオプションは構文エラーとなります。また、このネストした置換フィールドには整数値の指定のみが有効です。
フォーマット文字列の妥当性はコンパイル時にチェックされますが、C++23時点においても、このネストした置換フィールドに対する型のチェックをコンパイル時に行うことができません。
std::format("{:>{}}", "hello", "10"); // 実行時エラー
この場合、2つ目の引数"10"が文字列リテラルになっているため(整数型でなければならず)構文エラーとなるはずですが、それはコンパイル時ではなく実行時エラーとして報告されます。
この問題は<format>の元になった{fmt}ライブラリでは既に修正済みで、コンパイル時にエラーを発することができています。この提案は、それをstd::format()に対しても適用するものです。
ユーザー定義型でも組み込み型でも、std::format()に指定された引数に対するフォーマット文字列のパースはstd::formatter<T>::parse()で行われます。フォーマット文字列中の置換フィールドごとに対応する引数を取得して、その型Tによってstd::formatter<T>オブジェクトが作成され、.parse()呼び出されます。.parse()の引数には、フォーマット文字列における現在位置や対応する引数の情報を持ったstd::basic_format_parse_contextのオブジェクトが渡されます。
置換フィールドにネストする置換フィールドの場合、外側の置換フィールドに対するparse()においてネストした置換フィールドを処理する必要がありますが、そこに渡っているstd::basic_format_parse_contextオブジェクトは、引数の実際の値および型情報にアクセスできません。できるのは、対応する引数が存在していることをチェックすることとそのインデックスを取得することくらいです。
これによって、ネストした置換フィールドのパース時には対応する引数に対する型のチェックをコンパイル時に行えなくなっています。
本家{fmt}でもこのあたりの構成はほぼ同じですが、C++20以降の更新によってこの問題に対処しています。そこでは、basic_format_parse_contextにcheck_dynamic_spec()という関数を追加して、そこでこのネストした置換フィールドに対する型チェックを行います。そのために、コンパイル時のformatter::parse()呼び出しでは、basic_format_parse_contextオブジェクトの代わりにbasic_format_parse_contextから派生したcompile_parse_contextというクラスのオブジェクトを生成してそれをparse()に渡します。
parse()は先ほどと同様に対応する置換フィールド内をパースして行きますが、その際にネストした置換フィールドに当たったとき(組み込み型なのでこれは幅/精度の動的指定オプション)、その引数の存在チェックやインデックスチェックと同時に、basic_format_parse_context::check_dynamic_spec()を呼び出します。basic_format_parse_context::check_dynamic_spec()はコンパイル時に呼ばれる場合は自身(*this)がcompile_parse_contextであることを知っているので、*thisをcompile_parse_contextにアップキャストしてからcompile_parse_context::check_dynamic_spec()を呼び出します。
compile_parse_contextはその構築時に全てのフォーマット引数の型情報をインデックス情報と共に受けて保持しているため、compile_parse_context::check_dynamic_spec()にインデックスを渡してやればインデックスに対応した型情報が取得でき、それによって幅/精度の動的指定オプションの置換フィールドに対応する引数が整数型か否かをチェックすることができます。
実装イメージ
// 組み込み型の種類を表す列挙型 enum class type { none_type, // Integer types should go first, int_type, uint_type, long_long_type, ulong_long_type, int128_type, uint128_type, bool_type, char_type, last_integer_type = char_type, // followed by floating-point types. float_type, double_type, long_double_type, last_numeric_type = long_double_type, cstring_type, string_type, pointer_type, custom_type }; // 列挙型typeの値が整数型であるかを判定 constexpr auto is_integral_type(type t) -> bool { return t > type::none_type && t <= type::last_integer_type; } // {fmt}の更新されたbasic_format_parse_context定義 template <typename Char, typename ErrorHandler> class basic_format_parse_context : private ErrorHandler { public: // この2つの関数はC++20と同じ constexpr auto next_arg_id() -> int; constexpr auto check_arg_id(int arg_id) -> void; // 幅/精度の動的指定オプションの型チェックを行う追加された関数 constexpr auto check_dynamic_spec(int arg_id) -> void; }; // コンパイル時のパースコンテキスト型 compile_parse_context定義 // コンパイル時にparse()に渡される前に構築され、basic_format_parse_contextにダウンキャストして渡される template <typename Char, typename ErrorHandler> class compile_parse_context : basic_format_parse_context<Char, ErrorHandler> { // format()に指定された引数の型情報配列 std::span<type const> types_; public: constexpr auto arg_type(int id) const -> type { return types_[id]; } // check_dynamic_spec()のコンパイル時用実装 constexpr auto check_dynamic_spec(int arg_id) -> void { if (arg_id < types_.size() and not is_integral_type(types_[arg_id])) { // エラー報告 this->on_error("width/precision is not an integer"); } } }; // parse()内からはこちらのcheck_dynamic_spec()が呼び出される template <typename Char, typename ErrorHandler> constexpr auto basic_format_parse_context<Char, ErrorHandler>::check_dynamic_spec(int arg_id) -> void { if consteval { // コンパイル時に呼ばれた場合は自身がcompile_parse_contextオブジェクトであることを知っているため、安全なキャスト using compile_context = compile_parse_context<Char, ErrorHandler>; static_cast<compile_context*>(this)->check_dynamic_spec(arg_id); // compile_parse_contextの実装を呼び出す } }
このようなcheck_dynamic_spec()のアプローチは整数型のみを考慮していますが、組み込み型のフォーマット指定においては十分です。この提案では一歩進んで、ユーザー定義型でネストした置換フィールドを扱う際に整数型以外の型を使用した場合でもコンパイル時に検証可能にしようとしています。
そのためにこの提案では、check_dynamic_spec()を関数テンプレートにして要求する型をテンプレートパラメータに指定しつつ、ネストした置換フィールドに対応する引数のインデックスを渡すことで、そのインデックスの引数の型をチェックします。
こうすることで、型を表す列挙型を標準に追加し公開することを避け、期待する型を直接指定するという使いやすいインターフェースになります。ただし、代償としてこの関数テンプレートを呼び出すにはtemplateキーワードが必要になります。
// ユーザー定義特殊化とする template<typename T, typename charT> struct formatter<T, char> { auto parse(auto& ctx) { // Tに対するparse()実装 ... // check_dynamic_spec()の呼び出し ctx.template check_dynamic_spec<char>(id); } };
変更例
namespace std { template<class charT> class basic_format_parse_context { ... public: // このコンストラクタは削除() constexpr explicit basic_format_parse_context(basic_string_view<charT> fmt, size_t num_args = 0) noexcept; // 追加する型チェック関数 // id番目の引数(フォーマット対象引数)に期待する型をTsに指定する template<class... Ts> constexpr void check_dynamic_spec(size_t id); // ↑を呼び出すユーティリティ関数 constexpr void check_dynamic_spec_integral(size_t id); constexpr void check_dynamic_spec_arithmetic(size_t id); constexpr void check_dynamic_spec_string(size_t id); }; }
P2758R0 Emitting messages at compile time
コンパイル時に任意の診断メッセージを出力できるようにする提案。
現在のC++にはコンパイル時に診断メッセージを出力できる使いやすい方法がありません。例えばstatic_assertでは、そのメッセージをエラーに合わせてカスタマイズすることができません。
template <typename T> void foo(T t) { static_assert(sizeof(T) == 8, "All types must have size 8"); // ... } int main() { foo('c'); // error }
このような場合にアサーションに関する情報(Tは何か、sizeof(T)はいくつか)を文字列リテラルに含めることはできません。幸い、コンパイラは長いエラーメッセージの中にそれらの情報を出力してくれる場合が多いですが、Tがメタ関数によって変換されている場合などには出力されなくなることもあります。
一般的に、コード中のアサーションにおいてはそのコードを書いているプログラマの方がそのアサーションのメッセージについて何が有用な情報なのかを知っているはずで、その方法さえあればコンパイラが頑張らなくてもより良い診断メッセージを出力することができるはずです。しかし、現在はstatic_assertの2つ目の引数は文字列リテラル限定であり、定数式で生成された任意の文字列を使用できません。
他のところでは、std::formatのコンパイル時フォーマット文字列チェック時の診断メッセージがあります。
auto f() -> std::string { return std::format("{} {:d}", 5, "not a number"); }
例えばこの例では、:dがconst char*のためのフォーマット指定子ではないためコンパイルエラーとなります。しかし、コンパイラのエラーメッセージは多くの場合何が原因でエラーが起きたのかを報告できません。
このエラー報告メカニズムはstatic_assertを使用しているわけではなく、consteval関数実行中に定数式で実行不可能なものが現れるとコンパイルエラーとなることを利用したもので、throw式の実行か未定義関数の呼び出しによってコンパイルエラーを発生させています。それは本来の用法ではないため、フォーマット文字列のパース中にコンパイルエラーを発生させることはできても、的確な診断メッセージを出力することはできません。
この場合のエラーメッセージが、例えば次のようなものになっていたとしたら、この原因を特定するのはかなり簡単になります
format("{} {:d}", int, const char*)
^ ^
'd' is an invalid type specifier for arguments of type 'const char*'
このメッセージは完璧ではないにしても、今日の診断メッセージよりははるかに優れています。
この提案は、次のように今日のコンパイル時診断メッセージ出力の現状改善を図るものです。
static_assertを拡張して、第二引数に文字列リテラルだけでなく文字列範囲を受け取れるようにする- 新しいコンパイル時診断APIの追加(コンパイル時出力を行う)
std::constexpr_print_str(msg)std::constexpr_print_str(msg, len)
- 新しいコンパイル時エラートリガーAPIの追加(コンパイルエラー発生と診断メッセージ出力を行う)
std::constexpr_error_str(msg)std::constexpr_error_str(msg, len)
std::format()のconstexpr対応を追求すると、上記APIを拡張できる
static_assertの引数は、static_assert(cond, string-literal, expression-list...)のようにする(つまり、std::formatを埋め込む)事も可能ですが、この提案では単にstatic_assert(cond, string-range)のようにすることを提案しています。前者の形式だと、static_assert(cond, "T{} must be a valid expression.")のように3番目以降の引数無しで呼ばれた場合に曖昧になる為で、この場合に文字列リテラルをフォーマット文字列として扱わないようにするとその一貫性が失われます(このアプローチは以前のRustのpanic!()マクロで採用されていたようですが、2021年に見直されたようです)。
また、前者の形式を取るとライブラリ機能であるstd::format()を言語機能であるstatic_assertに実質的に埋め込んでしまう事になり、言語機能が複雑なライブラリ機能に依存することになったり、将来の拡張を妨げたりとあまり良いことがありません。
このような理由により後者の形式を採用し、static_assert+std::format()は明示的に書く必要があります。
static_assert(cond, std::format("The value is {}", 42));
冗長な記述にはなりますが、現在できないコンパイル時診断メッセージの柔軟化を達成できます。
提案されている新しい2種類のAPI(std::constexpr_print_str(), std::constexpr_error_str())はmanifestly constant evaluatedである時のみ効果を持つ、のように指定されます。これは、constexpr処理が投機的に実行される可能性があり、その場合にはメッセージを出力したりエラーを発生したりさせない為の規定です。例えば、constexpr関数の実行中にthrow式に出会った場合、その文脈が必ず定数式で実行されなければならないものでなければ、その処理はそこで中断され実行時まで延期されます。manifestly constant evaluatedとはその様な場合の実行ではないことを指定していて、constexpr処理のコンパイル時実行が確定した場合にのみその効果を発揮することを言っています。
- [C++]
std::formatあるいは{fmt}のコンパイル時フォーマット文字列チェックの魔術 - 地面を見下ろす少年の足蹴にされる私 - [C++] constexpr関数がインスタンス化されるとき - 地面を見下ろす少年の足蹴にされる私
- P2758 進行状況
P2759R0 DG Opinion on Safety for ISO C++
WG21 Direction Group (DG)の安全性についての見解を説明する文書。
プログラミング言語の安全性についての関心の高まりを受けて、C++の将来の方向性として安全性を追求していく事はほぼ固まっていますが、それをどのように進めていくのかについて意見をまとめ、C++標準化委員会の構造やプロセスを定義することを目的として書かれた文書です。
この文書では、それらを構築するにあたっての基本的な考え方を提示しています
- 広く目に付きやすいフレームワークの確立を目指す
- そのフレームワーク内で、安全性に関する変更を議論する
- その変更を適用する場所(言語・ツール等)について合意をする
- 後方互換性の扱いについての方向性に合意する
- 最も重要なものに優先順位をつける
この文書ではまた、そのような仕組みづくりをどのように進めていくのかについて決まっておらず、そのために考慮すべきことや前提知識等を記述し、そのような仕組みづくりのために必要な作業等について説明しています。
安全性とセキュリティに関して2022年末に新設されたSG23を利用していく事になるのかもしれませんが、この文書はさらなる提案を募ってそれらを決めていくいことを求めています。
P2762R0 Sender/Receiver Interface For Networking
現在のNetworking TSにP2300のsender/receieverサポートを入れ込む提案。
Networking TSやP2300については以前の記事を参照
この提案は、Networking TSの現状の問題を解決するために、P2300で提案されているsender/receieverによる非同期フレームワークをNetworking TSに組み込むことで、Networking TSの非同期ネットワーク操作をP2300ベースで構築しようとするものです。
この提案では、Networking TSの同期操作については手を入れず現状の同期/非同期操作のインターフェースを基本として、P2300の非同期フレームワークにアダプトしようとしています。その際に、設計にいくつかの分岐が生じるところがあり、それぞれの選択肢について説明しています。説明のために、一部の選択肢を選択する形で後の機能を解説している部分もありますが、この提案の目的は選択肢を示してNetworking TSとP2300調和のための議論を促すところにあります。
スケジューラの取得方法について
非同期ネットワーク操作においては、非同期性を扱う適切なコンテキスト(実行コンテキスト)に基づいて操作を実行するものが必要です。P2300ではそれはschedulerであり、非同期ネットワークAPIでスケジューラをどのように取得するかについていくつか選択肢があります。
1つ目は、APIをsenderファクトリとして、schedulerを引数としてそこに渡すものです。この方法では、非同期操作を作成する際にそのスケジューラを明示する必要があります。
auto make_accept(auto scheduler, auto& socket) { return async::accept(scheduler, socket); }
ここで、make_accept()はユーザー定義関数(おそらくTCP通信などにおいて待ち受けを行う処理)であり、async::accept()はこの提案による非同期ネットワークAPIの一例です。
この場合の非同期APIは、schedulerと追加引数を受け取ってsenderを返すsenderファクトリとなります。
2つ目は、APIをsenderアダプタとして、スケジューラは上流のsenderから取得するものです。
auto make_accept(auto scheduler, auto& socket) { return schedule(scheduler) | async::accept(socket); }
ここで上流のsenderとはschedule(scheduler)のことですが、make_accept()はユーザー定義関数なのでAPI(async::accept)に|で合成されるsenderはユーザーが用意した任意のものです。schedulerはそれら上位のsenderに指定されたものを取得して使用します。
この場合の非同期APIは、処理に必要な引数を受け取ってその処理を表すsenderを返すsenderアダプタとなります。
3詰めは、APIをsenderファクトリとして、スケジューラは下流のsenderから取得するものです。この方法では、処理グラフの使用側(下流)から使用するスケジューラを与えることができます。
auto make_accept(auto scheduler, auto& socket) { return on(scheduler, async::accept(socket)); }
on()はP2300のCPOの一つで、on(sc, se)のように呼んでsenderであるseの処理をschedulerであるscのコンテキストで実行するsenderを返します。この例ではonによってまずschedulerを与えていますが、それをせずにasync::accept()に|で他の処理をチェーンした後からその呼び出し前にschedulerを与えて、そのコンテキストで実行することもできます。
この場合の非同期APIは、処理に必要な引数を受け取ってその処理を表すsenderを返すsenderファクトリとなります。
2と3の違いは、非同期APIが処理グラフの先頭に来るのか途中に来るのかの考え方の違いであり、それによってグラフの前方と後方のどちらから実行コンテキストであるschedulerを取得するのかが異なっています。
1と2の場合は、非同期APIを用いて非同期ネットワーク操作を構築する際に既に使用するスケジューラを知っている(用意している)必要があります。一方、3の場合はその必要はなく、非同期ネットワーク操作を構築した後で実際にそれを実行する場所で使用するスケジューラを指定することができます。
そのため、この提案では3のアプローチを仮採用し、以降のAPIを説明しています。
エラーハンドリング
Networking TSの非同期APIでは、そのコールバック関数のシグネチャはstd::error_codeを用いる1つだけであり、他の選択肢はありません。P2300による非同期APIでは、エラーや成功といった情報はreceiverを通して3つのチャネルで通知されるため、エラーハンドリングインターフェースに複数の選択肢が生まれます。
1つ目は、set_valueチャネルを使用して他の追加引数と一緒にエラーを通知するものです。これはNetworking TSの非同期APIと近しい使用感になります。
auto sender = async::read(socket, buffer) | then([](error_code const& ec, int n) { ... }); // コルーチンの場合 auto[ec, n] = co_await async::read(socket, buffer);
2つ目は、エラー有無によって異なるset_valueチャネルを使用することで、成功とエラーの経路を分けるものです。コルーチンでのシグネチャは1つに制限されるため、この場合はコルーチンで使用できません。
auto sender = async::read(socket, buffer) | overload( [](int n){ /* success path */ }, [](error_code const& ec){ /* error path */ } );
また、後続の処理はこの2つのパスの分岐に対応して同様にoverload()によって継続する必要がある可能性があります。
3つ目は、前の選択肢におけるエラーチャネルとしてset_valueではなくset_errorを使用するものです。
auto sender = async::read(socket, buffer) | then([](int n) { /* success path */ }) | upon_error([](error_code const& ec) { /* error path */ }); // コルーチンの場合 try { int n = co_await async::read(socket, buffer); // success path } catch (error_code const& ec) { // error path }
コルーチンの場合はエラーチャネルが例外になってしまいますが、成功経路と失敗経路を統合するようなsenderアルゴリズムを使用することで例外を回避することは可能です。
4つ目は、1~3の複合的なもので、エラーの重大度に応じてエラーチャネルを使い分けるものです。これは考えられるだけであまり有効性はないとみなされたのか、サンプルコードは記載されていません。
5つ目は、std::error_codeへの参照を非同期APIに渡して、エラー報告はそこで行うものです。この場合、それが渡されていないときは他の方法をとることができます。
error_code ec; auto sender = async::read(socket, buffer, ec) | then([](int n) { ... }); // コルーチンの場合 int n = co_await async::read(socket, buffer, ec); if (!ec) { /* success path */; } else { /* error path */ }
この場合、Networking TSの同期操作と使用感が近くなります。
メンバ関数と非メンバ関数
Networking TSでは、ある操作についてメンバ関数と非メンバ関数の両方を提供しています。socketというエンティティに対してそのメンバとして各種操作を提供することは他の言語でも一般的なもので、おそらくほかのオプションは存在しません。また、IDEによる入力補完も非メンバ関数よりもメンバ関数の方が効きやすい傾向にあります。
非メンバ関数の操作を提供する場合、それはCPOとして定義されることになるかもしれませんが、CPOはメンバ関数にはなり得ません。また、あるクラスに対してメンバ関数として提供しておくと、時間の経過とともに他の多くの操作や役割がそのクラスに集約されていく可能性があります。非同期ネットワーク操作には潜在的に多くのバリエーション(オプション)があるため、非メンバ関数を用いる方が管理しやすいでしょう。
たとえば、senderを返す操作はasync、コルーチンで使用する場合はcoroのように、使用目的によって適切な名前空間に配置することができるかもしれません。
// senderの場合 auto sender = async::read(socket, buffer) | then([](auto&&...){ /* use result */ }; // コルーチンの場合 auto[ec, n] = co_await coro::read(socket, buffer);
P2300のCPOやsenderアルゴリズムでは、主体となるエンティティが無いためそれらは常に非メンバ関数として定義されます。Networking TSの場合はsocketというエンティティがあるため、そのメンバとして各種操作を定義する方が好まれるかもしれません。また、オプションの全種類を提供する非メンバ関数を提供したときでも、一部のユースケースのためにメンバ関数を提供することを妨げるわけではありません。
I/Oスケジューラのインターフェース
ネットワーク操作(もしくはより一般的なI/O操作)は、特殊なコンテキストでスケジューリングされ、対応するschedulerで実行されることが必要です。ネットワーク操作がスケジューラとやり取りするためのインターフェースにはいくつかのオプションがあります。
- ネットワーク操作とスケジューラは秘密のチャネルを使用する
- もっとも簡単な仕様だが、ネットワーク操作がユーザー定義のスケジューラを使用できない場合があるか、基礎となるスケジューラを抽出する方法についてのプロトコルが必要になる
- 各種I/O操作を何らかの方法で公開/抽象化する
- 仮想関数やCPOなどを使用する
- より汎用的となるが、I/O操作のインターフェースは
senderが使用するものよりも低レベルになり、プラットフォーム固有となる可能性がある - 例えば、非同期
read_some()がio_uring(2)を使用する場合、read_some()はiovecへのポインタ(2つのリングバッファのポインタ)を提供しなければならず、なおかつそのポインタはそのI/O操作が完了バッファから消費されるまで存続する必要がある。これは、read_some()に渡されるバッファとはかなり異なるインターフェースとなる。- 非同期I/Oなので、
read_some()の呼び出しはI/Oの完了を待たずに呼び出し側に戻るため、I/Oの完了までそこで使用するリソースをどこでどうやって保持しておくのかが問題となる
- 非同期I/Oなので、
- スケジューラインターフェースは複数の契約(サポートするI/O操作に対して1つづつ)をモデル化し、ネットワーク操作はI/O操作の状態オブジェクトに埋め込まれるオブジェクトを生成する
- 各I/Oインターフェースは、その状態オブジェクトを必要な形で受け入れ保存する
- P1031のLow level file I/Oライブラリで提案されているものをI/Oスケジューラとする
- Networking TS(Asio)のものを使用するか、それと統合する
io_contextは1の秘密チャネルを使用している様子
タイマークラスか、senderか
Networking TSには、basic_waitable_timerというタイマークラスがあり、基礎となるクロック型や待機方法などのいくつかのタイマープロパティをエンコードしています。Networking TSにおけるこのタイマークラスは、エンティティ(socket等)がキャンセルをトリガーするために使用されます。操作がキャンセル可能であっても、キャンセルは明示的に指定する必要があります。
waitable_timer timer(/* timer settings */); auto sender = wait_for(timer, 5s); // 待機は5秒でキャンセル // コルーチンの場合 co_await wait_for(timer, 5s);
sender/receiverでキャンセルを行う場合は、キャンセルを行えるsenderに接続されたreceiverのstd::stop_tokenの使用によって行います。そのため、タイマークラスは必要なくなります。
タイマーを定義するには、適切なsenderを作成しそれを適切なschedulerでスケジューリングするのが合理的となります。
// 5秒待機するsenderを生成 auto sender = wait_for(5s); // コルーチンの場合 co_await wait_for(5s);
ただし、タイマーのプロパティを指定したい場合などは、それらの調整を1つのオブジェクトにカプセル化して、このオブジェクトを使いまわす方が望ましい場合も考えられます。そのため、両方の選択肢をサポートすることが合理的かもしれません。
高レベルのツール
基本的なネットワーク操作はかなり単純であり、サポートすべき操作の数はそれほど多くはありません。そのため、ネットワーク操作に注力するNetworking TSでは基礎となるI/O操作(例えば、io_uring)が提供する全てのものを提供する必要はありません。むしろ、そのような基礎のI/O操作を超えて、より高いレベルのアルゴリズムを合理的に構成可能とすることに注力すべきです。
例えば、async::read_some()操作は部分的に書き込まれている可能性のあるバッファをうまく読むことができますが、ここから、常に完全なバッファを読むかさもなければ失敗するようなasync::read()操作を構成することができます。
問題は、そのようなアルゴリズムはどれが提案に含まれるべきか、にあるかもしれません。
async::read()やasync_write()は分かりやすい例ですが、async::resolve()のように非自明なアルゴリズムの例があります。そこでは、getaddrinfo(3)が使用されますが、これは同期操作であり、対応する非同期バージョンは提供されていません。非同期フレームワークを名乗る以上は、このような場合でも非同期バージョンを提供しなければならないでしょう。
senderアルゴリズム以外の部分でも、他の興味深いコンポーネントが考えられます
- コルーチン内で使用される非同期ネットワーク操作にスケジューラを注入するコルーチンタスク(
io_task) async_scope(cppcoroのもの)と似た、何らかのI/Oスケジューラに関連する適切なスコープを設定するio_scope- ソケットの全二重操作
- 同時読み書き操作のスケジューリングには、バッファの生成と消費に対応する
senderインターフェースを持つリングバッファのようなものが有用と思われる
- 同時読み書き操作のスケジューリングには、バッファの生成と消費に対応する
キャンセルについての懸念
ネットワーク操作は、操作が開始されてから完了するまでの間は非アクティブになります。そのため、このような操作をキャンセルするためには何らかのキャンセル操作を能動的にトリガーする必要があります。そのため、std::stop_token/std::stop_sourceの提供するようなatomic boolによる単純なテストは一般的にうまく機能しません(スレッドの処理をキャンセルするよりも複雑な処理が必要となりうる)。
そのため、キャンセルにstd::stop_token/std::stop_sourceを使用する(これはほぼ確定事項)場合、キャンセルシグナルを受信するstd::stop_tokenにコールバックを指定して、そこで具体的なキャンセル処理を行う必要があります。stop_tokenがno_stop_tokenでない限り(つまり操作がキャンセルをサポートしない場合以外は)コールバックの登録と解除の両方で何らかの同期を行う必要があり、socketでのデータ処理中にその操作を繰り返すとパフォーマンスが低下する可能性があります。
ここの操作に対してキャンセルを設定するのではなく、socketのようなエンティティの単位でキャンセルをサポートする事もできるかもしれません。その場合は、ライブラリによるある程度のサポートが必要となります。例えば、ある操作をキャンセルするために、その操作をキャンセルする関数を用意するなどです。
その場合でも、パフォーマンス低下を避けるために、stop_tokenによるコールバック登録を禁止する必要があるかもしれません。例えば、when_all()アルゴリズムは、複数のsenderを受けていくつものstop_token(no_stop_tokenではない)を使用するreceiverを使用することになりますが、その場合でも、受信した完了シグナルをすべて通過させつつ、no_stop_tokenを後続senderに公開するsenderアダプタを用意すると便利かもしれません。
システムによっては、一般的なユースケースに対応したキャンセル操作(タイムアウトなど)を備えている場合があります。この場合にそれらを簡単に利用するために、ネットワーク操作に対応するsenderと時間指定からタイムアウトsenderを取得することが合理的かもしれません。タイムアウトsenderは、sender(ネットワーク操作)の完了か指定時間の経過(タイマーのタイムアウト)が起こった時に、もう片方の操作をキャンセルします。
タイムアウトsenderは、利用可能であれば基礎となるシステムのタイムアウト機構を利用して機能を提供し、そうでなければタイマー+when_anyアルゴリズムの合成操作のように振舞い、どれか一つのsenderが完了した場合にstop_tokenによって残りのsenderにキャンセルをかけるような実装になるでしょう。
ただ、このネットワーク操作におけるキャンセル機構の扱いについてはP2300とNetworking TSの両方に経験がなく、実験と設計検討が必要となりそうです。P2300の主張するような、キャンセルを非同期操作にカプセル化する方法は興味深いものではありますが、潜在的なコストとそれを回避する方法が明確にはなっていません。
この提案は、仮の文言を含んでいるものの、その設計は確定したものではなく、さらなる議論によってこれらの選択肢の中から設計を選択していくことを意図しています。
P2763R0 layout_stride static extents default constructor fix
std::layout_strideのデフォルトコンストラクタの生成するレイアウトマッピングを修正する提案。
std::layout_strideはstd::mdspanのレイアウトマッピングをカスタマイズするクラスで、次元毎にstrideを指定したレイアウトを扱う為のものです。このクラスにはデフォルトコンストラクタがありますが、layout_strideの要素数(extents)の指定が完全に静的である場合に無効なマッピングを生成します。
std::layout_stride::mapping<std::extents<int, 4>> map; // map.is_unique() == true; // map(0) == 0; // map(1) == 0; // map(2) == 0; // map(3) == 0;
レイアウトマッピングクラスはポリシークラスであり、その入れ子のmapping<E>クラスによってレイアウトマッピングをカスタムします。テンプレートパラメータEには次元と要素数の情報をもつ型(std::extentsかstd::dextents)を指定し、std::extents<I, N...>(Iは整数型、N...は各次元に対応する要素数)は静的に次元と要素数を指定し、std::dextents<I, N...>は動的な指定も行える(std::dynamic_extentを含むことができる)ものです。
この例の場合のマッピングは1次元4要素の配列を表しており、次元と要素数は完全に静的に指定されていて、layout_stride::mappingをデフォルト構築しているためstrideは指定されていません(layout_strideは、コンストラクタ引数でstrideの情報を渡します)。layout_stride::mappingのデフォルトコンストラクタはdefault実装されており、それによって、layout_stride::mappingの持つstride情報(次元数Dとすると、std::array<std::size_t, D>のような配列)は全て0として初期化されます。
layout_strideによるマッピング(layout_stride::mapping::operator(i...))では、i...の先頭からのインデックスを次元数としてその次元に対応するstride値(コンストラクタで指定されたもの)をかけたもの、を足し上げた値をマッピングしたインデックスとして返します。そのため、layout_stride::mappingをデフォルト構築すると、それによるマッピングはあらゆるインデックスを0に写すものになり、これは明らかに間違ったマッピングになっています。
一方で、他のレイアウトマッピングクラス、std::layout_right(行優先レイアウト、C/C++の通常の多次元配列のレイアウト)、std::layout_left(列優先レイアウト、fortranやmatlabの配列のレイアウト)ではこの問題は起こりません。
std::layout_left::mapping<std::extents<int, 4>> map; // map.is_unique() == true; // map(0) == 0; // map(1) == 1; // map(2) == 2; // map(3) == 3;
この提案は、std::layout_strideのこの挙動を修正しようとするもので、次の2つの方法を提示しています。
- extentsが完全に静的である場合の
std::layout_strideのデフォルトコンストラクタを削除 - extentsが完全に静的である場合の
std::layout_strideのデフォルト構築は、std::layout_rightと同じマッピングを生成する
他のレイアウトマッピングクラスとの一貫性やデフォルト構築をサポートした方が使いやすいと考えられることなどから、この提案では2番目の案を提案しています。また、この提案はC++23の欠陥報告(DR)とすることを推奨しています。
この提案は2023年2月のIssaquah会議でC++23に向けて採択されています(DRとなることは回避されています)。
P2764R0 SG14: Low Latency/Games/Embedded/Finance/Simulation virtual meeting minutes 2023/01/11
2022年11月のKona会議中に行われたSG14のハイブリッドミーティングの議事録。
どんなことを議論したかの概要だけが記されています。
P2765R0 SG19: Machine Learning Virtual Meeting Minutes 2022/12/08-2023/01/12
2022年12月8日から2023年1月12日の間に行われたSG19のミーティングの議事録。
どんなことを議論したかの概要だけが記されています。
P2766R0 SG16: Unicode meeting summaries 2022-10-12 through 2022-12-14
2022年10月12日から2022年12月24日の間に行われたSG16のミーティングの議事録。
NBコメントや提案のレビューや議論において、誰がどんなことを発言したか詳細に記録されています。
P2769R0 get_element customization point object
tuple-likeなオブジェクトから特定のインデックスの要素を抜き出すCPOの提案。
例えば、std::pairを要素とする範囲に対して何かRangeアルゴリズムを適用したいとき、std::pairそのものよりもむしろpairの2つの要素のどちらかに着目する場合が多いでしょう。Rangeアルゴリズムではそのためにプロジェクションが使用でき、入力範囲の要素からその1部を抽出したうえでその結果に対してアルゴリズムを適用することができます。
std::vector<std::pair<int, int>> v{ {3, 1}, {2, 4}, {1, 7} }; std::ranges::sort(v, std::less{}, [](auto& x) { return std::get<0>(x); // キーによってソートする });
std::pairならばプロジェクションのためにメンバ変数ポインタを使用できますが、std::tupleはできないためこのようにラムダ式によって記述しなければならず、少し冗長です。さらには、入力範囲の要素が右辺値の場合などに正しく処理することを意識するとさらに冗長になってしまいます。
// 値カテゴリによらないtuple-likeオブジェクトに対するプロジェクション [](auto&& x) -> auto&& { return std::get<0>(std::forward<decltype(x)>(x)); // key-based sorting }
このような場合のプロジェクションは次のように書けると理想的です
std::ranges::sort(v, std::less{}, std::get<0>);
しかし、std::get<0>だけではまだテンプレートのインスタンス化が完了しないためこれはできません。
他の手段として、views::elementsが思いつくかもしれません。これは、tuple-likeオブジェクトを要素とする入力範囲を、指定インデックスの要素を抽出した範囲に変換するものです。ただ、これはプロジェクションを使用する場合とは異なりtuple-likeオブジェクトからなる範囲の一部の要素だけに着目するものであり、変換後の範囲に対する操作は、元の範囲に対して影響を与えるものではありません。
// views::keys(views::elements<0>)によって、1つ目の要素だけからなる範囲に変換してソート std::ranges::sort(v | std::ranges::views::keys, std::less{}); for (auto& x : v) { auto [key, val] = x; std::cout << "Key = " << key << ", Value = " << val << std::endl; } // 出力例(キーのみがソートされてしまう) // Key = 1, Value = 1 // Key = 2, Value = 4 // Key = 3, Value = 7
views::elements<I>は入力範囲の各要素からstd::get<I>によって要素の参照を抽出して、それを要素とした範囲を生成します。そのため、elements_viewの各要素に対する操作はその要素(元の範囲の各要素の一部)だけにしか影響を及ぼしません。そのため、この例のようにelements_view上でソートしようとすると、元の範囲の要素は動かずキーだけがswapされてしまいます。
このように、現在のところtuple-likeオブジェクトを要素とする範囲に対してRangeアルゴリズムを適用し正しく射影を行うには、ラムダ式による冗長なコードを適切に記述する以外に方法はありません。C++23で追加されたzip_viewではその要素は常にtuple-likeオブジェクトとなるため、この問題はより深刻になる可能性があります。
この提案は、上記のようなtuple-likeオブジェクトの射影を行うstd::ranges::get_element<I>というCPOを追加することで、この問題を解決しようとするものです。
// get_element CPOの宣言例 namespace ranges { inline namespace /* unspecified */ { template <size_t I> inline constexpr /* unspecified */ get_element = /* unspecified */; } inline constexpr auto get_key = get_element<0>; inline constexpr auto get_value = get_element<1>; }
これを使用すると、冒頭のコードは次のように書くことができます
std::vector<std::pair<int, int>> v{ {3, 1}, {2, 4}, {1, 7} }; // pairの1つめのオブジェクトによるソート std::ranges::sort(v, std::less{}, std::ranges::get_element<0>); // あるいは std::ranges::sort(v, std::less{}, std::ranges::get_key);
get_element<I>はelements_viewとは異なりRangeアダプタではなくtuple-likeオブジェクトを引数に取るCPOであり、入力のオブジェクトからget<I>によってI番目の要素を抽出するものです。これはこのようにRangeアルゴリズムのプロジェクションにおいて使用することを意図しています。
std::ranges::getという名前を使用しないのは、std::ranges::subrangeのために提供されているstd::getオーバーロードがすでにその名前を使用しているためで、これを押しのけて導入しようとするとABI破壊を招くことを回避するためです。ただ、可能ならばstd::ranges::getを使用したいため、そのようなABi破壊が受け入れられるかを探ることも提案されています。
この提案に対するSG9のレビューでは、std::ranges::getという名前にするコンセンサスは得られていませんが、ranges名前空間の外に出してstd::get_elementのようにすることにコンセンサスがあるようです。