この記事はC++ Advent Calendar 2021の21日目の記事です。
ExecutorとNetworking TS
Executor
Executorライブラリは、非同期並行処理の制御のための基盤となる機能を提供しようとするものです。
標準インターフェースを介して様々なハードウェアリソースへアクセスする方法と非同期処理のグラフを表現する方法を提供し、処理がいつどこで行われるのかをプログラマが制御可能とするためのライブラリです。
- P2300R3
std::execution - P2470R0 Slides for presentation of P2300R2:
std::execution(sender/receiver) - [翻訳]P0443R13 A Unified Executors Proposal for C++ - 地面を見下ろす少年の足蹴にされる私
Networking TS
Networking TSは、標準ライブラリに基礎的なソケット通信の機能を追加しようとするものです。
Networking TSはBoost.Asioをベースとして設計されており、一部変更されている部分はあるもののBoost.Asioほぼそのままの形で利用することができるようになっています。
Networking TS(Boost.Asio)は、非同期I/O操作のために非同期処理のサポート機構、すなわちExecutorに相当するものを内包しています。そのため、ExecutorライブラリはNetworking TSの一部であり、ベースとなるものとされます。
現在のC++標準化委員会では、Executorを導入してからNetworking TSをそれをベースとするように修正し導入する、といった感じで作業が進められています(した)。
ExecutorもNetworkingも、C++20策定時点ではC++23に導入される見込みであるとされており、実際設計も固まっていたのでほぼ内定だろうと思われていました・・・
Executorの道程
AsioにおけるExecutorの発見
AsioにおけるExecutorは開発の早い段階で見出され、2006年ごろにはasio_handler_dispatch()(後にasio_handler_invoke())と言う名前のADLカスタマイズポイントとして実装されました。
namespace mine { template <typename Handler> class counting_handler { void operator()(...) { // invoke handler } Handler handler_; }; // counting_handlerに対するカスタマイズasio_handler_invoke template <typename Function> void asio_handler_invoke(Function function, counting_handler* context) { // increment counter // invoke function } } int main() { // ... mine::counting_handler handler(&handle_read); // 非同期Read boost::asio::async_read(socket, buffer, handler); }
Asioの実装内で、asio_handler_invokeは利用されます。
namespace boost::asio { // デフォルトのasio_handler_invoke() template <class Function> void asio_handler_invoke(Function& function, ...) { function(); // デフォルトは現在のスレッド } // async_readの実装とする auto async_read(const Socket& socket, Buffer& buffer, Handler handler) { // I/O操作・・・ // ADLによるasio_handler_invokeを介したhandlerの呼び出し using asio_handler_invoke; asio_handler_invoke(handler, ...); } }
(細部を端折っている雑な例であることをお許しください)
これによって、Asioの提供する非同期操作に与える完了ハンドラによって、そのハンドラが呼び出される場所(実行コンテキスト)とその方法を制御することが可能となります。これは例えば、非同期処理の完了ハンドラでさらに非同期処理をネストさせて呼び出すときに全てのハンドラを1つのスレッドで実行させたい場合などに使用できます。
これはC++11にムーブセマンティクスが導入された際にムーブオンリーなハンドラに対応できない問題が発覚し(この詳細はよくわかんないです・・・)、それに対処するためにassociated_executorに変更され、その際にカスタマイズポイント自体(associated_executor)から実行コンテキストの表現(上記例のcontext)が分離されました(これはどうやら、Networking TSに移植する際に変更されたようです)。
namespace boost::asio { // 完了ハンドラからexecutorを取得するためのtraitsクラス template<class T, class Executor = system_executor> struct associated_executor { using type = T::executor_type; // T::executor_typeがなければ using type = Executor; static type get(const T& t, const Executor& e = Executor()) noexcept { return t.get_executor(); // T::executor_typeがなければ return e; } }; // async_readの実装とする auto async_read(const Socket& socket, Buffer& buffer, Handler&& handler) { // I/O操作・・・ // 完了ハンドラに関連づけられたexecutorを取得する auto ex = associated_executor<Handler>::get(handler); // exの場所でexによって指定された方法で完了ハンドラを実行 dispatch(ex, std::forward<Handler>(handler), ...); } }
ここで出てくるexこそが今日Executorと呼ばれているものです。associated_executorは非同期操作の完了ハンドラ型に対して部分特殊化しておくことでカスタムすることができ、その::get()から得られるExecutorによって完了ハンドラが実行される場所を指定します。何もカスタムしなければデフォルトのsystem_executorが使用され、これは別のスレッド(スレッドプール内の任意のスレッド)で完了ハンドラを実行します。
WG21 SG1におけるUnified Executorの追求
Asioでの動きを受けてかそれとは別かはわかりませんが、2012〜2015にかけていくつかの異なるExecutorの提案がSG1(Study Group1 : Concurrency Study Group)に提出されました。
1つはgoogleからのもの
class executor { public: virtual void add(function<void()> closure) = 0; virtual void add_at(time_point abs_time, function<void()> closure) = 0; virtual void add_after(duration rel_time, function<void()> closure) = 0; ... }; class thread_pool : public executor { ... };
1つはAsioからのもの
class my_executor { public: template<class Function, class Allocator> void dispatch(Function&& f, const Allocator& alloc); template<class Function, class Allocator> void post(Function&& f, const Allocator& alloc); template<class Function, class Allocator> void defer(Function&& f, const Allocator& alloc); execution_context& context() noexcept; ... };
1つはNVIDIAからのもの
template<class Executor> struct executor_traits { template<class Function> static future<auto> async_execute(Executor& ex, Function f); template<class Function> static future<auto> async_execute(Executor& ex, Function f, shape_type shape); template<class Function> static auto execute(Executor& ex, Function f); template<class Function> static auto execute(Executor& ex, Function f, shape_type shape); ... };
Googleのものは任意のスレッドプールの共通インターフェースとして設計されており、AsioはExecutorとExecution Contextが分かれていたり、NVIDIAのものはおそらくGPUでの実行を意識してバルク実行インターフェースを備えていたりと、それぞれが必要とするユースケースによって提案されたExecutorの設計は微妙に異なっていました。
これを受けてSG1では、これらのニーズとユースケースを満たしつつそれぞれの提案の問題点を解決するような統一的なExecutorモデルが模索され、2016年10月に最初のUnified ExecutorであるP0443R0 A Unified Executors Proposal for C++が提案されました。
P0443R0はかなりNetworking TSのExecutorの影響が見られるものでしたが、その後議論を経て洗練されていきコンセプトとCPOベースの非常にジェネリックなライブラリとして進化していきました。
2019年7月のSG1の全体投票においてP0443の設計をExecutorライブラリとして承認し、C++20標準への導入を目指してLEWGでのレビューが開始されました。また、先立つ2019年5月には、SG1の投票において将来的にP0443が標準化された時に、Networking TSをP0443ベースに書き換えることに全会一致で合意が取れていました。
C++標準化において、ライブラリ提案は各SG->LEWG->LWGの3段階のレビュープロセスを踏みます。また、各SGでは方向性やコンセプトの決定と最初の設計を行い、LEWGでは設計を集中的にレビューし、LWGでは標準に提案する文書についてのレビューを主に行います。
なかなか巨大なこともあってC++20には間に合わず、その後COVID-19パンデミックが直撃したこともありレビューは遅れ、2020年夏頃からLEWGのリソースを全力投入する形で、P0443をいくつかの部分に分割して個別のグループによってレビューされました。提案が巨大で歴史のあるものであったこともありレビューは困難を極めたようで、Executorの設計とその歴史についてLEWGのメンバに周知を図る必要性が提起されたりしましたが、レビューは為されそこそこの数の問題が報告されました。とはいえP0443を根本的にボツにする致命的なものはなかったようです。
2020年8月ごろには、AsioはP0443のExecutorを実装してリリースされました。これはP0443の実装経験を得るためでもあるようです。
その後2020年12月のLEWGのレビューで、P0443からいくつかの部分が別の提案に分離されることが決定された他はほぼ設計が固まったように見え、一部の人から実装経験について心配する声が上がっていましたが、C++23に向けて作業されていました。
2021年5月ごろにはP0958R3(Networking TSをP0443ベースに書き換える提案)とP1322R3(Networking TSの各APIが任意のExecutorを受け取れるようにする提案)がSG4(Networking Study Group)を全会一致で通過し、LEWGに転送されました。この2つの提案はNetworking TSをP0443に対応させるためのものです。
P2300 std::execution
P0443そのものは半年ほどは目立った(外部から観測できる)動きはなかったのですが、2021年6月、P0443を置き換える新しいExecutorライブラリであるP2300R0 std::executionが提案されました。P2300はP0443をベースとしていくつかの問題を解決した上で、分離して提案されていた非同期アルゴリズムライブラリを含むさらに大きなライブラリで、C++における非同期処理に関する大統一モデルの構築を目指しているものです。
P2300はすぐR1に改稿されLEWGで議論を重ねていたのですが、2021年7月ごろのレビューでP2300のsender/receiverによる非同期モデルとNetworking TS(Asio)の非同期モデルが異なっていることが指摘されました。P2300を大統一非同期モデルとして追求していくなら、Networking TSのExecutor部分に対して大きな変更が必要となります。一部の人は、P2300によるそのような大統一モデルの必要性と有効性に疑問を呈すとともに、Networking TSをP2300から分離すべきだと主張し始めたようです。
2021年8月初旬のLEWGレビューにおける方向性を探る投票においては、大統一非同期モデルの必要性についてはコンセンサスが得られなかったものの、C++標準ライブラリのstructured concurrency保証のソリューションとしてP0443の代わりにP2300を追求する方向性には強いコンセンサスが得られました。
2021年8月中旬のLEWGレビューではP2300の第一ピリオドとして次の改稿のためのまとめが行われ、P2300のモデルを説明するための例の充実やコルーチンとの関係性や既存の標準並列アルゴリズムとどう統合されるかなど、主に説明や解説を追記していくことが指示されました。一方で、大統一非同期モデルについては単一のモデルでカバーするには領域が広すぎるという意見や、P2300はstructured concurrencyと並行性という狭いスコープに焦点を当てて標準化し、標準ライブラリの他の部分(Networking TSなど)は別の非同期モデルを選択できるようにした方が良いのではないかという意見があったようです。
この時点で、Executorの議論は完全にP2300に移り、P0443と関連する提案の追求はストップされました。
2021年9月の1回目のLEWGレビューにおいて、7月ごろに指摘されたNetworking TSとの間の問題について、LEWGのメンバに向けて解説が行われたようです(P2444R0、P2463R0)。これらの提案・スライドの作成および説明は、Asioの作者自らによって行われています。これを受けて方向性を探る投票が行われ、Networking TSを今のまま(P2300に対応せず)C++23に導入するコンセンサスは得られませんでしたが、P2300をC++23に導入するコンセンサスも得られませんでした。これは方個性を決定する投票ではないためP2300とNetworking TSがこれで終わるわけではありませんでしたが、ExecutorとNetworkingのC++23入りについて暗雲が立ち込め始めます。
2021年9月の2回目のLEWGレビューではNetworking TSとP2300をどう進めていくかについて本格的に議論されることになり、Networking TSとP2300を切り離した場合に後からP2300とNetworking TSを相互運用可能なようにラッパーを書くことができるか、あるいは(Asioが必要とする)プロパティ指定方法なしでP2300をC++23に導入した場合に後でそれを追加できるか?などが議論されたようです。
ここでも方向性を探るための投票が行われ、大統一非同期モデルの必要性についてはコンセンサスが得られず、Networking TSとP2300のC++23入りについても前回同様の結果となりました。
2021年10月公開の提案文書では、このP2300とNetworkingTSの問題に関連する提案(報告書)がいくつも提出されました。
- P2464R0 Ruminations on networking and executors
- Networking TSをP0443ベースで標準化すべきではない
- P2300の開発に専念し、完成後にそれにフィットするネットワークライブラリを標準化したほうがいい
- P2469R0 Response to P2464: The Networking TS is baked, P2300 Sender/Receiver is not.
- ↑に反論する文書
- P2300は非同期モデルを提案するものではなく非同期DSLを提案するものにすぎない
- ASIOは実装経験に裏打ちされた非同期モデルをもっており、P2300の実質スーパーセットである
- P2479R0 Slides for P2464
- P2471R0 NetTS, ASIO and Sender Library Design Comparison
- Networking TSとAsioとP2300を比較するもの
- P2480R0 Response to P2471: "NetTS, Asio, and Sender library design comparison" - corrected and expanded
- ↑に対して間違いを指摘する提案
- P2471R1 NetTS, ASIO and Sender Library Design Comparison
- ↑を受けての修正版
これを受けて、10月のLEWGレビューでもP2464とP2469について議論されたようです。双方の支持者は、互いが互いの上に構築できる(P2300の上にNetworking TSを構築できるし、Networking TSの上にP2300を構築できる)と主張していて、議論の主題はエラー処理に関することでした。Networking TSのExecutorモデル(およびP0443のexeecutor)はエラー通知に関するチャネルを持たず、特に処理が実行コンテキストに投入されてから実行されるまでの間に起きるスケジューリングエラーをハンドルする方法を提供しないことが懸念されたようです。もう一つの論点はパフォーマンスに関することで、P2300のモデルではsender/receiverオブジェクトの構築に伴う受け入れがたいオーバーヘッドが発生すると考えている人が多かったようです。
これらの問題についてP2300/Networking TSをどう進めていくかの方向性を決定するために、LEWGおよびSG1のメンバで次の項目について投票を行いました
- Networking TS/Asioの非同期モデルは、ネットワーキング・並列処理・GPUなどのほとんどの非同期ユースケースの優れた基盤である
- 弱い否決
- P2300の非同期モデルは、ネットワーキング・並列処理・GPUなどのほとんどの非同期ユースケースの優れた基盤である
- コンセンサス
- C++の標準ネットワークライブラリとして、Networking TSを追求するのをやめる
- 否決
- C++標準ネットワークライブラリは、P2300をベースとすべき
- 弱いコンセンサス
- C++標準ネットワークライブラリを、TLS/DTLSサポートなしで出荷することを容認する
- 否決
2番目の投票は反対9に対して賛成40と大差がついています。3番目の投票は反対16に対して賛成26でしたが、賛成票を投じた人の多くはNetworking TSを白紙に戻したいのではなく、P2300の上に構築したいという意図のようです。
これによって、LEWG/SG1およびSG4の方向性は
- Networking TS/Asioの非同期モデルをベースとしてP2300を構築しない
- Networking TS/Asioの非同期モデルはネットワーキングのためのモデルとして追及したほうがいい(するなら
- LEWGはC++23に向けてP2300の作業を続行する
- Networking TSは死んでいない
- Networking TSを標準に導入するためには、非同期モデルとセキュリティについての作業が必要となる
- この作業は重く、C++23に間に合う可能性は低い
- Networking TSがP2300ではない非同期モデルを採用するなら、説得力のある提案が必要となる
一応はこれで決着を見たはずです、火種は残ってる気がしますが・・・
この結果に従って、12月まではP2300がLEWGにて引き続きレビューされていますがLWGに進めてはいません。今のところ、Networking TS絡みで大きな問題はないようです。
C++23 Feature Complete
まだ2023年までは時間がありますが、あらかじめ決められているスケジュール(P1000R4)として、C++23に導入する機能の設計は2022年2月7日までに完了していることが求められています。
LEWGの予定表(P2489R0)によれば、P2300のLEWGにおけるレビューの機会はあと一回(2022年1月11日)で、LWGへ進めるための投票の機会もあと一度(2022年1月14日~)です。
前述のように、Networking TSは実質的に作業がストップしており、非同期モデルとセキュリティという2つの重い課題を抱えているので、C++23には間に合わないでしょう。Executorが間に合うかは来年2週目のLEWGのテレコンレビューで設計を完了できるかで決まります。
各ライブラリの雰囲気
経緯はわかりましたがそれを眺めただけではなぜ紛糾していたのかがよくわからないでしょう。ここではP0443, P2300, Asio(Networking TS)の設計の雰囲気を見ていくことで、P2300 vs Asioの背景を探ります。
P0443
P0443におけるExecutorとは次のように使用される何かです。
// P0443のAPIはstd::execution名前空間の下に定義される using namespace std::execution; // 任意の場所(たとえばスレッドプール)で処理を実行するexecutorを取得する std::static_thread_pool pool(16); executor auto ex = pool.executor(); // この記法はコンセプトによる変数の制約 // 高レベルのライブラリによる処理がどこで実行されるかを制御するためにexecutorを使用する perform_business_logic(ex); // あるいは、P0443によるよりプリミティブなAPIを直接使用することもできる // スレッドプールに処理を投げ、すぐ実行する execute(ex, []{ std::cout << "Hello world from the thread pool!"; }); // スレッドプールに処理を投げすぐ実行し、完了まで現在のスレッドをブロックする execute(std::require(ex, blocking.always), foo); // 依存性のある一連の処理を記述し、後で実行する sender auto begin = schedule(ex); sender auto hi_again = then(begin, []{ std::cout << "Hi again! Have an int."; return 13; }); sender auto work = then(hi_again, [](int arg) { return arg + 42; }); // 処理の最終結果を標準出力へ出力する receiver auto print_result = as_receiver([](int arg) { std::cout << "Received " << std::endl; }); // 先ほど定義したworkによる処理をreceiverと組み合わせてスレッドプールで実行する submit(work, print_result);
ここで、exという変数で示されているものがP0443のExecutorであり、それはexecutorコンセプトを満たす任意の型のオブジェクトです。executorコンセプトは単純には次のようなものです。
template<typename E> concept executor = requires(const E& e) { {execution::execute(e, [] -> void {})} -> void; };
execution::executeはCPOであり、execution::execute(ex, f);のようにして、Executorexに任意の処理f(引数なし、戻り値なし)を投入します。他にも細かい指定があるのですが、一番重要な性質はこのexecuteCPOによって指定されるものです。
executeCPOによる処理の投入は単純な処理の投入のみをサポートしており、その実行に際しては追加の引数を取らず戻り値を返しません。そのためexecutorは処理の戻り値の取得やエラーハンドル、処理のスケジューリングとそのキャンセルなどの方法を提供せず、その能力を持ちません。
executorはこのようにインタフェースを制限することで、処理が実行されうる任意のハードウェア(CPU/GPU/SIMDユニット/スレッド...)を抽象化しており、それらのハードウェアリソース(まとめて実行コンテキストと呼ばれる)の軽量なハンドルとして統一的なアクセスを提供します。executorに実際に処理がどのように投入されるのか、実行がいつ行われるのか、どのように実行されるのか、はexecutorという抽象の中に覆われます。
// 単純なexecutorの実装例 struct inline_executor { template<class F> void execute(F&& f) const noexcept { // 現在のスレッドで即時実行 std::invoke(std::forward<F>(f)); } // 実行コンテキストの比較 auto operator<=>(const inline_executor&) const = default; }; struct thread_executor { template<class F> void execute(F&& f) const noexcept { // 別のスレッドを起動してそこで実行 std::thread th{std::forward<F>(f)}; th.detach(); } auto operator<=>(const thread_executor&) const = default; };
この2つのexecutor実装を眺めると、それぞれには異なる性質(プロパティ)がある事に気付きます。つまり、execute(ex, f)した時にブロッキングするかしないか、あるいはexecute(ex, f)が戻った時に処理が完了しているかどうかです。このようなexecutorのプロパティは他にもいくつも考えることができて、時にはそのプロパティを制御したくなるでしょう。このようなプロパティはexecutorの最小の契約の範囲外ですが、それを制御するために、require/preferによるプロパティ指定が用意されます。
// 何かしらのexecutorを取得する executor auto ex = ...; // 実行にはブロッキングが必要という要求(require executor auto blocking_ex = std::require(ex, execution::blocking.always); // 特定の優先度pで実行することが好ましい(prefer executor auto blocking_ex_with_priority = std::prefer(blocking_ex, execution::priority(p)); // ブロッキングしながら実行、可能ならば指定の優先度で実行 execution::execute(blocking_ex_with_priority, work);
requireによるプロパティの指定は強い要求で、不可能な場合コンパイルエラーとなります。一方、preferは弱い要求であり、不可能な場合でも無視されコンパイルエラーにはなりません。require/preferによるプロパティの指定は、executorをそのプロパティを持つexecutorに変換するものであり、プロパティ指定後得られたものもまたexecutorとして扱うことができます。
executorは処理を投入した後からその処理について何かをハンドルする能力を持ちません。これは基盤的な共通のAPIとしては良いものかもしれませんが、非同期処理グラフを構成し、その実行を制御するための基盤としては表現力が足りません。P0443はゴールとしてそのような非同期アルゴリズムAPIを整えることを目指しており、そのためにexecutorよりも強い保証を持つものと、非同期処理及びそのコールバックに関する共通の基盤が必要となります。
P0443ではそのために、Scheduler、Sender/Receiverという3つの抽象を定義します。
Schedulerとはexecutor同様にschedulerコンセプトを満たす任意の型のことです。
template<class S> concept scheduler = requires(S&& s) { {execution::schedule((S&&)s)} -> sender; };
(これは簡略化したものですが)定義もexecutor同様に、execution::scheduleCPOによってその実行コンテキストでスケジューリングされるsenderオブジェクトを取得可能な任意の型を指定します。schedulerもexecutor同様に実行コンテキストへのハンドルとしての役割を持ちますが、executorとは異なり処理の実行を遅延して実行コンテキストへ投入することができ、またその間のキャンセル操作に対応(sender/receiver経由で)しています。
senderは任意の非同期処理(特に、まだスケジュールされていない処理)を表現するもので、senderコンセプト(この定義はほぼ何も言わないので省略)によって指定されます。scheduleCPOによって得られるsenderというのは、そのscheduler上で実行される何もしない処理を表現しており、それに対して非同期アルゴリズムを適用することで非同期処理グラフを構成していくことができます。
// P0443の目指した世界の一例 sender auto s = just(3) | // 即座に`3`を生成 via(scheduler1) | // 実行コンテキストを遷移(変更) then([](int a){return a+1;}) | // 継続処理をチェーン then([](int a){return a*2;}) | // さらにもう一つ継続処理をチェーン via(scheduler2) | // 実行コンテキストを遷移(変更) handle_error([](auto e){return just(3);}); // エラーハンドル、デフォルト値を返すようにする int r = sync_wait(s); // 一連の処理を実行し、結果を待機
ただし、これらの非同期アルゴリズムAPIはP0443の一部ではなく別の提案(P1341R0)で提案されているもので、P0443はExecuotrのコアな部分を整備しようとする提案です(した)。
これらの非同期アルゴリズムとは単純には次のように、senderを受け取りsenderを返すものです。
template<typename A> concept async_algorithm = requires (A alg, sender s) { alg(s) -> sender; };
パイプライン演算子(|)の場合、s | alg -> senderのようになります。つまりは各非同期アルゴリズムは、senderという抽象にのみ入出力を依存することで、前段及び後段の処理が何をするか、あるいは実行コンテキストがどこであるのかということを意識せずに実装できるようになっています。この性質から、非同期アルゴリズムはSenderアルゴリズムとも呼ばれます。
senderコンセプトは構文的に何か特別なことを求めておらず、senderだけでは処理結果の取得すら行うことができません。senderの表現する処理から結果を取得(またはエラーハンドリング、キャンセル)するには、receiverを用います。
template<class T, class E = exception_ptr> concept receiver = requires(remove_cvref_t<T>&& t, E&& e) { { execution::set_done(std::move(t)) } noexcept; { execution::set_error(std::move(t), (E&&) e) } noexcept; }; template<class T, class... An> concept receiver_of = receiver<T> && requires(remove_cvref_t<T>&& t, An&&... an) { execution::set_value(std::move(t), (An&&) an...); };
receiverコンセプトは2つの部分に分かれていますが、set_done/set_error/set_valueという3つのCPOで使用可能であることを求めています。これらのCPOはそれぞれ、完了(キャンセル)・エラー・処理結果、を通知するチャネルであり、receiverとは3つの通知チャネルを持つコールバックです。これら3つのチャネルは、receiverオブジェクトが破棄される前に必ずどれか1つ呼ばれなければならず、1つが呼ばれたら残りの2つは呼ばれないと仮定することが許されており、この要件をreceiver contractと呼びます。
receiverをsenderに接続(connectCPO)することでそのsenderの処理結果をハンドルすることができて、receiverを接続されたsenderはreceiver contractを履行する義務を負います。senderの処理を実行するには、どこかの実行コンテキストに投入する必要があり、それはstart, sync_waitなどのCPOによって行えます。
sender auto work = just(3) | then([](int n) { return 2*n; }); // この時点では実行されていない // 処理を実行し完了を待機、receiverは用意される // schedulerを使用していないので処理は現在のスレッドで、即座に実行される int n = sync_wait(work);
// 任意のschedulerとreceiver scheduler auto sc = ...; receiver auto rec = ...; sender auto work = schedule(sc) | just(3) | then([](int n) { return 2*n; }); // この時点では実行されていない // senderとreceiverの接続 operation_state auto state = execution::connect(work, rec); // 後から実行、scの実行コンテキストで実行される execution::start(state); // ブロッキング有無や実行タイミングはsender(work)とscheduler(sc)による // 結果はrecが(ユーザーが指定した方法で)持っている // 例えば int n = rec.value(); // あるいは if (bool(rec)) { int m = *rec; } else { std::cout << rec.err_msg(); } // などなど・・・
sender/receiverとschedulerはお互いにコンセプトという抽象を介してしかお互いのことを知りません。そのため、この例のような処理の構成・実行は特定の型に依存せず、sender/receiverは(コンセプトを満たすように)自由に定義できますし、schedulerも任意のハードウェアのハンドルとなることができます。
多くの汎用非同期アルゴリズムは、同じ実行コンテキストに対して複数の実行状態を持ち得るため、特定の実行コンテキストで完了するsenderを非同期アルゴリズムで受け取って使用するだけでは不十分です。むしろ、非同期アルゴリズムの方をそのようなsender(特定の実行コンテキストで完了するsender)のファクトリに渡すほうが理にかなっており、そのようなファクトリがscheduler(とscheduleCPO)です。
非同期アルゴリズムを複数チェーンする場合、パイプライン演算子(|)はsenderとsenderに対して作用しており、その結果もsenderとなります。多段パイプを適用した時でも得られるものはsenderであり、そこにreceiverを接続するとパイプラインを遡るように各段でそれぞれの非同期アルゴリズムが用意するreceiverが接続されていきます。つまり、パイプラインによる接続部でも後段のsenderは前段のsenderの結果やエラーハンドリングをreceiverを介して行っています。これは複雑ではありますが、<ranges>のviewのパイプラインとやっていることは同じで、最終的なsenderオブジェクトおよびそれとreceiverをパッケージングするoperation_stateオブジェクト内部でマトリョーシカのように多段ラッピングされています(thenアルゴリズムの実装例)。
1つ注意点として、sender/receiverおよびoperation_stateなどは関数オブジェクト的なものではないため、そのままexecutorで実行可能ではありません。これらの非同期アルゴリズムによる処理の構成はexecutorではサポートできません。executorのインターフェースでは、結果を受け取ることもエラーをハンドルすることも、処理をキャンセルすることもできないからです。schedulerはscheduleを介してその実行コンテキストでの実行と完了を保証するsenderを返すことで任意のreceiverを利用可能となり、それによって3つの通知チャネルを獲得しています。
P2300
P2300はP0443にパッチを当てたものではなく、sender/receiverとSenderアルゴリズムを中心として、それが正しく働くようにP0443を進化・改善したものです。
using namespace std::execution; scheduler auto sch = thread_pool.scheduler(); // schedulerの取得 sender auto begin = schedule(sch); // schの実行コンテキストで完了するsenderを取得 sender auto hi = then(begin, []{ // thenアルゴリズムによる処理のチェーン std::cout << "Hello world! Have an int."; return 13; }); sender auto add_42 = then(hi, [](int arg) { return arg + 42; }); // thenアルゴリズムによる処理のチェーン auto [i] = this_thread::sync_wait(add_42).value(); // 構成した処理を実行コンテキストに投入し、完了を待機する
一見すると先ほど見たP0443のsender/receiverから大きな変化はないように思えます。
P2300のP0443との大きな違いは次のような点です
executorコンセプトの削除- 処理を投入するだけでは表現力不足であり、
sender/receiverと調和しない schedulerとsenderをベースとするように全体を書き換え
- 処理を投入するだけでは表現力不足であり、
- プロパティ指定の削除
- プロパティは
scheduler(実行コンテキスト)が備えている性質であり、変更可能ではない - 一部のプロパティについては問い合わせが可能
- 将来的に
require/preferベースのプロパティ指定を導入することはできる(より便利になれば)
- プロパティは
- Senderアルゴリズムの取り込み
senderの保証の強化- 特定の
senderが特定の実行コンテキストで完了する保証を追加- 実行コンテキストに処理をどう投入するか?という部分の抽象化が
executorからsenderに移された schedulerは実行コンテキストのハンドルとしてその実行コンテキストのためのsenderを生成する、senderファクトリの1つに過ぎない
- 実行コンテキストに処理をどう投入するか?という部分の抽象化が
sender型のconnect()オーバーロード(connectCPOの呼び出し先)を右辺値と左辺値で分けることで実行可能回数を表現する
- 特定の
executorの担っていた役割はschedulerとsenderへ移管されると共に、sender/receiverとSenderアルゴリズムがExecutorライブラリの中心に据えられた形です。とはいえ、sender/receiverとSenderアルゴリズムの雰囲気はP0443の頃から大きく変わってはいません。
P2300R3には、さらに多くのサンプルコードが掲載されています。眺めるとsender/receiverとSenderアルゴリズムの雰囲気をよりつかめるかもしれません。
Asio(Networking TS)
Networking TSはAsioをベースとしていますが、AsioはP0443を取り込む形で進化している一方でNetworking TSは2018年以降更新がないため、設計が少し変わっている部分があります。ここでは、現在のAsioを見てみます。
Asioにおける非同期処理は通常、I/O操作(主にネットワーク処理)の完了後にその結果を受けるコールバックとして起動されます。それらの機構をまとめて非同期操作(Asynchronous operation)と呼び、Asioにおける非同期操作は開始関数(Initiating function)と完了ハンドラ(Completion handler)からなります。非同期操作はAsioにおける非同期モデルの基本単位となります。
開始関数とは非同期I/O関数(soket.async_read_some()とかasio::async_write()など)のことで、完了ハンドラはそこに渡されるコールバック関数です。
// 呼び出しはすぐにリターンする socket.async_read_some(buffer, [](error_code e, size_t) { // bufferにsocketからのデータを読み込んだ後、呼び出される ... } );
Asioの非同期操作は、このような開始関数の行うI/O処理と完了ハンドラの呼び出しが、同期的に(シングルスレッドで順番に)実行された場合と同じように呼び出されることを保証します。それによって、開始関数(非同期I/O)の実行とコールバックの実行ではリソースの使用がオーバーラップする事がありません。そのため、完了ハンドラではそれを開始した非同期I/Oそのものを再帰的に呼び出した時でも、解放されないリソースが蓄積してリソース使用量が増大する事はありません。
// async_read_someの簡易実装例 // async_read_someはこのような実装を別スレッドで呼び出してリターンする void sokcet::async_read_some_impl(Buffer buffer, CompletionHandler handler) { // ソケットからのデータ読み出し処理 // ブロッキングと、リソースの確保など error_code ec{}; std::size_t len = this->io_read(buffer, ec); // 説明のための読み込み操作 // データの読み出しとbufferへの格納の完了後、完了ハンドラを呼び出す async(std::move(handler), std::move(ec), len); }
すなわち、完了ハンドラは開始関数の末尾で(おそらく非同期的に)呼び出され、完了ハンドラの実行が始まった時には開始関数は完了しておりそこで確保されたリソースは解放されています。すなわち、完了ハンドラが呼び出された時には開始関数は終了していることが保証され、完了ハンドラはI/O操作の詳細とほぼ無関係に実行されます。
完了ハンドラはさらに継続して別の非同期操作を実行することができます。それら非同期操作のチェーン全体およびそれらチェーンの進行を保証する仕組みのことを非同期エージェント(Asynchronous agent)と呼びます。非同期エージェントは概念的な存在というか、何か特定のライブラリ実体に結びつくものではなく、Asioの非同期モデルに組み込まれたある種のシステムです。
socket.async_read_some(buffer, [&socket, &buffer](error_code e, size_t) { // ... socket.async_read_some(buffer, [&socket, &buffer](error_code e2, size_t) { // ... socket.async_read_some(buffer, [&socket, &buffer](error_code e2, size_t) { // ここまで(およびこの先も)きちんと実行されることを保証する機構が実行エージェント // ... } }; } );
実行エージェントは複数の非同期操作からなり、実行エージェントのそれぞれの非同期操作内においての各完了ハンドラは、スケジューリング可能な作業の最小単位を表します。
非同期エージェントには、その一部となっている非同期操作がどのように動作するべきかを指定する次の3つの特性が関連づけられています
- Allocator
- 非同期操作がどのようにメモリリソースを取得するかを指定する
- Cancellation slot
- 非同期操作がどのようにキャンセル操作をサポートするかを指定する
- Executor
- 各完了ハンドラがどこで、どのように実行されるかを指定する
非同期エージェント内の各非同期操作が実行される時、その実装はこれらの関連づけられた特性を照会しそれらの指定する要件を満たすために使用します。非同期操作内では、完了ハンドラにassociator traitsを適用することでそのようなクエリを実行します。
// async_read_someの簡易実装例 // async_read_someはこのような実装を別スレッドで呼び出してリターンする void sokcet::async_read_some_impl(Buffer buffer, CompletionHandler handler) { // 関連づけられたアロケータの取得 auto alloc = associated_allocator<CompletionHandler>::get(handler); // 関連づけられたcancellation slotの取得 auto cancel = associated_cancellation_slot<CompletionHandler>::get(handler); // ソケットからのデータ読み出し処理 error_code ec{}; std::size_t len = this->io_read(buffer, ec, alloc, cancel); // 関連づけられたExecutorの取得 auto ex = associated_executor<CompletionHandler>::get(handler); // exの場所でexによって指定された方法で完了ハンドラを実行 dispatch(ex, std::move(handler), std::move(ec), len); }
associator traits(associated_xxx)は完了ハンドラ型(CompletionHandler)について特殊化することでユーザーがカスタマイズすることができます。
全ての非同期エージェントには関連づけられたExecutorがあり(カスタマイズしない場合でもデフォルトのものが関連づけられる)、非同期エージェントのExecutorは非同期エージェントの完了ハンドラがどのようにキューイングされ、どのように実行されるかを決定します。非同期エージェント内の非同期操作は、非同期エージェントに関連づけられたExecutorを使用して次のようなことを行います
- 非同期操作の実行中、その非同期操作を表す作業の存在を追跡する
- 非同期操作の完了時、完了ハンドラを実行するためにキューイングする
- 完了ハンドラがリエントラントに実行可能ではないことを保証する
- こうしない場合、完了ハンドラの2回以上の呼び出しによって意図しない再起やスタックオーバーフローに陥る可能性がある
このように、非同期エージェントに関連づけられたExecutorは、その非同期エージェントがいつ、どこで、どのように実行されるべきかというポリシーを表し、それを非同期エージェント全体にわたって横断的に指定します。
AsioにおけるExecutorの使用例としては
- 共有データ構造上で実行される非同期エージェントのグループを調整し、各エージェントの完了ハンドラが同時に実行されないようにする
- データまたはイベントソース(NICなど)に近い特定の実行リソース(CPU)上で非同期エージェントを実行する
- 関連のある非同期エージェントのグループを示し、スレッドプールがよりスマートなスケジューリングを行えるようにする(実行リソース間でエージェントを移動するなど)
- GUIアプリケーションのメインスレッドで実行される完了ハンドラを1つのキューに入れていくことで、UIを安全に更新する
- ロギング、ユーザー認証、例外処理など、完了ハンドラの実行前後に何か処理を実行する
- 非同期エージェントとその完了ハンドラの実行優先度を指定する
- デフォルトのExecutorを使用することで、非同期操作完了のトリガーとなったイベントから最速のタイミングで完了ハンドラを起動する
などがあります。ただし、AsioにおいてユーザーがExecutorをカスタムすることは稀であり、基本的にはExecutorの存在やそのカスタムを意識する必要はありません。
AsioにおけるExecutorは開始関数(非同期I/O操作)の末尾で、完了ハンドラの実行をカスタマイズするポイントであることから、tail callのカスタマイゼーションポイントと呼ばれます。
tail callの通り、完了ハンドラの実行時点で呼び出した開始関数は完了しているため、呼び出しに伴うエラーを処理したり完了ハンドラの結果を受けたりするのは後続の処理の責任となり、Executorを使用して呼び出した側(開始関数)はそれ以降の完了ハンドラで起こることに責任を持つ必要がなく、完了ハンドラを実行コンテキストへ送信する役割だけを負います。これは明らかにP0443のexecutorと親和性があり、実際追加のプロパティ指定を必要とするものの、Asioが元々持っていたExecutorはP0443のexecutorによって表現可能です。一方で、P2300のschedulerはexecutorの役割をsenderと分割して請け負っているなど、AsioのExecutorと互換性がありません。
tail callのカスタマイゼーションポイントはC#(.Net)ではSynchronizationContextとして知られており、細部は異なるものの他のところ(SwiftのExecutor、Java Netty libraryのEventExecutor)でも同様のものが見られます。このことは、AsioのExecutorモデルが決して的外れなものではないことを示しているといえます。
ここまでのことは、Networking TSとAsioで大きく変わらない事です。
C++11のstd::futureやC++20のコルーチン、P0443のSenderアルゴリズムなど、C++の進化に伴ってAsioはコールバック以外の非同期の継続メカニズムに対応する必要が出てきました。既存のコードに対する互換性を維持しつつAsioの非同期モデルに種々の非同期継続メカニズムを親和させるための仕組みが完了トークン(Completion token)です。
// コールバック socket.async_read_some(buffer, [](error_code e, size_t) { // 継続作業... }); // コルーチン awaitable<void> foo() { size_t n = co_await socket.async_read_some(buffer, use_awaitable); // 継続作業... } // future future<size_t> f = socket.async_read_some(buffer, use_future); // 継続作業... size_t n = f.get(); // fiber void foo() { size_t n = socket.async_read_some(buffer, fibers::yield); // 継続作業... }
完了トークンは開始関数(async_read_some)の最後の引数で受け取っているもの(ラムダ、use_awaitable、use_future、fibers::yield)です。つまり、完了トークンとは完了ハンドラを一般化したものです。トークンの名の通り必ずしも呼び出し可能なものでなくてもよく、そのトークンに応じて非同期操作(完了ハンドラを含む)の実行方法を柔軟にカスタマイズすることができます。
完了トークンを受け取る非同期操作では完了ハンドラの関数型(completion signature)を用意しておき、非同期操作の開始関数はcompletion signature、完了トークン、自信の内部実装をasync_result型(traitクラス)に渡します。async_resultはこれらの情報から具体的な完了ハンドラの作成と非同期操作の起動を行うカスタマイゼーションポイントです。
// 完了トークンを用いるasync_read_some実装例 template <class CompletionToken> auto async_read_some(tcp::socket& s, const mutable_buffer& b, CompletionToken&& token) { // 非同期操作を開始するための関数オブジェクトの定義 auto init = [](auto completion_handler, // async_resultから渡される完了ハンドラ tcp::socket* s, // async_resultから渡される追加の引数 const mutable_buffer& b) // async_resultから渡される追加の引数 { // 切り離されたスレッドで非同期操作を実行する std::thread( [](auto completion_handler, tcp::socket* s, const mutable_buffer& b) { error_code ec; size_t n = s->read_some(b, ec); std::move(completion_handler)(ec, n); // 完了ハンドラ呼び出し }, std::move(completion_handler), s, b ).detach(); }; // 非同期操作の起動と適切な戻り値の返却 return async_result<decay_t<CompletionToken>, // 完了トークンの型 void(error_code, size_t) // completion signature >::initiate(init, std::forward<CompletionToken>(token), // 完了トークンはasync_result内で適切な完了ハンドラに変換される &s, // 非同期操作に必要な追加の引数 b); // 非同期操作に必要な追加の引数 }
async_resultはAsioに予め用意されているクラスです。完了トークンとしてラムダなど呼び出し可能なものが渡された場合、それが完了ハンドラとしての要件を満たしていればデフォルトの実装が使用され、それは従来(上で説明したこと)と同じ意味や保証を持つ非同期操作の実行と完了ハンドラの呼び出しを行います。
// 完了ハンドラ用のデフォルト実装、引数を単純に転送するだけ template <class CompletionToken, completion_signature... Signatures> struct async_result { template<class Initiation, completion_handler_for<Signatures...> CompletionHandler, class... Args> static void initiate(Initiation&& initiation, CompletionHandler&& completion_handler, Args&&... args) { std::forward<Initiation>(initiation)(std::forward<CompletionHandler>(completion_handler), std::forward<Args>(args)...); } };
完了ハンドラは初期化関数の完了と共に即座に実行され、初期化関数そのものも即座に開始されるため、ここでは全ての引数のコピーが回避されます。しかし、遅延完了トークン(use_awaitableなど)では初期化関数の遅延起動のために引数をキャプチャしておく必要があります。例えば、単純なdeferredトークン(deferred_t deferred{};、操作をパッケージングするだけ)に対するasync_resultの特殊化は次のようになります。
template <completion_signature... Signatures> struct async_result<deferred_t, Signatures...> { // initiate()の戻り値=非同期操作の直接の戻り値は、完了トークン1つを受けて非同期操作を遅延実行する関数オブジェクト template <class Initiation, class... Args> static auto initiate(Initiation initiation, deferred_t, Args... args) { return [initiation = std::move(initiation), // 開始関数の実装詳細 arg_pack = std::make_tuple(std::move(args)...) // 非同期操作の追加引数をtupleで固めてキャプチャ ](auto&& token) mutable { return std::apply( [&](auto&&... args) { // 非同期操作を起動する return async_result<decay_t<decltype(token)>, Signatures...>::initiate( std::move(initiation), std::forward<decltype(token)>(token), std::forward<decltype(args)>(args)... ); }, std::move(arg_pack) ); }; } }; // 例えば次のように使って auto def = socket.async_read_some(buffer, deferred); // 後から実行、その際にもう一度完了トークンを指定できる size_t n = co_await def(use_awaitable);
完了トークンは任意にユーザーが定義することができて、完了トークン型と期待する完了ハンドラのシグネチャでasync_resultを特殊化し、そのinitiate()内でそのトークンの振る舞いを記述することでAsioの非同期操作の実行と完了ハンドラの呼び出しを制御することができます。
このような完了トークンはAsioに対してBoost1.54(2013年ごろ)で導入され、今の形になったのはBoost1.70(2019年5月)からのようです。
完了トークンを用いるとSenderアルゴリズムlikeな非同期アルゴリズムを構成することができます。
auto f = socket.async_read_some(buffer(data), use_then) .then([&](error_code e, size_t n) { return async_write(socket, buffer(data, n), use_then); }) .then([&](error_code e, size_t n) { return async_write(socket, buffer("\r\n", 2), use_then); }) .then(use_future);
これはuse_thenトークンに対してasync_resultを特殊化するという同様の手順で実装できます(P2463の後ろの方に実装例があります)。しかも、完了トークンを用いることでコルーチンなど他の継続スタイルと自然に同居することができています。
次の図はAsioの非同期モデルをまとめてその関係性を表したものです。
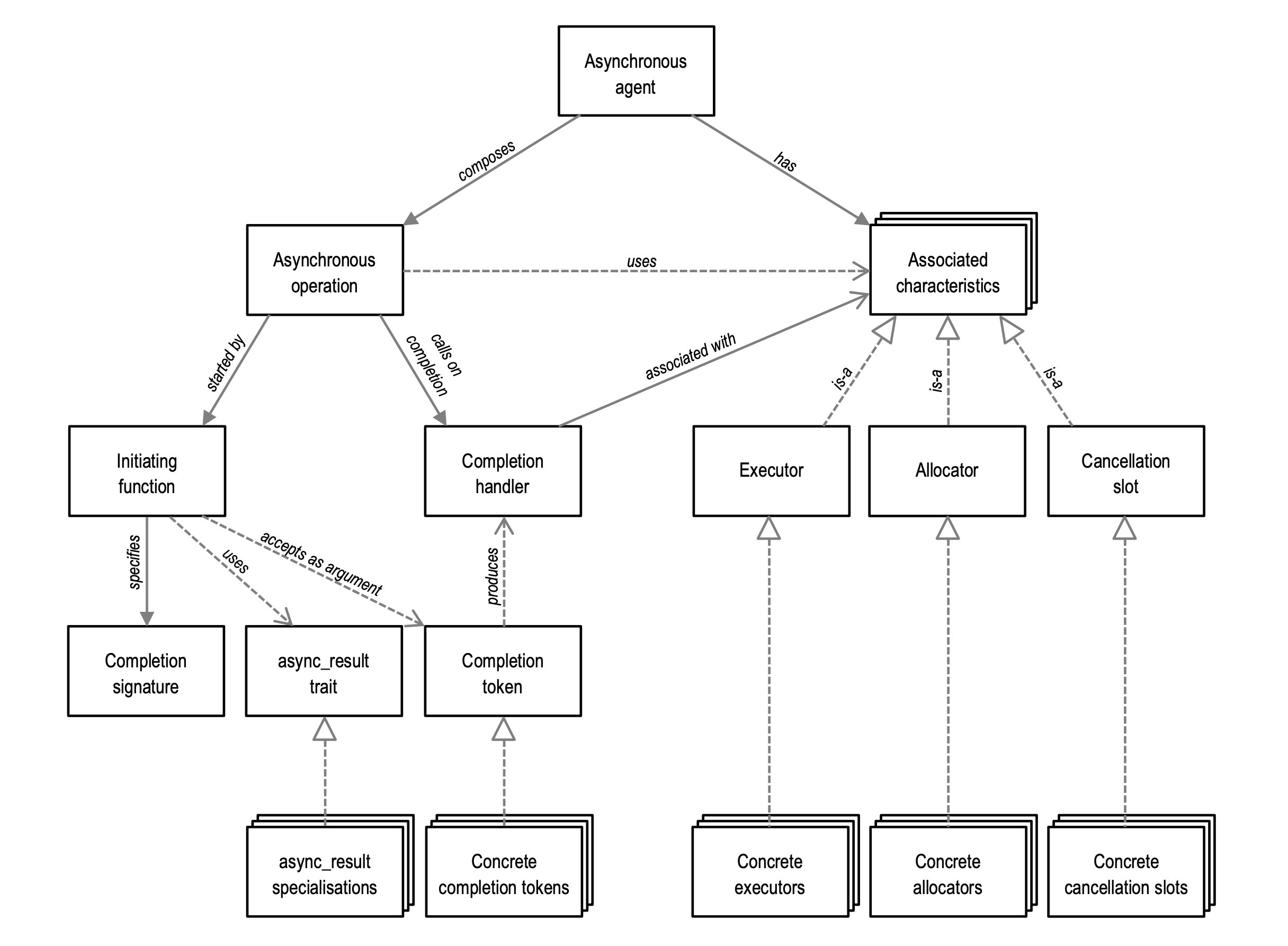
現在のAsioはすでにこのような非同期モデルに基づいて構築されており、部分にもよりますが数年〜10年以上の実装経験を持っています。
Networking TS(Asio)にとって問題だったこと
- Asioの要求するExecutorはtail callのカスタマイゼーションポイントであり、
schedulerと異なる - AsioのExecutorに対する操作(
dispatch/post/defer/)には少なくともExecutorのブロッキングプロパティを制御できる必要があるが、P2300で削除されている - Asioには10年以上の、P0443の部分も1年の実装経験があるが、P2300には実装経験がない
- 他の継続スタイル(コルーチンや
futureなど)のサポートがない - メモリ割り当て戦略についての考慮が不足している
- Asioには何十年にもわたって研究されてきた割り当て戦略がある
一部は実際には正しくないものもありますが、実装経験とAsioのExecutorとP2300のschedulerのミスマッチはかなり大きな問題です。
とはいえ経緯のところで見たように、LEWGとしてはP2300をC++23に向けて詰めていく方向性は確定しており、これらの問題が考慮されることはあっても、これらの問題によってP2300が止まることはなさそうです(多分executorが復活することもないでしょう)。一方で、Netowrking TSはExecutorの部分についてP2300ベースとするか今のまま行くのか(あるいは別のアプローチを取るのか)決定しなければならず、どちらにしても困難が待ち構えていそうです・・・
参考文献
- A Unified Executors Proposal for C++ | P0443R14
- P2033R0 - History of Executor Properties
- P2300R3
std::execution - P2430R0 Slides: Partial success scenarios with P2300
- P2431R0 Presentation: Plans for P2300 Revision 2
- P2444R0 The Asio asynchronous model
- P2470R0 Slides for presentation of P2300R2:
std::execution(sender/receiver) - P2463R0 Slides for P2444r0 The Asio asynchronous model
- P2464R0 Ruminations on networking and executors
- P2469R0 Response to P2464: The Networking TS is baked, P2300 Sender/Receiver is not.
- P2479R0 Slides for P2464
- P2471R1 NetTS, ASIO and Sender Library Design Comparison
- P2480R0 Response to P2471: "NetTS, Asio, and Sender library design comparison" - corrected and expanded
- P0443 A Unified Executors Proposal for C++ - cplusplus/papers
- P2300
std::execution- cplusplus/papers - P1322 Networking TS enhancement to enable custom I/O executors - cplusplus/papers
- P0958 Networking TS changes to support proposed Executors TS - cplusplus/papers
- Networking TS の Boost.Asio からの変更点 - その 3: Executor - あめだまふぁくとりー
- Networking TS の Boost.Asio からの変更点 - その 4: Associated Executor - あめだまふぁくとりー
- 並列コンピューティング SynchronizationContext こそすべて - MSDNマガジン
- P1943R0 Networking TS changes to improve completion token flexibility and performance