文書の一覧
採択されたものはありません、全部で30本あります。
- SD-1 2021 PL22.16/WG21 document list
- P0447R12 Introduction of std::colony to the standard library
- P0847R6 Deducing this
- P1121R2 Hazard Pointers: Proposed Interface and Wording for Concurrency TS 2
- P1425R2 Iterators pair constructors for stack and queue
- P1682R2 std::to_underlying
- P1708R3 Simple Statistical Functions
- P1989R1 Range constructor for std::string_view 2: Constrain Harder
- P2036R1 Changing scope for lambda trailing-return-type
- P2072R1 Differentiable programming for C++
- P2093R3 Formatted output
- P2168R1 generator: A Synchronous Coroutine Generator Compatible With Ranges
- P2210R1 Superior String Splitting
- P2216R2 std::format improvements
- P2232R0 Zero-Overhead Deterministic Exceptions: Catching Values
- P2244R0 SG14: Low Latency/Games/Embedded/Finance/Simulation Meeting Minutes
- P2245R0 SG19: Machine Learning Meeting Minutes
- P2246R1 Character encoding of diagnostic text
- P2259R1 Repairing input range adaptors and counted_iterator
- P2266R0 Simpler implicit move
- P2276R0 Fix std::cbegin(), std::ranges::cbegin, and cbegin() for span (fix of wrong fix of lwg3320)
- P2277R0 Packs outside of Templates
- P2278R0 cbegin should always return a constant iterator
- P2279R0 We need a language mechanism for customization points
- P2280R0 Using unknown references in constant expressions
- P2281R0 Clarifying range adaptor objects
- P2283R0 constexpr for specialized memory algorithms
- P2285R0 Are default function arguments in the immediate context?
- P2286R0 Formatting Ranges
- P2287R0 Designated-initializers for base classes
- 次
SD-1 2021 PL22.16/WG21 document list
2016年〜2021年(1月)までの提案文書の一覧。
P0447R12 Introduction of std::colony to the standard library
要素が削除されない限りそのメモリ位置が安定なコンテナであるstd::colonyの提案。
以前の記事を参照
このリビジョンでの変更は、範囲やinitializer_listのinsert()の戻り値型がvoidに変更されたこと、要素を指定した値で初期化しておくタイプのコンストラクタが非explicitに変更されたこと、reserve()の文言など標準のための文言の調整などです。
P0847R6 Deducing this
クラスのメンバ関数の暗黙のthis引数を明示的に書けるようにする提案。
以前の記事を参照
このリビジョンでの変更は、検討した他の構文の記録と、リフレクション・explicit static・virtual・コルーチンの議論を含むセクションを再度追加した事、及び*this引数を明示した関数が非静的メンバ関数になるように規格の文書の文言を調整した事です。
P1121R2 Hazard Pointers: Proposed Interface and Wording for Concurrency TS 2
標準ライブラリにハザードポインタを導入する提案。
ハザードポインタは並行処理におけるデータ共有のための仕組みで、ABA問題を回避するためのdeferred reclamationを実装する方法の一つです。
deferred reclamationに関しては以前の記事を参照。
複数のスレッドによって共有されるデータがあり(ヒープ上にあるとします)、あるスレッドがそれを読み取っており他のスレッドも同様に読み書きができる時、読んでいるスレッドは勝手にデータを変更されたり削除されたりされたくはありません。とはいえ、高コストなロックを使いたくもありません。
そこで、全スレッドが読み取る事の出来るところにポインタを用意しておいて、読み取り中のデータのアドレスをそこに入れておきます。そのポインタに登録されたデータは誰かが見ている途中なので変更しない事、というルールを課します。このポインタのことをハザードポインタと呼びます。
ハザードポインタはある瞬間には最大1つのスレッドによって書き込みが可能とされます。読み取りは全てのスレッドから行えます。
他のスレッドが共有データを変更しようとする時、まずハザードポインタを見に行きます。何も登録されていなければ現在のデータを消すのも書き換えるのも自由です。ハザードポインタに登録がある時(そして変更しようとするデータが登録されている時)、現在のデータを維持したまま新しいデータで置き換えることでデータを更新します。維持されたデータは削除待ちとしてマークして、ハザードポインタからの登録が解除された段階で削除されます。
ハザードポインタのイメージ(P0233R6より)
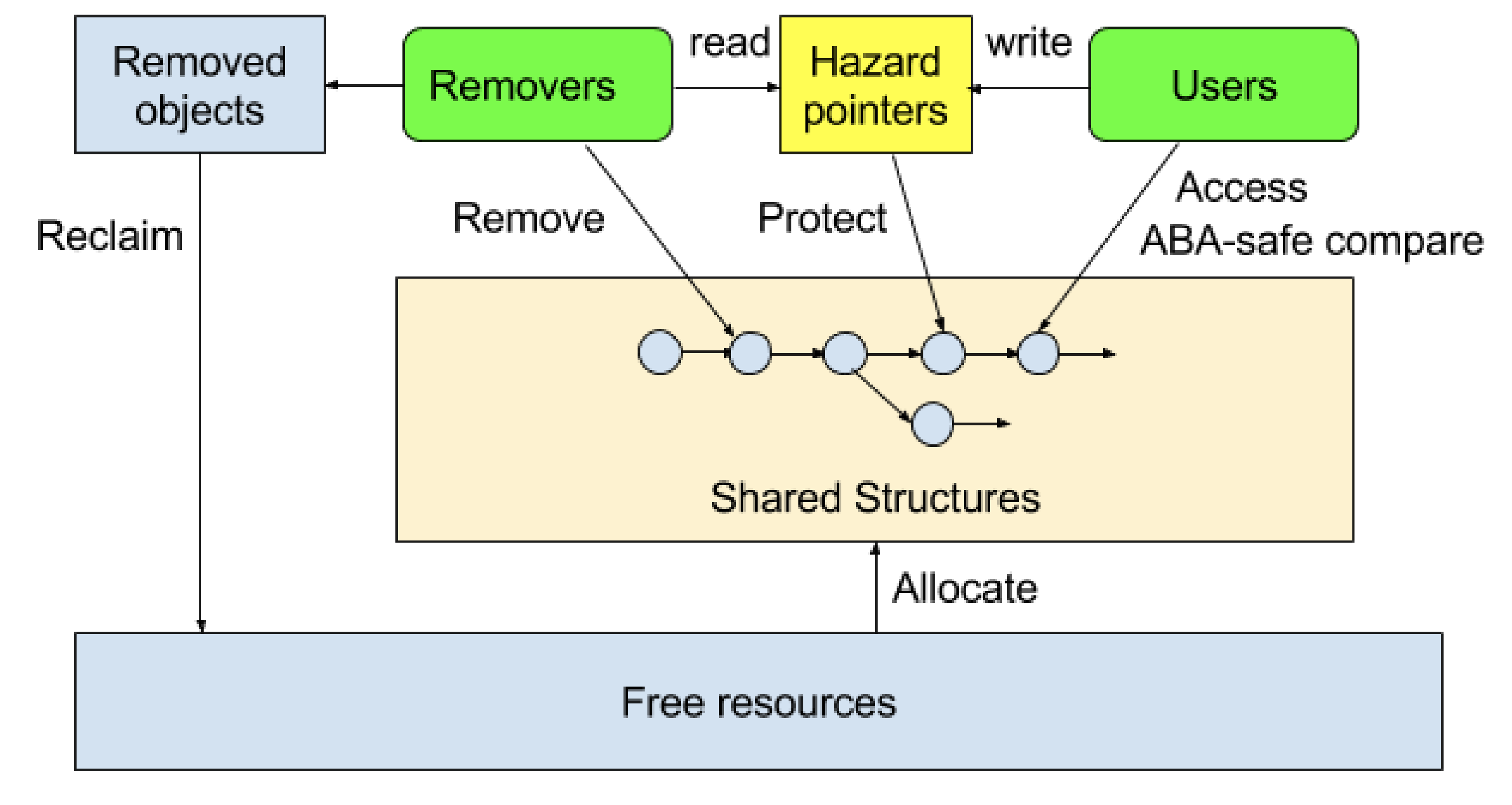
ハザードポインタは単一のものを全スレッドで共有するというよりは、それぞれのスレッドがそれぞれハザードポインタを所有し、変更の際は全てのスレッドのハザードポインタをチェックする、というような実装になるようです。また、ロックフリーデータ構造の実装に使用される場合はハザードポインタは2要素程度のリストになることがあります。
この提案は、ハザードポインタを中心としたこの様な仕組みをサポートし、安全かつ簡単に利用できるようにするためのライブラリを導入しようとするものです。
提案より、サンプルコード。
struct Name : public hazard_pointer_obj_base<Name> { /* details */ }; std::atomic<Name*> name; // 頻繁に複数スレッドから呼ばれる void print_name() { // ハザードポインタを取得する hazard_pointer h = make_hazard_pointer(); // nameをハザードポインタへ登録 Name* ptr = h.protect(name); // 以降、*ptrには安全にアクセスできる(勝手に消えたり変更されたりしない) } // あんまり呼ばれない void update_name(Name* new_name) { // nameを更新する Name* ptr = name.exchange(new_name); // 削除待ち登録、全てのスレッドが必要としなくなった時に削除される ptr->retire(); }
コメントにあるように、ハザードポインタはデータの読み取りに比べてデータの更新が稀である場合に威力を発揮するものです。更新が頻繁に起こるような場合に適した方法ではありません。
この提案はConcurrency TS v2に向けて議論が進んでいます。現在はLWGで議論中なのでそこには入りそうです。標準ライブラリに入るとしてももう少し先になりそうです。
- P0233R6 Hazard Pointers
- Hazard pointer - Wikipedia
- HTMはメモリ管理の為に生まれてきたんだよ! ΩΩ<な、なんだってー - Software Transactional Memo
- P1121 進行状況
P1425R2 Iterators pair constructors for stack and queue
std::stackとstd::queueに、イテレータペアを受け取るコンストラクタを追加する提案。
std::stackとstd::queueはイテレータペアを受け取るコンストラクタがなく他のコンテナとの一貫性を欠いており、それによってranges::toの実装では特別扱いするかサポートしない選択を迫られていました。
この提案はこれらのコンテナアダプタと他のコンテナの間の一貫性を改善し、統一的な扱いができるようにするものです。
#include <array> #include <stack> #include <queue> int main() { std::array<int, 4> arr = {1, 2, 3, 4}; // C++20まで、こう書けばできた std::stack<int> st{{arr.begin(), arr.end()}}; std::queue<int> qu{{arr.begin(), arr.end()}}; // この提案 std::stack<int> st{arr.begin(), arr.end()}; std::queue<int> qu{arr.begin(), arr.end()}; }
この提案はLWGでのレビューをほぼ終えていますが、最近提出されたIssue(LWG 3506)との兼ね合いを調査するためのLEWGでのレビューを待っている状態です。問題がなければC++23に入るものと思われます。
P1682R2 std::to_underlying
列挙型の値からその基底の整数型への変換を行うstd::to_underlyingの提案。
多くのコードベースで、列挙値をその基底型に変換する小さな関数を見ることができます。この様な関数がよく見られる理由は単純で、static_cast<int>のように書くと列挙型から基底型に変換しているという事を見失いやすくなるためです。
この様な関数はEffective Modern C++においてもtoUtype()として紹介されており、2019年6月17日時点で、Githubなどでのto_underlying/to_underlying_type/toUtypeのヒット数は(重複を除いても)1000件を超えているようです。
この関数の使用量の増加はScott Meyersの先見性とアドバイスがあらゆる層のC++プログラマーに受け入れられていることを示しており、この様に頻繁に使用されるユーティリティに標準での名前と意味を与えることには価値があります。
また、列挙値の変換という処理は簡単でありながらも正しく書くことが難しいものでもあります
#include <cstdint> // 基底型を後から変更した(明示的に指定した) enum class ABCD : uint32_t { A = 0x1012, B = 0x405324, C = A & B, D = 0xFFFFFFFF // uint32_t最大値 }; // from before: void do_work(ABCD some_value) { // static_castを使用していることで、コンパイラはこのキャストは意図的なものだと認識 // 警告は発せられない // ABCD::Dが渡ってきた時に間違ったキャストをすることになる internal_untyped_api(static_cast<int>(some_value)); }
do_work(ABCD::D);と呼び出されると間違ったキャストが行われ、internal_untyped_api()には意図しないビットパターン渡されることになります。static_cast<int>はそのキャストを意図的に行っていることを宣言するものでもあるため、コンパイラはエラーも警告も発しません。
do_work()内のキャストは、正しくは次のように書く必要があります。
void do_work(ABCD some_value) { internal_untyped_api(static_cast<std::underlying_type_t<ABCD>>(some_value)); }
しかし、この関数の引数型を整数に変換可能な型に変更してしまった時の事を考えるとまだ問題があります。static_castを適切に修正するかABCDという型を削除しない限りこのコードはコンパイル可能であり続けます。
この提案は、頻繁に使用される列挙値から整数への変換の意図を明確にしその正しい実装を提供するために、std::to_underlying関数を追加しようとする提案です。
先ほどのdo_work()は次のように書き換えられます。
void do_work(ABCD some_value) {
internal_untyped_api(std::to_underlying(some_value));
}
std::to_underlyingの引数の型情報は引数型としてコンパイラから渡され、列挙値以外のものが渡されるとコンパイルエラーとなります。これによって先ほどの問題を解決する事が出来ます。また、static_castではなく関数の戻り値として整数型が得られている事によって、戻り値を別の関数に直接渡す場合などにビット幅や符号のミスマッチを警告として得ることができる場合があります。
この提案はすでにLWGでのレビューを終えており、2月初め頃にある次の全体会議で投票にかけられる予定です。何事もなければそこでC++23入りが決定されます。
P1708R3 Simple Statistical Functions
標準ライブラリにいくつかの統計関数を追加する提案。
提案されている関数は以下のものです。
- 平均(mean)
- 算術平均
- 幾何平均
- 調和平均
- 分位数(quantile)
- 分位数
- 中央値
- 最頻値(mode)
- 歪度(skewness)
- 尖度(kurtosis)
- 分散(variance)
- 標準偏差(standard deviations)
- 重み付きの各種統計量
この提案はBoost Accumulators Libraryを参考にしており、これらの統計処理関数はstd名前空間のグローバル関数としても、Accumulator Objectという複数の統計量の同時計算用クラスとしても提供されます。
基本統計量のサンプル
#include <stats> #include <vector> int main() { std::vector vec = { 2, 3, 5, 7, 7, 11, 13, 17, 19}; // 算術平均 auto mean = std::mean(vec); // 中央値 auto [m1, m2] = std::sorted_median(vec); // 最頻値 std::vector<int> modes{}; std::mode(vec, std::back_inserter(modes)); // 標本分散 auto sample_var = std::var(vec, std::sample_t); // 標本の標準偏差 auto stddev = std::stddev(vec, std::sample_t); }
このように、これらの関数はstd::rangesのアルゴリズム関数と共通したインターフェースを持っており、入力としてrangeオブジェクトを受け取ります。また、射影やExecutionPolicyを取るオーバーロードも用意されています。
Accumulator Objectのサンプル
#include <stats> int main() { std::vector vec = { 2, 3, 5, 7, 7, 11, 13, 17, 19}; std::mean_accum<int> am{}; std::geometric_mean_accum<int> gm{}; std::harmonic_mean_accum<int> hm{}; // シングルパスの操作によって複数の統計量をまとめて計算 accum(vec, am, gm, hm); }
Accumulator Objectはこのように複数の統計量を同時に計算したいときに使用でき、渡された範囲を一回だけ走査します。
P1989R1 Range constructor for std::string_view 2: Constrain Harder
std::string_viewのコンストラクタにrangeオブジェクトから構築するコンストラクタを追加する提案。
この提案の元となった提案(P1391R3)がC++20にて採択されており、std::string_viewはイテレータペアを受け取るrangeコンストラクタを獲得しました。P1391R3ではrangeオブジェクトから構築するコンストラクタも提案されていたのですが、それは見送られこの提案に分離されました。
自作の型からstd::string_viewを構築するには、std::string_viewへの変換演算子を用意することで行われます。そのような型は多くの場合文字列のrangeとしてrangeインターフェースを備えていることが多く、単純にstd::string_viewにrangeコンストラクタを追加してしまうと、一見どちらのコンストラクタが選択されているのか分からなくなります。
struct buffer { buffer() {}; // rangeインターフェース char const* begin() const { return data; } char const* end() const { return data + 42; } // string_viewへの変換演算子 operator basic_string_view<char, s>() const{ return basic_string_view<char, s>(data, data +2); } private: char data[42]; }; std::string_view f(const buffer& buf) { // string_viewにrangeコンストラクタがある時、どっちが使われる?? std::string_view strview{buf}; return strview; }
このように、場合によっては既存のコードの振る舞いを変えてしまうことになります。
この事に対する検討のために、P1391R3からはrangeオブジェクトを取るコンストラクタは分離され、この提案に引き継がれました。
この提案では、rangeオブジェクトを取るコンストラクタを次のように定義する事でこれらの問題を回避しています。
namespace std { template <typename T, typename Traits> concept has_compatible_traits = !requires { typename T::traits_type; } || ranges::same_as<typename T::traits_type, Traits>; template<typename charT, typename traits = std::char_traits<char>> struct basic_string_view { //... template <ranges::contiguous_range R> requires ranges::sized_range<R> && (!std::is_convertible_v<R, const charT*>) && std::is_same_v<std::remove_cvref_t<ranges::range_reference_t<R>>, charT> && has_compatible_traits<R, traits> && (!requires (std::remove_cvref_t<R> & d) { d.operator ::std::basic_string_view<charT, traits>(); }) basic_string_view(R&&); } }
まず、rangeオブジェクトを取るコンストラクタは型remove_cvref_t<R>が自分と同じstd::basic_string_viewへの変換演算子を持っている場合は選択されないようにしています(一番最後のrequires式)。
次に考慮されているのは、型remove_cvref_t<R>がTraits型だけが異なるstd::basic_string_viewへの変換演算子を持っている場合です。その場合今までは(型変換演算子による構築では)コンパイルエラーとなっていました。この提案によるrangeオブジェクトを取るコンストラクタはそのような場合でも、remove_cvref_t<R>が::traits_typeを持っていないなら呼び出されるようになっています。
この提案はP1391R3の議論の過程でこの問題以外の部分のレビューをほぼ終えているため、現在はLWGでの最後のレビューを待っている状態です。
- P1391R3 Range constructor for std::string_view
std::basic_string_view::コンストラクタ - cpprefjp- P1989 進行状況
P2036R1 Changing scope for lambda trailing-return-type
ラムダ式の後置戻り値型指定において、初期化キャプチャした変数を参照できるようにする提案。
現在の仕様の下では、次のコードはコンパイルできません。
auto counter1 = [j=0]() mutable -> decltype(j) { return j++; };
ラムダ本体のjは初期化キャプチャした変数jを参照しますが、後置戻り値型のdecltype(j)にあるjはキャプチャしたものではなく外のスコープの名前を探しに行きます。これは、初期化キャプチャした変数名はラムダ式の本体内部でしか変数名として参照できないためです。
このコードはコンパイルエラーとなるのでまだいいですが、もしjが存在していたらどうなるでしょう・・・
int j = 0; auto counter1 = [j=0.0]() mutable -> decltype(j) { return j++; };
この場合コンパイルは恙なく完了し、このラムダの戻り値型はdoubleではなくintになります。この様な暗黙変換が静かに起こっていると思わぬバグとなる可能性があります。
この問題は初期化キャプチャで最も顕著になりますが、通常のコピーキャプチャでも問題になる可能性があります。
template <typename T> int bar(int&, T&&); // #1 template <typename T> void bar(int const&, T&&); // #2 int i; auto f = [=](auto&& x) -> decltype(bar(i, x)) { return bar(i, x); } f(42); // コンパイルエラー
ラムダの後置戻り値型指定ではiは外で宣言されたint型の変数iを参照し、bar()は#1が選択され戻り値型はintと推論されます。しかし、ラムダ式内部でのiはコピーキャプチャしたconst int型の変数iを参照し、return文のbar()は#2が選択され戻り値型はvoidと推論されます。これは当然コンパイルエラーとなります。
とはいえ、この種の問題は非常に出会いにくいものであり、サンプルコードを思いつくことは出来ても実際に見かけることはなく、筆者の方によるコードベースの調査でも見つけることは出来なかったようです。
ただ、このラムダ式の本体と後置戻り値型における同じ名前の異なる解釈は、ラムダ式の簡易構文の提案(P0573R2)が拒否された理由の一つでした。この様な同じ名前の非常に近しいコンテキストでの異なる解釈はバグであると思われ、C++の将来の進化を妨げていることからこの様なコーナーケースは排除すべき、という提案です。
この事を修正するにしても少し問題があります。
int i; [=]() -> decltype(f(i)) {/* ... */}
この様な場合、iがキャプチャされるかどうかはラムダ式の本体を全て見ないと分かりません。現在は外側の変数iを見に行きますが、先程の問題の解決のためにはキャプチャされているならラムダ内部の変数を見に行く必要があります。
この提案では、この様な場合は常にその名前はキャプチャされた変数であるとして扱って推論を行う事を提案しています。
そして、この変更は初期化キャプチャかコピーキャプチャをしていて、後置戻り値型にキャプチャした変数名を使用している場合に既存のコードを壊す可能性があります。特に、次の様なコードのコンパイル結果が変わります。
auto f(int&) -> int; auto f(int const&) -> double; int i; auto should_capture = [=]() -> decltype(f(i)) { return f(i); }; auto should_not_capture = [=]() -> decltype(f(i)) { return 42; };
現在、この二つのラムダ式の戻り値型はintとなりますが、この提案以降では両方共doubleとなります。
筆者の方の調査でもこの変更で壊れるコードは見つからなかったことから、既存のコードを壊す可能性は極低いものと思われます。EWGにおけるレビューでは、この問題をC++の欠陥として扱うことに合意が取れているようです。
P2072R1 Differentiable programming for C++
C++に微分可能プログラミング(Differentiable Programming)サポートを追加するための検討の文書。
微分可能プログラミングとは、従来の計算に微分可能という性質を加えた形で処理を記述するプログラミングスタイル・言語・DSLを指し、その実態は自動微分であるようです。
微分可能プログラミングは機械学習(ディープラーニング)の分野で興った概念で、ニューラルネットワークの出力部分の処理を微分可能にすることで、ニューラルネットの学習時にその出力処理も含めて学習を行うものです。それによって、ニューラルネットに出力処理を組み込むことが可能になります。例えば、微分可能レンダリングというものがあります。
微分可能プログラミングサポートを追加するというのは、C++で自動微分サポートを追加するという意味なので、その恩恵は機械学習だけではなく数値最適化や物理シミュレーションなど様々な分野に及びます。
この文書はC++に最も適した形での自動微分サポートの議論のために、微分を計算するための方法や自動微分についてを解説し、ライブラリ・言語サポート・将来の言語機能によるサポートなど、自動微分を実装するために可能なアプローチについてを概説したものです。
この文書では、ライブラリサポートよりも言語サポートが望ましく、浮動小数点数型に適用可能でさえあればテンプレートである必要もなく、特に既存のコードに自動微分を適用可能であることが望ましいと述べています。ようするにコードをコンパイルする過程で処理のグラフを解析し、自動でその勾配を算出していくものです。
そのような既存実装の一つであるEnzymeというLLVM IRを解析してリバースモード自動微分を実現するコードトランスパイラによるサンプルです。
// 行列の差の二乗和(自動微分を意識していない普通のコード) __attribute__((noinline)) static double matvec(const MatrixXd* __restrict W, const MatrixXd* __restrict M) { MatrixXd diff = *W-*M; return (diff*diff).sum(); } int main(int argc, char** argv) { // 行列の初期化 MatrixXd W = Eigen::MatrixXd::Constant(IN, OUT, 1.0); MatrixXd M = Eigen::MatrixXd::Constant(IN, OUT, 2.0); MatrixXd Wp = Eigen::MatrixXd::Constant(IN, OUT, 0.0); MatrixXd Mp = Eigen::MatrixXd::Constant(IN, OUT, 0.0); // matvecによる処理の実行と自動微分の計算 // EnzymeがLLVM IRを解析することでこの関数の導関数を求め、計算するコードを出力する __enzyme_autodiff((void*)matvec, &W, &Wp, &M, &Mp); // ... }
このコードは、ClangによってLLVM IRに変換されたあとでEnzymeによって導関数がLLVM IRとして求められ、その結果をClangによって実行ファイルへとコンパイルすることで実行可能なプログラムを得ます。この文書の示すC++自動微分サポートの方向性は、__enzyme_autodiffの部分を言語サポートによって簡易な構文に置き換えつつ、このコンパイル過程を通常のコンパイルで行おうとするものです。
- 『微分可能プログラミング』はどこから来たのか - bonotakeの日記
- 教師あり学習の学習モデルを微分可能プログラミングと純粋関数型言語で記述する - Qita
- CGとAIの架け橋「微分可能レンダラー」のルーツを日本発の論文から探る - AI-SCHOLaR
- 自動微分 - Wikipedia
- Enzyme AD
P2093R3 Formatted output
std::formatによるフォーマットを使用しながら出力できる新I/Oライブラリstd::printの提案。
前回の記事を参照
- P2093R0 Formatted output - [C++]WG21月次提案文書を眺める(2020年6月)
- P2093R1 Formatted output - [C++]WG21月次提案文書を眺める(2020年7月)
- P2093R2 Formatted output - [C++]WG21月次提案文書を眺める(2020年10月)
このリビジョンでの変更は、
std::printという名称が他言語の出力機能との互換性の点で有利であることの説明を追加- P1885を使用してリテラルエンコーディングを取得することで実装を簡素化
- 様々な言語でのユニコード処理の比較結果を追記
- 提案文書の文言と、規格のための文言の調整
などです。
P2168R1 generator: A Synchronous Coroutine Generator Compatible With Ranges
Rangeライブラリと連携可能なT型の要素列を生成するコルーチンジェネレータstd::generator<T>の提案。
前回の記事を参照
このリビジョンでの変更は、
- 各コンパイラでのベンチマーク結果を追加
- 再帰したジェネレータにおける変換の曖昧さの解消のために
elements_of()を追加 - アロケータサポートを追加
- Symmetric transferが様々なアロケータ/値のジェネレータで機能することを追記
- イテレータの
->を削除 - 提案している
std::generatorを新ヘッダ<generator>に配置するように変更 Valueテンプレートパラメータの利点を強調するために例を追加
などです。
P2210R1 Superior String Splitting
現状のviews::splitの非自明で使いにくい部分を再設計する提案。
前回の記事を参照
このリビジョンでの変更は、const-iterationの説明を修正し現在のviews::splitの上により適切なsplitを構成できるようにしたこと、現在のviews::splitの機能を別の意味論に基づく名前で維持するようにしたことです。
この提案では、現在の超汎用splitをstd::ranges::lazy_split_view/std::views::lazy_splitと名前を変更し、新しいより直感的なsplitをstd::ranges::split_view/std::views::splitとすることを提案しています。
P2216R2 std::format improvements
std::formatの機能改善の提案。
以前の記事を参照
- P2216R0 : std::format improvements - [C++]WG21月次提案文書を眺める(2020年9月)
- P2216R1 : std::format improvements - [C++]WG21月次提案文書を眺める(2020年12月)
このリビジョンでの変更は、提案している機能の効果についての調整がメインです。
この提案はLEWGでの投票において 提案する2つの事項(コンパイル時フォーマットチェック、バイナリサイズ削減)についてC++20へのDefact Reportとすることで合意が取れ、C++20への逆適用のためにLWGで先行してレビューされました。そこでもC++20へのDRとすることで合意が取れ、LEWGでのレビューと投票を待ってどうやら2021年の夏ごろにはC++23に採択されそうです。その場合この変更はC++20にさかのぼって適用されます。
P2232R0 Zero-Overhead Deterministic Exceptions: Catching Values
任意の値を投げることのできる静的例外機能の提案。
P0709R4にて議論されているstd::errorによる静的例外では、例外オブジェクトとして特定のものだけをthrowすることができます。しかし、既存の例外を使用するコードにおいては独自の例外型が使用されていることがあり、その場合はstd::errorに移行することはできず、結果としてC++におけるエラーハンドリングの複雑さを増加させることになってしまいます。
この提案はそれを防止するため、値によるキャッチを使用する場合に任意の型の例外オブジェクトを効率的に転送するためのP0709R4とは別のアプローチを提案するものです。
まずこの提案による任意の値のthrowでは、次の2つの仮定を置きます
- 値の
catchのみを使用するcatch(E& e)ではなく、catch(E e)
catch(E e)のセマンティクスを変更する- 動的な型ではなく、静的な型によって例外オブジェクトとマッチさせる
この過程を置くと、例外オブジェクトはtry-catchの範囲内でスタック領域を使用できるようになります。
try { f(); // Throws } catch( E1 e1 ) { // Use e1 } catch( E2 e2 ) { // Use e2 }
今、E1, E2のそれぞれの例外オブジェクトの型とそのサイズは静的に決定できるため、スタック上の領域を予約しておくことができます。すると、キャッチした側ではE1, E2のどちらの値が投げられてきたのかを知る仕組みが必要となります。この判定のために、std::optional<E1>, std::optional<E2>の領域をスタック上に確保しておきます。
次に、f()内のthrow E1{}/throw E2{}がそのスタック領域を使用できるようにする効率的な仕組みが必要となります。これには、スレッドローカルストレージを使用します。
f()を囲うtryブロックでは、f()を呼び出す前にe1, e2用に予約されたsスタック上のstd::optional<E1>, std::optional<E2>の領域を指すようにスレッドローカルストレージにポインタpE1, pE2を初期化します。現在の例外処理の実装もスレッドローカルストレージを使用しているので、それを利用することに問題はありません。
f()が例えばをthrow E1{}したとき、スレッドローカルポインタpE1にアクセスし、次のどちらかを実行します
pE1がnullであれば、catch(E1 e1)ステートメントが現在のコールスタックで使用できないことを意味しており、従来の例外機構による処理に切り替える- それ以外の場合、
pE1の指す領域にE1のオブジェクトを構築する
次に、スタックを最上位の例外スコープ(最も内側にあるtry-catchブロックの位置)まで巻き戻します。この実装はP0709にあるものと同じものが利用でき(詳細は不明・・・)、代替戻り値としては、例外オブジェクトの代わりに失敗か成功かを表す1ビットのフラグを返します。
try-catchブロックに到着する(巻き戻る)と、あらかじめ確保しておいたstd::optional<E1>, std::optional<E2>(スタック上)を調べます。catchブロックの順番にstd::optionalオブジェクトがチェックされ、空でない最初のstd::optionalに対応するcatchブロックが実行されます。ここでの説明の例では、e1 -> e2の順でチェックされ、catch(E1 e1)スコープが選択されます。適切なブロックが見つからなければスタック巻き戻しを続行し、最終的には適切なcatchで捕捉されるか従来の例外機構にスイッチするかのどちらかで完了します。
これによって、スタックの巻き戻しが高速になりcatchが動的型ではなく静的な型でチェックされるようになるため、P0709と比較しても効率がさらに向上しているとのことです。
P2244R0 SG14: Low Latency/Games/Embedded/Finance/Simulation Meeting Minutes
SG14のミーティングの議事録。
SG14はゲームハードや組み込みシステムなどのリソースが制限されている環境や金融やシミュレーションなど低遅延が重視される環境などにおけるC++についてを議論・研究するグループです。
P2245R0 SG19: Machine Learning Meeting Minutes
SG19のミーティングの議事録。
SG19はC++における機械学習サポートについて議論・研究するグループです。
P2246R1 Character encoding of diagnostic text
コンパイル時にメッセージを出力するものについて、ソースコードのエンコーディングが実行時エンコーディング(出力先のエンコーディング)で表現できない場合にどうするかの規定を修正する提案。
以前の記事を参照
このリビジョンでの変更は、提案する文言の調整(shallをshouldへ変更)がメインです。
この提案はSG16で議論されていましたが、この提案の方向性についての合意が取れたたためEWGへ転送されました。
P2259R1 Repairing input range adaptors and counted_iterator
iterator_categoryが取得できないことから一部のrange adoptorのチェーンが機能しない問題と、counted_iteratorの問題を修正する提案。
以前の記事を参照
このリビジョンでの変更は、elements_viewのiterator_categoryを修正しiterator_conceptを定義した事です。そのiterator_conceptは受けているrangeの満たすC++20的性質を、iterator_categoryは受けているイテレータのC++17的性質を受け継いで決定されます。これはこの提案で変更されている他のViewも同様の方向性で調整されています。
この提案はIssue解決のためのものだったこともありLWGで議論されており、LWGでは全会一致でアクセプトされました。次の全体会議で全体投票にかけられ問題が無ければC++23に採択される予定です。
P2266R0 Simpler implicit move
return文における暗黙のムーブを改善する提案。
C++20での欠陥改善(P1825R0)により、関数のreturnにおいては右辺値参照型のローカル変数からでも暗黙的にムーブ(implicitly move)を行うことができるようになります。しかし、この改善されたはずの規格の文書にはまだ欠陥があり、関数が参照を返す場合に暗黙ムーブが行われないようです。
struct Widget { Widget(Widget&&); }; struct RRefTaker { RRefTaker(Widget&&); }; // 次の3つのケースではreturnで暗黙ムーブされる Widget one(Widget w) { return w; // OK、C++11以降 } RRefTaker two(Widget w) { return w; // OK、C++11以降(CWG1579解決後) } RRefTaker three(Widget&& w) { return w; // OK、C++20以降(P0527による) } // 暗黙ムーブされてほしい、されない・・・ Widget&& four(Widget&& w) { return w; // Error! }
この様に関数が右辺値参照を返す場合には暗黙のムーブが行われず、このケース(four())では、関数ローカルの左辺値wを右辺値参照型Widget&&に暗黙変換できずにエラーとなります。
戻り値が参照である場合に、同様の事が起きます。
struct Mutt { operator int*() &&; }; struct Jeff { operator int&() &&; }; // 暗黙ムーブされ、Mutt&&からの暗黙変換によってreturn int* five(Mutt x) { return x; // OK、C++20以降(P0527による) } // 暗黙ムーブされず、int&へ変換できずエラー int& six(Jeff x) { return x; // Error! }
template<class T> T&& seven(T&& x) { return x; } void test_seven(Widget w) { // Widget& seven(Widget&) Widget& r = seven(w); // OK // Widget&& seven(Widget&&) Widget&& rr = seven(std::move(w)); // Error }
関数の戻り値型がオブジェクト型ではないとき、暗黙ムーブが行われない事によってこれらのような問題が起きています。
この提案は、関数から返されるmove-eligibleな式は常にxvalueであると言うように指定する事でこれらの問題の解決を図るものです。
- P1825R0 Merged wording for P0527R1 and P1155R3
- CWG Issue 1579. Return by converting move constructor
- P2266 進行状況
P2276R0 Fix std::cbegin(), std::ranges::cbegin, and cbegin() for span (fix of wrong fix of lwg3320)
メンバ関数cbegin()とフリー関数のstd::cbegin()/std::ranges::cbegin()の不一致を修正し、std::spanのcbegin()サポートを復活させる提案。
std::cbegin()/std::ranges::cbegin()はともに、const引数で受け取ったオブジェクトに対して使用可能なbegin()を呼び出そうとします。標準のコンテナならばconstオブジェクトに対するbegin()メンバ関数はconst_iteratorを返すため、メンバcbegin()と同様の結果を得ることができます(cend()も同様)。
しかし、これはつまりメンバとしてcbegin()/cend()を用意していてもstd::cbegin()/std::ranges::cbegin()はそれを呼び出さない事になり、クラスによってはstd::cbegin()/std::ranges::cbegin()で期待されるread-onlyなイテレータアクセスを提供しない可能性があります。
C++20当初のstd::spanがまさにその問題に引っかかっておりLWG Issue 3320にて一応解決されました。しかし、この修正はstd::span::cbegin()メンバ関数とstd::cbegin()/std::ranges::cbegin()の戻り値型の不一致の是正に重きを置いていたため、std::spanからcbegin()/cend()メンバ関数を削除する事でその不一致を解消していました。
一方、std::spanのbegin()メンバ関数はconstオブジェクトに対するオーバーロードを提供しておらず、std::cbegin()/std::ranges::cbegin()から呼び出された時でもmutableなイテレータを返してしまいます。結局std::spanはconst_iteratorを提供しないため、std::cbegin()/std::ranges::cbegin()を用いてもread-onlyなイテレータアクセスはできません。
std::vector<int> coll{1, 2, 3, 4, 5}; std::span<int> sp{coll.data(), 3}; for (auto it = std::cbegin(sp); it != std::cend(sp); ++it) { *it = 42; // コンパイルエラーにならない・・・ } for (auto it = std::ranges::cbegin(sp); it != std::ranges::cend(sp); ++it) { *it = 42; // コンパイルエラーにならない・・・ } for (auto it = sp.cbegin(); // コンパイルエラー! it != sp.cend(); ++it) { // ... }
この提案では、次の2つの変更によってこの問題の解決を図ります。
std::cbegin()/std::ranges::cbegin()は引数に対してそのメンバ関数の.cbegin()が呼び出し可能ならばそれを使用する- その上で、
std::spanにメンバ関数cbegin()/cend()を追加し、const_iteratorサポートを復活させる
1つ目の変更はcend()/crbegin()/crend()に対しても同様の変更を提案しています。
P2277R0 Packs outside of Templates
パラメータパックをテンプレートではないところでも使えるようにする提案について、実装難度がメリットを上回っていないかどうかの検討を促す文書。
現在の進行中の提案のうち、パラメータパックをより活用しようとするものには次の4つがあります。
- P1061R1 Structured Bindings can introduce a Pack
- P1858R2 Generalized pack declaration and usage
- P1240R1 Scalable Reflection in C++
- P2237R0 Metaprogramming
これらの提案では、可変長テンプレートでないところでも、あるいは非テンプレートの文脈でもパラメータパックを活用しようとしています。
template <typename... Ts> struct simple_tuple { // データメンバ宣言時のパック展開(P1858) Ts... elems; }; int g(int); // 非関数テンプレート void f(simple_tuple<int, int> xs) { // 構造化束縛でのパック導入(P1061) auto& [...a] = xs; int sum_squares = (0 + ... + a * a); // パラメータパックでないもののパック展開(P1858) int product = (1 * ... * g(xs.elems)); // テンプレートパラメータのreflection-rangeを構築する(P1240) // これはint型のリフレクション2つを含むvector constexpr auto params = std::meta::parameters_of(reflexpr(decltype(xs))); // reflection-rangeの展開1(P1240) // decltype(ys) is simple_tuple<int, int> simple_tuple<typename(...params)> ys = xs; // reflection-rangeの展開2(P2236) // decltype(zs) is simple_tuple<int, int> simple_tuple<|params|...> zs = xs; }
P1240とP2236の二つのリフレクションベースの提案におけるreflection-rangeの展開は似ていますが、P1240が単なる展開しかできないのに対して、P2236は展開しつつ変換することもできます。例えば、simple_tuple<int&, int&>構成しようとするとそれぞれ次のように書くことができます。
// P1240の方法 constexpr auto refs = params | std::views::transform(std::meta::add_lvalue_reference); simple_tuple<typename(...refs)> ys_ref{a...}; // P2237の方法 simple_tuple<|params|&...> zs_ref{a...};
これらの提案のうち一部のものについては実装の複雑さとコンパイル時間増大の懸念が示されています。
ある名前がパック展開の対象となるか否かは一連の式を最後まで見る必要があります。...は接尾辞であり、しかもパック名の直後だけではなくその後の任意の場所にあらわれる可能性があるためです。ただし、現在のところこのような配慮は可変長テンプレートの中でだけ行えばよく、他のところではこれを考慮する必要はありません。
しかし、これらの提案の機能の一部には可変長テンプレートではない場所でパック展開が発生するものがあります。これがもし導入されると、可変長テンプレートではないC++の全てのところでパック展開が出現する可能性を考慮する事になり、これはコンパイル時間を増大させます。
P1240R1はこのことを考慮して注意深く設計されているようですが、他の提案にはこの問題があります。
この問題への対処には次の3つの方法があります。
- テンプレートの外でのパック展開を許可し、そのために発生するコスト(コンパイル時間増大)を受け入れる
- テンプレート外でのパック展開には、接頭辞によって行う何かを考え出す。パック展開にはその仕様を推奨する。
- 可変長テンプレートの外でのパック展開は許可しない
筆者の方は1を推奨しているようです。
この文書は、EWGがこれらの提案の議論の前に上記選択肢のどれを選択するのか?あるいはテンプレートの外でのパック展開は利点がコストを上回っているのか、なるべく早期にその方向性を決定することを促すものです。
P2278R0 cbegin should always return a constant iterator
std::ranges::cbegin/cendを拡張して、常にconst_iteratorを返すようにする提案。
先程P2276の所でも言っていたように、std::ranges::cbegin/cendはconstオブジェクトに対するstd::ranges::begin/endを呼び出すため、必ずしもconst_iteratorを返しません。
C++11でメンバcbegin/cendと非メンバstd::begin/endが追加され、その後std::cebgin/cendが追加された(LWG Issue 2128)ときは、コンテナオブジェクトcに対するstd::as_const(c).begin()とc.cbegin()の結果が異なるコンテナは(少なくとも標準ライブラリの中には)存在しておらず、CPOの様なものも発明されていなかったので、std::cbegin()が実質的にstd::as_const(c).begin()のように定義されても問題はなく、仕方ない所がありました。
その後もC++17までは何事もありませんでしたが、C++20にてstd::spanが追加されるとstd::cbegin/endの振る舞いが問題になりました。std::spanは別の範囲を参照するものでしかなく、それ自身のconst性と参照先のconst性が同期していません。したがって、std::as_const(c).begin()とc.cbegin()の結果が一致しません。例えば、std::spanでは参照先のconst性を表すのはconst span<T*>ではなくspan<const T*>です。従って、それらのメンバbegin/endのconstオーバーロードでconst_iteratorを返すのはセマンティクスにあっていません。
しかし一方で、std::cbegin/endはspanのメンバbegin/endのconstオーバーロードを呼び出してしまうので、std::cbegin/endを使って取得したイテレータはconst_iteratorではありません。ただし、spanのメンバcbegin/cendはきちんとconst_iteratorを返していたため、非メンバstd::cbegin/endとメンバcbegin/cendの間で結果が異なることになります。最終的に、一貫性のためにspanのメンバcbegin/cendは削除されました(LWG Issue 3320)。
この問題は現在のところstd::spanでしか起きてないようですが、C++20で追加されたRangeライブラリの各種Viewの中にはそもそもconst-iterableではないためにメンバcbeginもメンバbeginのconstオーバーロードも提供していないものがあります。また、これから追加されるであろう他のViewでも同様あるいはspanと同様の問題が発生しうるものがあるようです。
この提案ではこの問題の解決のために、イテレータ/センチネルのペアをラップしてconst_iterator化するmake_const_iteratorようなものを追加し、std::ranges::cbegin/cendでは、それを用いて引数のrangeオブジェクトから得られるイテレータ/センチネルのペアをラップして、std::ranges::cbegin/cendが常にconst_iteratorを返すように変更することを提案しています。また、それを用いてviews::const_rangeアダプタを追加することも提案しています。
ただし、std::cbegin()/cend()は後方互換性維持のために手を付けていません。
P2279R0 We need a language mechanism for customization points
C++に適切なカスタマイゼーションポイントを提供するための言語サポートを追加する検討を促す提案。
現在のC++言語機能の範囲内で利用可能なカスタマイゼーションメカニズムには次のようなものがあります。
- 仮想関数
- クラステンプレートの特殊化
- ADL
- カスタマイゼーションポイントオブジェクト(CPO)
tag_invoke
過去に提案されていたカスタマイゼーションメカニズムには次のようなものがあります。
- カスタマイゼーションポイント関数
- コンセプトマップ
それらにRustのTraitを含めて比較すると、それぞれ次のような特性を持ちます
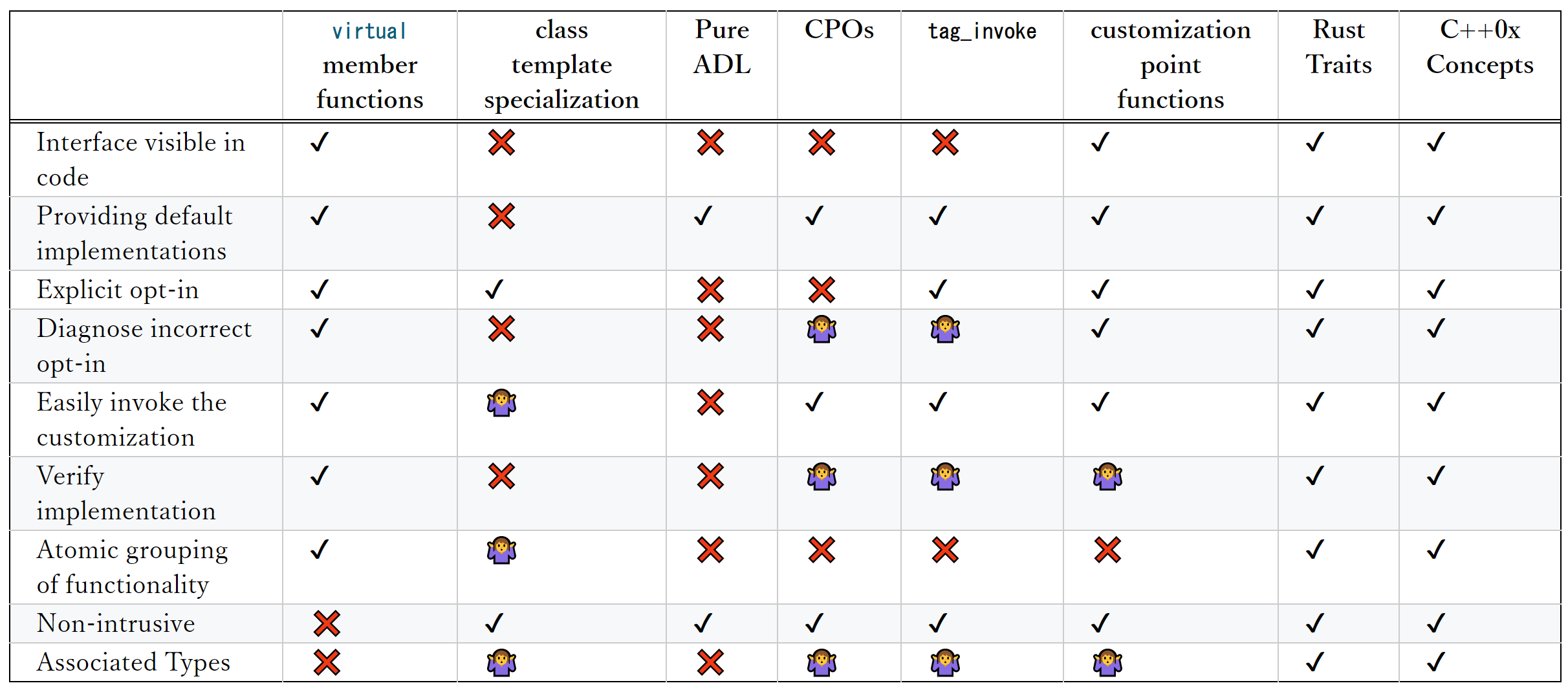
✔️は可能であること、❌は不可能であること、 🤷 は部分的には可能だが完全ではないことをそれぞれ表しています。
各行の意味はそれぞれ
- Interface visible in code
- カスタマイズ可能な(あるいはその必要がある)インターフェース(関数など)がコードで明確に識別できる
- Providing default implementations
- デフォルト実装を提供し、なおかつオーバーライド可能
- Explicit opt-in
- インターフェースを明示的にオプトインできる(インターフェースへのアダプトが明示的)
- Diagnose incorrect opt-in
- インターフェースに意図せずアダプトしない
- Easily invoke the customization
- カスタマイズされたものを簡単に呼び出せる
- デフォルト実装がある場合、必ずカスタマイズされたものを呼び出す
- Verify implementation
- ある型がインターフェースを実装していることを簡単に確認できる(機能がある)
- Atomic grouping of functionality
- インターフェースにアダプトするために必要な最小の機能グループを提示でき、早期にそれを診断できる
- Non-intrusive
- 非侵入的(その型を所有していない人が後からカスタマイズできる)
- Associated Types
そして追加で、Customization Forwardingという要求も検証しています。例えばCPOやtag_invokeなら、それそのものを呼び出し可能オブジェクトとして他の関数などに渡すことができます。一方、コンセプトマップは(Rustのtaritも?)それそのものは呼び出し可能ではありません。
この提案は、理想的にはこれらの要件をすべて満足するようなカスタマイズメカニズムをC++の言語機能としてサポートすることを目指して、その議論の出発点となるべく書かれたものです。
P2280R0 Using unknown references in constant expressions
定数式での参照のコピーを許可する提案。
C++では生配列のサイズを求めるのにstd::sizeを使用できます。が、constexpr関数では不可解なコンパイルエラーに遭遇することがあります。
template <typename T, size_t N> constexpr auto array_size(T (&)[N]) -> size_t { return N; } void check(int const (¶m)[3]) { int local[] = {1, 2, 3}; constexpr auto s0 = array_size(local); // ok constexpr auto s1 = array_size(param); // error }
この提案は、この問題を解決し二つ目の呼び出しが適格となるようにするものです。
これはルールとしては定数式で禁止されている事項に引っかかっているためにコンパイルエラーとなります。
N4861 7.7 Constant expressions [expr.const]/5.12より
- 参照に先行して初期化されていて次のどちらかに該当するものを除いた、変数の参照または参照型データメンバであるid-expression
- 定数式で使用可能である
- その式の評価の中でlifetimeが開始している
[expr.const]/5では定数式で現れてはいけない式が列挙されています。これはそのうちの一つです。
定数式ではあらゆる未定義動作が許可されないため、コンパイラはすべての参照が有効であることを確認する必要があります。先程のarray_sizeが機能するためには配列の参照を定数式で読み取る(コピーする)必要がありますが、関数引数の参照は直接的には有効性が判定できないものであり、上記のルールに抵触するタイプの参照となります。ただ、ここでは単に参照のコピーが必要なだけで参照そのものに関心はないはずです。
この事はポインタを取るように変更する事でより明快になります。
template <typename T, size_t N> constexpr size_t array_size(T (*)[N]) { return N; } void check(int const (*param)[3]) { constexpr auto s2 = array_size(param); // error }
ここでのarray_sizeの呼び出しではparamのコピーが発生しています。定数式中で関数にコピー渡しする場合、コピー元も定数式でなければなりませんが、関数の引数は定数式ではありません(cosntexpr/consteval関数の中であっても)。ローカルの配列(のポインタ)の場合はその参照(ポインタ)が有効であることをコンパイラが認識できるので問題にはなりません。
ただし、この様な問題は参照(ポインタ)でのみ起きます。値を渡す場合、例えばstd::arrayを用いるとコンパイルエラーは起こりません。
void check_arr_val(std::array<int, 3> const param) { std::array<int, 3> local = {1, 2, 3}; constexpr auto s3 = std::size(local); // ok constexpr auto s4 = std::size(param); // ok }
提案では、この様に参照そのものと関係なく動作するケースにおいて、定数式内での参照の読み取り(すなわちそのコピー)を許可しようとするものです。参照そのものに依存するような操作は引き続き禁止されます。
EWGでのレビューでは、この問題をC++23までに解決することとC++11までの欠陥報告とする事に合意が取れており、EWGでの次の投票を受けてCWGに転送される予定です。
P2281R0 Clarifying range adaptor objects
range adaptor objectがその引数を安全に束縛し、自身の値カテゴリに応じて内部状態を適切にコピー/ムーブする事を明確化する提案。
GCCはRangeライブラリの全ての部分を、MSVCは一部を既に実装していますが、そこには次のような相違点があるようです。
template<class F> auto filter(F f) { // GCC : fを参照で保持する // MSVC : fを常にコピーして保持する return std::views::filter(f); } std::vector<int> v = {1, 2, 3, 4}; // 状態を持つCallableオブジェクトを渡す auto f = filter([i = std::vector{4}] (auto x) { return x == i[0]; }); // GCCの場合、fにダングリング参照が含まれている // MSVCは無問題 auto x = v | f;
明らかにMSVCの動作が望ましいのですが、adaptor(args...)の様に呼ばれたときにadaptorがargs...をどのようにキャプチャするのかは規定がありません。また、adaptor(range, args...)とadaptor(args...)(range)が同じ振る舞いをするという要件は、ここでargs...をコピーするという選択を排除している可能性があります。
結果的に現在の記述では、左辺値の範囲に対するパイプラインを再利用しても安全であることを保証していません。つまり、上記におけるxの再利用が安全であるかは未規定に近く、v | fでは(fの状態がなんであれ)fからムーブされることが無いことを示唆しています。
この提案では、range adaptor objectが行う部分適用がstd::bind_frontの行う事と同等であることが明確になるように現在の規格書の記述を変更しています。
それによって、上記のMSVC実装が合法かつ推奨される実装となります。これは、range adaptor objectに渡された引数が参照によって束縛されず常に値によって束縛され、パイプラインに渡す時にはその値カテゴリに応じて束縛されたものを適切にコピー/ムーブする、という事でもあります。
疑似コードで書くと次のようになります。
auto c = /* 任意のrange */; auto f = /* コピーコストが高い関数オブジェクト */; c | transform(f); // fをコピーして結果のviewにムーブする auto t = transform(f); // fをコピーする c | t; // tから再度fをコピーする c | std::move(t); // tからfをムーブする
またこれに伴って、customizetion point object(range adaptor objectはCPOでもある)がコピーやムーブされたときにも同じ引数に対して同じ結果を返すことを保証するように文面を明確化しています。
- LWG Issue 3509. Tim Song. Range adaptor objects are underspecified.
- LWG Issue 3510. Tim Song. Customization point objects should be invocable as non-const too.
std::bind_front- cpprefjp- P2281 進行状況
P2283R0 constexpr for specialized memory algorithms
<memory>にある未初期化領域に対する操作を行う各関数をconstexprにする提案。
未初期化領域に対する操作を行う各関数とは、<memory>にあるstd::uninitilized_~という関数群の事です。
これらの関数はstd::vectorの内部実装に使用されており、std::vectorをconstexpr化する際にこれらの関数のconstexpr化が必要となることが発覚し、提案に至ったようです。
その際に問題になるのが、std::uninitialized_default_constructの効果で、C++20で追加されたconstexprな配置newを行うstd::construct_atを使ってしまうとデフォルト初期化ではなくゼロ初期化になってしまうためstd::construct_atを利用できないのですが、現状それ以外にconstexprな配置newを行う方法がありません。
(std::construct_atは未初期化領域へのポインタpだけが与えられると::new(p) T()相当の初期化を行い、これはゼロ初期化され、Tのコンストラクタが無い時その領域がゼロ埋めされます。一方std::uninitialized_default_constructは、その領域に対して::new(p) T相当の初期化を行い、これはデフォルト初期化され、Tのコンストラクタが無い時なにもしません。)
これを回避するために、この提案ではconstexprな配置newによるデフォルト初期化を行うstd::default_construct_at関数を追加し、それを利用してstd::uninitialized_default_constructをconstexpr化することを提案しています。
なお、ExecutonPolicyを取るオーバーロードはconstexpr対応されません。
これはMSVC STLにおいてstd::vectorをconstexpr化する過程で発覚し、既に実装されているようです。
- C++1z 未初期化メモリのアルゴリズムと、デストラクタ呼び出しの関数 - Faith and Brave - C++で遊ぼう
<memory>- cpprefjpstd::construct_at- cppreference- デフォルト初期化 - cppreference
- ゼロ初期化 - cppreference
- Implement constexpr std::vector - microsoft/STL
- Make uninitialized_meow helpers constexpr - microsoft/STL
- P2283 進行状況
P2285R0 Are default function arguments in the immediate context?
関数テンプレートのテンプレートパラメータに依存するデフォルト引数のインスタンス化の失敗をSFINAEできるようにする提案。
現在の規格では関数テンプレートのデフォルト引数のインスタンス化に失敗した時、そこがSFINAEできる文脈(immediate context)であるかどうかが規定されていないようです。例えば、次のようなコードで多様な結果を得ることができます。
template <typename T, typename Allocator> struct container { // アロケータ型をデフォルト構築しているデフォルト引数 template <std::ranges::range Range> explicit container(Range r, Allocator a = Allocator()) {} }; // デフォルト構築できないアロケータ型 struct Alloc { Alloc() = delete; // ... }; int main() { // Clang, ICCはここでコンパイルエラー constexpr bool c = std::constructible_from<container<int, Alloc>, std::vector<int>>; // GCC : 0 (false), MSVC : 1 (true) std::cout << c << std::endl; }
この提案はこれを明確化し、デフォルト引数のインスタンス化の失敗はSFINAEできる文脈であると規定しようとするものです。
これによって、コードを次のように改善できるようになります。
| 現在 | この提案 |
|---|---|
template<class Hash, class Equal, class Allocator> struct Map { template<class Range> explicit Map(Range&&, Hash, Equal, Allocator); template<class Range> explicit Map(Range&& c, Hash h, Equal e) requires default_initializable<Allocator> : Map(c, h, e, Allocator()) {} template<class Range> explicit Map(Range&& c, Hash h) requires default_initializable<Equal> && default_initializable<Allocator> : Map(c, h, Equal(), Allocator()) {} template<class Range> explicit Map(Range&& c) requires default_initializable<Hash> && default_initializable<Equal> && default_initializable<Allocator> : Map(c, Hash(), Equal(), Allocator()) {} }; |
template<class Hash, class Equal, class Allocator> struct Map { template<class Range> explicit Map(Range&&, Hash = Hash(), Equal = Equal(), Allocator = Allocator()); }; |
- CWG Issue 2296. Are default argument instantiation failures in the “immediate context”?
- SFINAE & immediate context - togetter
- P2285 進行状況
P2286R0 Formatting Ranges
任意の範囲を手軽に出力できる機能を追加する提案。
例えば文字列を分割してその結果をコンソール出力しようと思った時、C++20では次のように書くことができます。
#include <iostream> #include <string> #include <ranges> #include <format> int main() { // 文字列の分割(右辺値stringをsplitできない) std::string s = "xyx"; auto parts = s | std::views::split('x'); // これは出来ない std::cout << parts; // P2093のstd::print、これもできない std::print("{}", parts); std::cout << "["; char const* delim = ""; for (auto part : parts) { std::cout << delim; // これもできない std::cout << part; // std::print、当然できない std::print("{}", part); // これはできる! std::ranges::copy(part, std::ostream_iterator<char>(std::cout)); // これもできる!! for (char c : part) { std::cout << c; } delim = ", "; } std::cout << "]\n"; }
{fmt}ライブラリを使うと、次のように書けます。
#include <ranges> #include <string> #include <fmt/ranges.h> int main() { std::string s = "xyx"; auto parts = s | std::views::split('x'); fmt::print("{}\n", parts); fmt::print("[{}]\n", fmt::join(parts, ",")); // 出力 // {{}, {'y'}} // [{},{'y'}] }
しかしこれはstd::formatには含まれていません。
この提案は、{fmt}ライブラリのこの機能をstd::formatに追加しようとするものです。
範囲も含めて以下のものに対してフォーマッタの特殊化を追加することを目指しています。
value_typeとreferenceがフォーマット可能な任意の範囲- 2つの型が共にフォーマット可能な
std::pair<T, U> - 全ての型が共にフォーマット可能な
std::tuple<Ts...> std::vector<bool>::reference、boolと同じようにフォーマットする
フォーマットの方法(範囲やpair/tupleを[...]/{...}のどちらでフォーマットするかなど)は実装定義とし、fmt::joinに倣ったstd::format_joinの様なものを追加することも提案しています。
P2287R0 Designated-initializers for base classes
基底クラスに対して指示付初期化できるようにする提案。
C++20にて、集成体型に対する指示付初期化が出来るようになりましたが、それは直接のメンバに対してのもので、基底クラスのメンバに対しては行えませんでした。
struct A { int a; }; struct B : A { int b; }; int main() { A a = { .a = 1 }; // ok B b1 = { {2}, 3 }; // ok B b2 = { 2, 3 }; // ok B b3 = { .a = 4, .b = 5 }; // ng B b4 = { {6} .b = 7 }; // ng B b5 = { { .a = 8} .b = 9 }; // ng }
基底クラスのメンバを指定できないため、指示付初期化と通常の初期化が混在してはいけないというルールを守ることができず、結果として継承している集成体では指示付初期化できなくなっています。
この提案は、基底クラスを指定して指示付初期化できるようにしようとするものです。
その際問題になるのが、基底クラスをどうやって指定するのかという事です。現在のC++には基底クラスを明示的に指定するような構文は存在していません。
この提案では、集成体初期化子の先頭で、:に続いて基底クラス名を指定することで指示子とする事を提案しています。
template <typename T> struct C { T val; }; struct D : C<int>, C<char> {}; int main() { B b1 = { :A = { .a = 1}, b = 2 }; B b2 = { :A{ .a = 1}, b = 2 }; D d = { :C<int>{.val = 1}, :C<char> = {.val=`x`} }; }
この提案では基底クラスを指定するための方法を追加することだけが目的で、指示付初期化の他の部分を変更していません。従って、指示子の有無が混在することやその順番が宣言順と異なることも許可されません。
次
2週間後くらいかな・・・