C++標準化委員会の論文(提案文書)公開がコロナウィルスの影響もあって月1になり量がお手頃になったので、4/20公開の提案文書をさらっと見てみます。
文書の一覧 www.open-std.org
提案文書で採択されたものは今回はありません。
- N4858 : Disposition of Comments: SC22 5415, ISO/IEC CD 14882
- N4859/N4860/N4861
- P0533R6 : constexpr for <cmath> and <cstdlib>
- P0870R2 : A proposal for a type trait to detect narrowing conversions
- P1255R6 : A view of 0 or 1 elements: views::maybe
- P1315R5 : secure_clear
- P1641R3 : Freestanding Library: Rewording the Status Quo
- P1654R1 : ABI breakage - summary of initial comments
- P1949R3 : C++ Identifier Syntax using Unicode Standard Annex 31
- P2011R1 : A pipeline-rewrite operator
- P2013R1 : Freestanding Language: Optional ::operator new
- P2034R1 : Partially Mutable Lambda Captures
- P2044R2 : Member Templates for Local Classes
- P2096R1 : Generalized wording for partial specializations
- P2098R1 : Proposing std::is_specialization_of
- P2138R1 : Rules of Design<=>Wording engagement
- P2146R0 : Modern std::byte stream IO for C++
- P2149R0 : Remove system_executor
- P2150R0 : Down with typename in the library!
- P2155R0 : Policy property for describing adjacency
- P2156R0 : Allow Duplicate Attributes
- 次
N4858 : Disposition of Comments: SC22 5415, ISO/IEC CD 14882
C++20 CD (committee draft)の投票時に各国委員会およびそのメンバーから寄せられたコメントとその対応および理由の総覧です。
N4859/N4860/N4861
N4860/N4861のN4849との差分を記したEditors' Report。新たに採択された提案文書の一覧、解決されたIssueの一覧、Github上での軽微な修正コミットの一覧、などが載っています。
C++20のDIS (draft international standard)。この後FDIS (final draft international standard)を経てIS (international standard)へと至ります。
残念ながら委員会のメンバーしか見られないようです・・・
C++23のWD (working draft)第一弾。でもC++23向けに導入されたものはないはず。
N4860との差異は、表紙とヘッダ、フッダ、C++17規格とのクロスリファレンスの有無(無い)だけのようで、内容としてはDIS(N4860)と同一とのこと。C++17(N4659)も最終的に公開されているのはDIS相当のWDなので、これがC++20規格として参照されることになりそうです。
P0533R6 : constexpr for <cmath> and <cstdlib>
<cmath>と<cstdlib>の一部の関数をconstexpr対応する提案。
<cmath>からは、logb()、modf()、scalbn()、abs()/fabs()、ceil(),floor()等丸め系関数、fmod()、copysign(), nextafter()、fmax()/fmin()/fdim()、fma()、fpclassify(),isunordered()等数値分類・数値比較系関数、等が対象です。
<cstdlib>はなぜかそっちに含まれている数学関数(abs()とかdiv())だけが対象です。
筆者は、<cmath>の関数群は全てconstexpr指定できるはずだけど、コンパイラ/標準ライブラリベンダーの過度な負担とならない一部だけをconstexpr対応させる、と述べています。その一部には、sin(),cos()等の数学関数は含まれません・・・
また、これらの関数はerrnoや丸めモードなどグローバルフラグに依存し、またそれらを更新します。errnoをセットすべき時(定義域エラーやゼロ割)は単にコンパイルエラーを発生させ、グローバルフラグの状態はコンパイル時には変更しない、と言うようにすれば良いのですがC++17以前ではそれは少し難しい実装を要求していました。
しかし、C++20にてstd::is_constant_evaluated()が導入されたことでこの問題は解決されるため、単純な実装によって多くの<cmath>関数を追加でconstexpr対応させられるようになりました。
丸めモードに関しては色々議論があるようで、この提案では丸めモードへの依存が強い(変更することで精度が1%以上変化しうる)関数を除外しています。
P0870R2 : A proposal for a type trait to detect narrowing conversions
型Tが別の型Uへ縮小変換(narrowing conversion)によって変換可能かを調べるメタ関数is_narrowing_convertible<T, U>を追加する提案。
これは例えば、std::optionalやstd::variantのようなラッパー型において、縮小変換が起こる場合に変換や構築を禁止する制約をかけるのに利用できます。
意図しない縮小変換の発生は実行時において浮動小数点数の精度低下などの発見しづらいバグにつながります。縮小変換(発生の可能性)をコンパイル時に検出し禁止しておくことで、C++の型システムをユーザーの手によって多少ロバストにして運用することができます。
提案されている宣言。
namespace std { template <class From, class To> struct is_narrowing_convertible; template <class From, class To> inline constexpr bool is_narrowing_convertible_v = is_narrowing_convertible<From, To>::value; }
これは例えば、次のように実装できます(提案文書より)。
// そもそも変換不可能な型のペアのためのプライマリテンプレート template<class From, class To> inline constexpr bool is_narrowing_convertible_v = false; // 縮小変換を検出する // To t[] = { std::declval<From>() };のような式がエラーとなるかによって縮小変換が起こるかを調べている template<class T, class U> concept construct_without_narrowing = requires (U&& x) { { std::type_identity_t<T[]>{std::forward<U>(x)} } -> std::same_as<T[1]>; }; // 変換可能な型のペアはこちらを利用 template<class From, class To> requires std::is_convertible_v<From, To> inline constexpr bool is_narrowing_convertible_v<From, To> = !construct_without_narrowing<To, From>;
P1255R6 : A view of 0 or 1 elements: views::maybe
std::optionalやポインタ等のmaybeモナドな対象を、その状態によって要素数0か1のシーケンスに変換するRangeアダプタviews::maybeの提案。
例えば、std::optionalのシーケンスを無効値を持つかによってフィルタする処理をわざわざ書く必要がなくなったり、std::optionalの状態をチェックして中身を取り出して・・・といったお決まりのコードを隠蔽することができます。
{
auto&& opt = possible_value(); // optionalを返す関数
if (opt) {
// 数十行の処理が挟まっていたとすると・・・
use(*opt); // ここでのデリファレンスは有効かがすぐに分からなくなりがち
}
}
// ↑これが↓こう書ける
for (auto&& opt : views::maybe(possible_value())) {
// 数十行の処理が挟まっていたとしても・・・
use(opt); // すでにデリファレンスされており、有効値が得られている
}
views::maybeを通した場合、possible_value()が無効値を返した場合はループが実行されません(シーケンスが空なので)。
std::vector<int> v{2, 3, 4, 5, 6, 7, 8, 9, 1}; auto test = [](int i) -> std::optional<int> { switch (i) { case 1: case 3: case 7: case 9: return i; default: return {}; } }; auto&& r = v | ranges::views::transform(test) | ranges::views::filter([](auto x){return bool(x);}) | ranges::views::transform([](auto x){return *x;}) | ranges::views::transform( [](int i) { std::cout << i; return i; } ); // ↑これが↓こう書ける auto&& r = v | ranges::views::transform(test) | ranges::views::transform(views::maybe) //0か1要素のシーケンスのシーケンスになる | ranges::views::join //シーケンスのシーケンスを1つのシーケンスに平滑化する | ranges::views::transform( [](int i) { std::cout << i; return i; } );
P1315R5 : secure_clear
特定のメモリ領域の値を確実に消去するための関数secure_clear()の提案。
パスワード等のセキュアなデータを扱う場合、不用になったらすぐにその内容を消し去り、コアダンプ等によってキャプチャ可能な時間を少しでも短くする必要があります。このことは、近年の脆弱性(MeltdownやSpectre等)の影響によって重要度が増しています。
しかし、単純にメモリ領域をクリアするだけの処理はその領域がその後使用されない事からコンパイラの最適化によって削除される可能性があります。
void f() { constexpr std::size_t size = 100; char password[size]; // セキュアなデータの取得 getPasswordFromUser(password, size); // 取得したデータの仕様 usePassword(password, size); // 取得したデータの削除 std::memset(password, 0, size); }
この様な問題(すなわちコンパイラ最適化)を回避するのにはいくつもの方法がありますが、それらの方法は非自明であったり、移植性が無く容易に利用できるものではなかったりします。
そのような機能を標準によって提供しポータブルかつ容易に利用できるようにするために、secure_clear()関数を提案しています。
namespace std { template <class T> requires is_trivially_copyable_v<T> and (not is_pointer_v<T>) void secure_clear(T & object) noexcept; }
効果は上に示した通り、受け取った参照先のオブジェクトの占めるメモリ領域をゼロクリアします。
なお、この提案は同時にC標準に対しても行われているようです(N2505)。
void secure_clear(void * data, size_t size);
こちらはポインタとゼロクリアする領域サイズを取ります。
C++からはstd::secure_clear()としてこの2つのオーバーロードが利用可能になります(採択されれば)。
P1641R3 : Freestanding Library: Rewording the Status Quo
フリースタンディング処理系に要求されるライブラリ機能についての文言を変更する提案。
現在はライブラリヘッダ毎にフリースタンディングで要求されるかを規定していますが、ヘッダの一部分の機能および対応する機能テストマクロを個別にフリースタンディング指定することができるように文言を追加・変更しようというもの。主に<cstdlib>の文言を改善するのが目的っぽい?
P1654R1 : ABI breakage - summary of initial comments
ABIの破損問題について、委員会メンバからのコメントをまとめた報告書。
C++標準がABI破損を伴う変更を受け入れるのか、どのように受け入れるのかについて、次の4つのケースが考えられます。
- ABIを絶対に壊さない
- 実行パフォーマンスが低下するが、もっとも安定している。何も懸念がなければこれを選択すべき
- ケースバイケース(例 :
std::stringのSSO)- 以前に行ったことがあるが、ユーザーはそれが行われることを予測できない
- 特定のリリースを境界としてABI破壊を許可する(例えば12年毎など)
- 試したことはない、適切な期間とは何か?
- 任意のタイミングで自由にABIを破壊する
- 一番素早く動けて実行パフォーマンスを高められるが、安定性がもっとも低い
どれを選ぶのかを慎重に検討するために委員会メンバからのコメントを募集し、過去に行われたABI破壊や、ABI破壊を理由に採択されなかった提案について、また将来必要になるかもしれないABI破壊などについてまとめられています。
P1949R3 : C++ Identifier Syntax using Unicode Standard Annex 31
識別子(identifier)の構文において、不可視のゼロ幅文字や制御文字の使用を禁止する提案。
現在C++では識別子に使用可能なUnicode文字列をコードポイントの範囲として規定していますが、その中にはゼロ幅文字など人間の目で見て区別できない文字が含まれてしまっており、万が一使用されればバグの元となりえます。そのため、それらの使用を禁止しそのような文字列が使用されていた場合はコンパイルエラーにすることを提案しています。
Unicode Standard Annex 31というのはどうやら、プログラミング言語において汎用的に識別子として使用可能な文字列および文字列の形式を定めたものです。C++11時点ではこれは安定しておらず使用されませんでしたが、現在は安定しており後々のUnicodeの規格で破壊的な変更が行われないことが保証されるようになっているようです。
そのため、それを参照して識別子の構文を規定することで識別子として適切な文字だけが使用できるように標準を変更します。
Unicode Standard Annex 31で規定されている識別子の構文規則(EBNF)は次のようになります。
<Identifier> := <Start> <Continue>* (<Medial> <Continue>+)*
ここで、<Start>はXID_Startという特定の文字(コードポイント)の集合、<Continue>はXID_Continueという特定の文字の集合、<Medial>は<Continue>の文字の間に現われることができる文字の集合です。
C++では、<Start>に_(U+005F、アンダーバー)を追加し<Medial>は空になります(<Continue>はそのまま)。上記の文法に照らせば、次のようになります。
<Identifier> := <Start> <Continue>* <Start> := XID_Start + U+005F <Continue> := <Start> + XID_Continue
XID_Startにどんな文字が含まれているのか及びXID_Continueにどんな文字が含まれているのかは正直良く分からないくらい大量の文字がありますが、多分制御文字やゼロ幅文字はないはずで、絵文字も含まれていないようです。
また、採択されたとしたら、これらのことは欠陥報告としてC++20以前のバージョンに遡って適用されることになりそうです。
- 見た目で区別できない変数 - ++C++; // 未確認飛行 C
- UAX #31: Unicode Identifier and Pattern Syntax - unicode.org
- P1949 進行状況
P2011R1 : A pipeline-rewrite operator
x |> f(y);をf(x, y);と評価する新しい演算子|>の提案。
この演算子はオーバーロード可能ではなく、右辺の値を左辺の関数呼び出しの第一引数に渡すように式全体を書き換えるだけです。
Unified Function Call Syntax(UFCS)に近いものに見えますが、この演算子による書き換えは常に非メンバ関数を呼び出します。
x->f(y); // メンバ関数f()を呼び出す x.f(y); // メンバ関数f()を呼び出す x |> f(y); // 非メンバ関数f()を呼び出す
一見すると何の意味があるのか分からない演算子ですが、Rangeのパイプライン演算子|にまつわる以下の様な諸問題を解決するためのものです。
- パイプラインスタイルを使用するためのサポートコードが複雑かつ大量に必要になる
- コンパイラの最適化がそれらのコードを完全に取り除けない場合、オーバーヘッドが発生しうる
- それらサポートコードによるコンパイル時間の増大
- 一部のアルゴリズムをパイプライン演算子にアダプトできない場合がある
Rangeのパイプライン演算子がやっていることは要するに、左辺の式の結果オブジェクトを右辺の関数の第一引数に渡すようなもので、それによって関数呼び出しのネストを分解しています。
#include <iostream> #include <vector> #include <ranges> int main() { std::vector v = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; // 偶数を取り出して、2倍して、逆順にする // 適用順と逆順になるうえ、やることが多くなるとネストしまくり可読性がしぬ auto&& range = std::views::reverse( std::views::transform( std::views::filter(v, [](auto n){ return n % 2 == 0;}), [](auto n) { return n * 2;} ) ); for (auto e : range) { std::cout << e << std::endl; } } //↑これを↓のように書ける int main() { std::vector v = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; // パイプラインスタイル // 適用順と同じ順番で縦に並べられるので見やすい! for (auto e : v | std::views::filter([](auto n){ return n % 2 == 0;}) | std::views::transform([](auto n) { return n * 2;}) | std::views::reverse) { std::cout << e << std::endl; } }
[Wandbox]三へ( へ՞ਊ ՞)へ ハッハッ
[Wandbox]三へ( へ՞ਊ ՞)へ ハッハッ
ここで、2つのスタイルの例に現れているfilterやtransform等の関数はそれぞれ異なるオーバーロードが使用されています(例えば、filter(Rng&&, Pred&&)とfilter(Pred&&))。|演算子はあくまで演算子オーバーロードでありその呼び出しよりも引数に与えられた式の評価が先になるので、パイプラインスタイルの時に|演算子の右辺に来る関数(filter(Pred&&))は渡された関数オブジェクトを|に引き渡す為のラッパを生成するだけの処理になります。一方、第一引数にrangeオブジェクトが直接渡っている最初の例(filter(Rng&&, Pred&&))では受け取った処理の適用準備の済んだrange viewオブジェクトを返します。
どちらが読みやすいかを考えるとパイプラインスタイルの威力は圧倒的ですが、この裏側では大量の黒魔術が発動しています・・・
このような|の行なっていることを式の書き換えによって行う|>演算子を言語サポートすることで、パイプライン演算子を使用するためのそのような黒魔術コードを削減することができ、それに伴う諸問題の解決を図ることができます。
|>演算子でも|と同様に書けます。
#include <iostream> #include <vector> #include <ranges> int main() { std::vector v = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; for (auto e : v |> std::views::filter([](auto n){ return n % 2 == 0;}) |> std::views::transform([](auto n) { return n * 2;}) |> std::views::reverse) { std::cout << e << std::endl; } }
|>演算子の場合はこれを一番最初の関数呼び出しネストコードに書き換えることによって|演算子と同じことを達成します。これによって演算子オーバーロードもそれに対応するためにfilter等に不要なオーバーロードを追加する必要もなくなります。
また、|>の両辺は書き換え前に評価されません。つまり、他の演算子とは少し振る舞いが異なります。オーバーロード不可能とされているのはこの性質によります。
P2013R1 : Freestanding Language: Optional ::operator new
フリースタンディング処理系においては、オーバーロード可能なグローバル::operator newを必須ではなくオプションにしようという提案。
フリーストア(ヒープ)を持たないかその使用が著しいオーバーヘッドとなる環境では、意図しない::operator newが使用された場合にコンパイルエラー(リンクエラー)となってほしい場合があります。また、OSのカーネルの動作環境のように、メモリ割り当てを正しく行う方法が無い環境でも同様です。このような環境ではすでに::operator newの実装を提供できておらず、結果としてそれらの環境のC++ユーザーは::operator newを使わないか、(使うために)独自実装をするかの2択を迫られているのが現状です。そのため、あえて::operator newを定義しないという選択肢を標準化し、その場合の振る舞いを規定する必要がある、というのが要旨です。
提案では、オーバーロード可能なグローバル::operator newの提供を実装定義とし、提供するならば全てのオーバーロードを提供する必要があるが、提供しない場合は全てのオーバーロードを提供しない、という規定を追加します。結果として、::operator newが提供されない場合、プログラム中でのそれらの使用はill-formedであり、おそらくリンカエラーを引き起こします。
ちなみにそのような場合には、<coroutine>ヘッダはグローバル::operator newに依存しているので存在そのものがill-formedになります(#include or importしなければok)。
なお、::operator deleteは仮想デストラクタにおいて参照されるのでそのままであり、constexpr newは使用可能となるように文言が調整されています。
記載されているEWG等での投票結果を見るに受け入れられそうな雰囲気です。
P2034R1 : Partially Mutable Lambda Captures
ラムダ式の全体をmutableとするのではなく、一部のキャプチャだけをmutable指定できるようにする提案。
パフォーマンスが求められるコールバック関数オブジェクトではその内部に個別に利用するローカルメモリを持つことがあります。また、mutex等の参照をメンバに持つこともあるでしょう。それらは外部から観測不可能な内部状態であり、そのオブジェクトは意味論的にはimmutableです。
struct MyRealtimeHandler { private: const Callback callback_; const State state_; mutable Buffer accumulator_; public: void operator()(Timestamp t) const { callback_(state_, accumulator_, t); } }; struct MyThreadedAnalyzer { private: const State& state_; std::mutex& mtx_; public: void operator()(Slice slice) const { std::lock_guard<std::mutex> lock{mtx_}; analyze(state_, slice); } };
例えばこの様な典型的な型はラムダ式を使えば定義を必要とせずに簡単に書くことができますが、現在はこの様に部分的にmutable/非constなメンバを持つようなラムダ式を書くことが出来ません。全部constが全部mutableかの二者択一です。
提案では、次のようにキャプチャを個別にmutable指定できるようにします。
auto a = [mutable x, y]() {}; // ↑は↓と等価 struct A { mutable X x; // Xが参照型(xが参照キャプチャ)なら単に非const参照になる const Y y; void operator()() const {} } a;
この様に、その物理的な状態を変更したとしてもそのオブジェクトの論理的(意味論的)な状態を変更しないような不変オブジェクト(に対する操作)の事をlogical constと呼びます。
さらに、std::any_invocableというCV修飾やnoexceptを指定できるstd::functionが議論されており、それを踏まえるとlogical constなラムダ式はより必要とされます。
また、この提案では更なる議論を前提としていて、他にも以下の様な書き方を可能にすることが提案されています。
// constキャプチャとmutable呼び出し auto b = [x, const y]() mutable {}; // 参照のconstキャプチャ auto b = [&x, const &y]() {}; // const呼び出し(コンパイルエラーにならないようにする) auto c = [x]() const {}; // constキャプチャとconst呼び出し auto c = [const x]() const {}; // mutableキャプチャとmutable呼び出し auto c = [mutable x]() mutable {};
- What do I do if I want a const member function to make an “invisible” change to a data member? - isocpp
- const, mutableキーワードとスレッド安全性 - yohhoyの日記
- P2034 進行状況
P2044R2 : Member Templates for Local Classes
ローカルクラスでメンバテンプレートを使用できるようにする提案。
ローカルクラスとは関数の中で定義されたクラスで、関数テンプレートと利用するとインターフェースの自動実装を行えたりとなかなか便利なやつです。ローカルクラスのスコープはその関数の中に閉じられ、関数外部からクラス名を参照することはできないため名前が衝突したりせず、インターフェースクラスを継承して自動実装する場合はアップキャストされるのを完全に防止できます。なお、ローカルクラスのメンバは普通に外から参照できます。
しかし、ローカルクラスでは囲む関数テンプレートのテンプレートパラメータなど囲む関数からアクセスできるものは全てアクセスできますが、メンバテンプレートを持つことができないなどいくつかの制限があります(ローカルクラス自体がテンプレートになることはできます)。
ローカルクラスがメンバテンプレートを持つことができるようになると、あるインターフェースを別のインターフェースへ変換するアダプタの自動生成などをローカルクラスで書くことができるようになります。
// operator()をcall()に変換するアダプタを生成する template<typename Callable> auto callable_to_call(Callable&& f) { // ローカルクラス struct call_impl { Callable m_f; // 今はこれができない・・・ template<typename... Args> auto call(Args&&... args) { return m_f(std::forward<Args>(args)...); } }; return call_impl{std::forward<Callable>(f)}; }
実装クラスを関数外部に持っておいてもいいのですが、クラス名が漏洩しないというのと、見た目的にも気持ち的にもコードがコンパクトになるのが個人的お好みポイントです。
MSVCの実装者はこの変更は問題ないと言っているそうですが、Clangは熱心にテンプレートの実体化を行う結果思わぬコンパイルエラーが起こる可能性があるとのことです。しかし、すでにジェネリックラムダが限定的とはいえ同じことが可能になっているのであまり壁は高くなさそうです。
P2096R1 : Generalized wording for partial specializations
変数テンプレートの部分特殊化を明確に規定するように文言を変更する提案。
現在の書き方だと変数テンプレートの部分特殊化についてが不透明なので、クラステンプレートの部分特殊化に関する文言を一般化して変数テンプレートの部分特殊化を規定するように文言を調整しています。これが通ったとしても多くのユーザーにとっては関係ない話です。パッと見では、クラステンプレートの部分特殊化やプライマリクラステンプレート、などと書かれていたところからクラステンプレートというワードが消されています。仮に採択された場合はこの辺を読むときは注意しないと分かりづらいかもしれません。
P2098R1 : Proposing std::is_specialization_of
std::complex<T>とstd::complex<double>のように、ある型Tが別の型Pの特殊化となっているかを調べるメタ関数is_specialization_of<T, P>の提案。
例えばテンプレートの文脈で、std::complex<T>やstd::optional<T>、std::vector<T>など、その要素型はともかくとして型がその特殊化であるかを知りたい!という場合はよくあります。幸いこれを判定するメタ関数を書くのは難しくないのでテンプレート好きな人は多分1度は書いたことがあるでしょう。そのように、よく利用されるものであるので標準に追加しようという提案です。ただし、あるテンプレート毎に個別にそのようなメタ関数を追加するわけにはいかないので、より一般化した任意の型のペアの間でそれを判定するものを追加します。
template<class T, template<class...> Primary> struct is_specialization_of; template<class T, template<class...> Primary> inline constexpr bool is_specialization_of_v = is_specialization_of<T,Primary>::value;
例えば次の用に使います。
// そのまま使う static_assert(std::is_specialization_of_v<T, std::optional>); // 特定のテンプレート用に特殊化 template< class T > inline constexpr bool is_complex_v = is_specialization_of_v<T, std::complex>;
ただ、std::array<T, N>のように非型テンプレートパラメータを取るものは判定できません。それは諦めているようです。また、これはクラスの継承関係を判定するものではありません。
P2138R1 : Rules of Design<=>Wording engagement
(タイトルの<=>は宇宙船演算子ではありません)
CWGとEWGの間で使用されているwording reviewに関するルールの修正と、それをLWGとLEWGの間でも使用するようにする提案。
C++標準会員会の作業プロセスの改善に関するお話なので、完全にユーザーには関係ありません。CWGとかEWGとかは次の図参照。
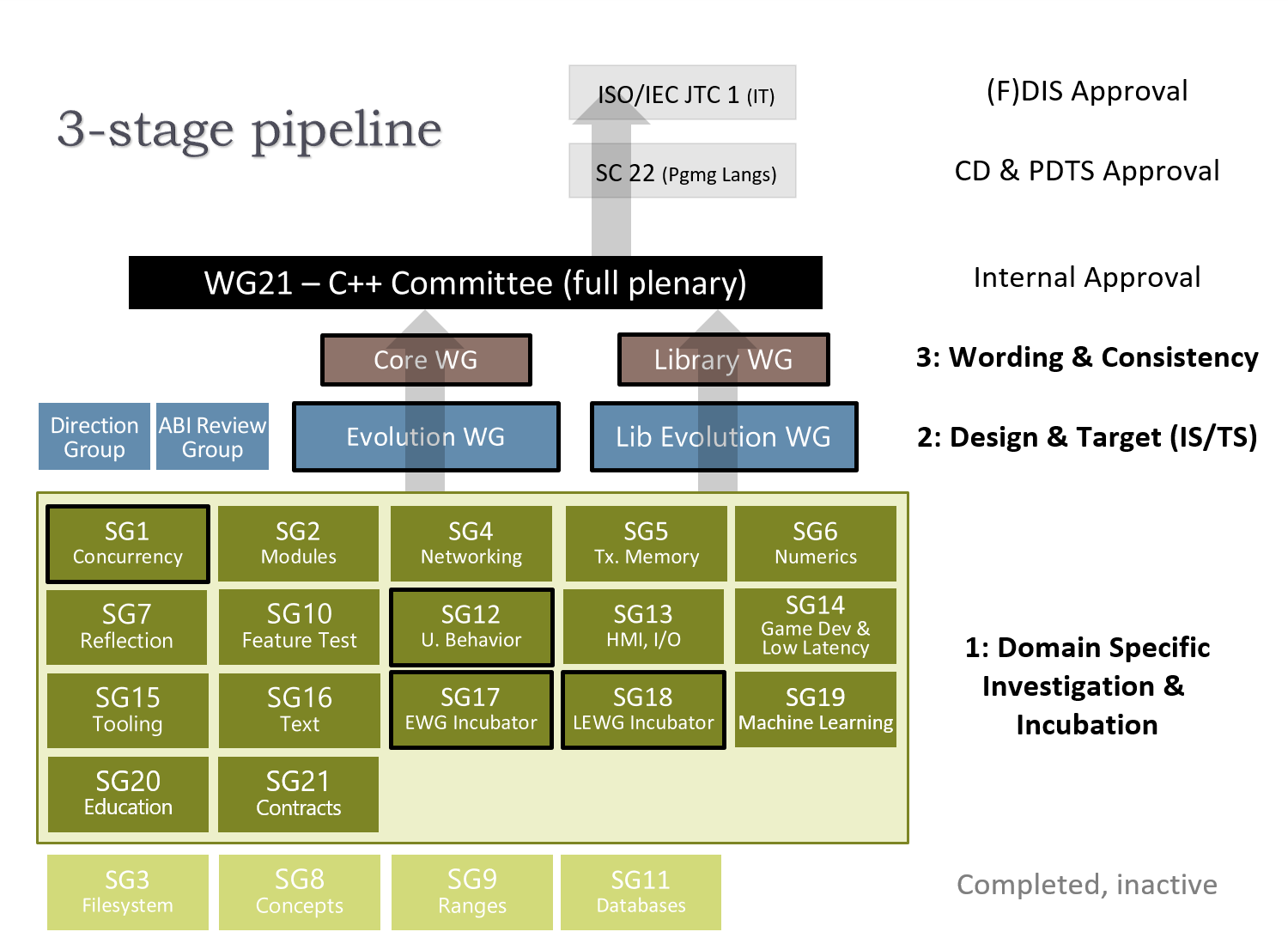
コア言語の提案はEWG(Evolution Working Group)で基礎設計が詰められてからCWG(Core Working Group)へ送られ、CWGでは標準としての文言の確認と調整を行います。その際、EWGである程度設計に基づく文言が整っていることが要求されますが、設計を文言が表現しきれていなかったり、議論していない文言が含まれていたり、とそうなっていない事があったようです。
そのため、EWGとCWGの間ではそう言う事が無いようにするためのルールが設けられていました。とはいえ、そのルールは文書化されたものではなかったためか、CWGに送られた段階でしっかりと文言が整っていない事がまだあるようです。
EWGが設計とそれを表現する文言を決定しCWGは文言を確認するだけ、という役割分担を明確にしCWGの時間を無駄にしないようにするためにルールを変更し、同じことをLWG(Libraly Working Group)とLEWG(Libraly Evolution Working Group)の間でも行うようにする。というのが提案の要旨です。
P2146R0 : Modern std::byte stream IO for C++
std::byteによるバイナリシーケンスのI/Oのための新ライブラリ、std::ioの提案。
C++20現在、バイナリファイルのIOをやろうとするとiostreamを使用することになりますが、iostreamもベースにあるCのIO関数もテキストストリームへの入出力前提なものをバイナリモードという特殊な状態にしたうえでバイナリIOに使用することになるので、使いづらく、また非効率です。
#include <fstream> int my_value = 42; { std::ofstream stream{"test.bin", std::ios_base::out | std::ios_base::binary}; stream.write(reinterpret_cast<const char*>(&my_value), sizeof(my_value)); } int read_value; { std::ifstream stream{"test.bin", std::ios_base::in | std::ios_base::binary}; stream.read(reinterpret_cast<char*>(&read_value), sizeof(read_value)); } assert(read_value == my_value)
これには以下の欠点があります。
std::byte非対応のため、reinterpret_cast<const char*>が必要- バイト数を明示的に指定しなければならない
- バイトの読み書きにエンディアンを考慮してくれない(するようにできない)
std::char_traitsが使われるがバイナリIOには不要、std::ios::pos_typeは多くのIO操作に必要だが使いづらい。- バイナリIOに必要なのは常に
std::ios_base::binary、オープンモード指定は不用 - ストリームオブジェクトはテキスト形式フラグをいくつも持っているが、バイナリIOには不要。メモリの無駄
- デフォルトのストリームは例外を投げない。これはストリーム状態を調べて例外を発生させるラッパーコードを追加する手間の元
- メモリ内で完結するIOのために
std::stringを使用するstd::stringstreamが用意されているが、無駄なコピーが発生するなど使いづらい。バイナリデータはほとんどの場合std::vector<std::byte>が適当であり、spanで参照すれば十分 - 現行のiostreamには、バイナリIOとシリアライズのためのカスタマイゼーションポイントが無い
これらの欠点をすべて解決したバイナリIOのための新ライブラリの導入を目指すのがこの提案です。
生バイト列のIOサンプル
#include <io> #include <iostream> int main() { // 書き込むバイト列 std::array<std::byte, 4> initial_bytes{ std::byte{1}, std::byte{2}, std::byte{3}, std::byte{4} }; { // 書き込み用にファイルオープン std::io::output_file_stream stream{"test.bin"}; // 書き込み std::io::write_raw(initial_bytes, stream); } // RAIIによってストリームが閉じられる // 読み込み用バイト列 std::array<std::byte, 4> read_bytes; { // 読み込みのためにファイルオープン std::io::input_file_stream stream{"test.bin"}; // 読み込み std::io::read_raw(read_bytes, stream); } // RAIIによってストリームが閉じられる // 読み込んだバイト列の比較 if (read_bytes == initial_bytes) { std::cout << "Bytes match.\n"; } else { std::cout << "Bytes don't match.\n"; } }
カスタマイゼーションポイントによる任意クラスのカスタムシリアライズとエンディアン指定のサンプル。
#include <io> #include <iostream> struct MyType { int a; float b; void read(std::io::input_stream auto& stream) { // ビッグエンディアンでメンバ変数にストリームから値を読み出す std::io::default_context context{stream, std::endian::big}; std::io::read(a, context); std::io::read(b, context); } void write(std::io::output_stream auto& stream) const { // ビッグエンディアンでメンバ変数の値をストリームに書き出す std::io::default_context context{stream, std::endian::big}; std::io::write(a, context); std::io::write(b, context); } }; int main() { MyType my_object{1, 2.0f}; std::io::output_memory_stream stream; // std::io::writeはカスタマイゼーションポイントオブジェクト // メンバ関数か同じ名前空間の非メンバ関数のwrite()を探して呼び出す // 対になるstd::io::readも同様 std::io::write(my_object, stream); // ストリームのバッファを取得し、内容をバイト列として書き出す const auto& buffer = stream.get_buffer(); for (auto byte : buffer) { std::cout << std::to_integer<int>(byte) << ' '; } std::cout << '\n' }
他にも、spanやメモリのためのI/Oストリームが用意されていたり(これらはconstexpr対応!)、エンディアンを途中で切り替え可能だったり、整数型の特殊なフォーマット(LEB128など)をサポート可能だったり、ISO 60559以外もサポート可能な浮動小数点数バイナリフォーマット変換も考慮されていたり(ドロップされそうですが)、コンセプトベースだったりとイケてる雰囲気のライブラリです。
筆者の方が並行してリファレンス実装を作っています。なかなか本気のようです。
P2149R0 : Remove system_executor
Networking TSからsystem_executorとsystem_contextを削除する提案。
system_context::get_executor()はデフォルト構築したsystem_executorを返して、そのメンバ関数であるsystem_executor::context()は静的記憶域期間に配置された(つまりグローバル変数の)system_contextオブジェクトへの参照を返します(これは必ずしもMeyer’s singletonではないかもしれない、つまり本物のグローバル変数かもしれない)。
しかも、そのようなグローバルなsystem_contextオブジェクトはmutableです。
グローバルなオブジェクトであるがゆえに、それを利用するユーザーのコンポーネントのRAIIとは無縁の所で動いています。プログラム、あるいはコンポーネントの終了時にそのグローバルsystem_contextに何かしなければいけないかどうかは、system_contextとやり取りをしたコンポーネントが自分も含めて存在しているかによって決まります。また、この様なグローバルなオブジェクトにはその構築と破棄の順序の不定性など様々な問題があります。
Networking TSの仕様ではsystem_contextを直接使用するのはsystem_executorだけで、system_executorはassociated_executor(_t)の仕様においてフォールバックExecutorとして使用されています。
従って、グローバルな状態に依存しないような代わりのexecutorを用意して、現在のsystem_executorとsystem_contextを削除しよう、という事のようです(良く分かりません・・・)
本質的には、グローバル変数として複雑な状態を持ってしまっていることが問題のようです。
P2150R0 : Down with typename in the library!
標準ライブラリのパートから不用なtypenameを消し去る提案。
C++20からいくつかの場所でtypenameが不用になったのに伴って(P0634R3 : Down with typename!)、標準ライブラリの規定部分からも取り除こうという話です。
どこで不要になるかはこのページを参照。
P2155R0 : Policy property for describing adjacency
進行中のExecutor(簡単に言えばスレッドプールサポートライブラリ)に関するもので、NUMAのようなアーキテクチャ向けに、スレッドとそこで使用するメモリを同じノード内で確保しバインドするように指示するポリシーを追加する提案。
NUMAでは1つのプロセッサとそこに接続されたローカルメモリを1ノードとして、複数のノードで構成されることになりますが、そのシステム上での論理スレッド(OS上プロセスのスレッド)はOSによって任意のノードの物理スレッド(CPUコア)に割り当てられる可能性があり、また、そのスレッド内で確保し使用しているメモリはそのスレッドを実行している物理スレッドの属するノードとは別のノードに属するメモリを使用している可能性があります。
OSのスケジューリングによってこれはほとんど予測不可能となりますが、ノードを超えたスレッドスケジュールやメモリアクセスは当然ノード内で行われるよりも高コストになり、全体のパフォーマンスに影響を与えます。この様な実行スレッドに対する割り当てメモリの位置の事をメモリアフィニティ(memory afinity)、あるいは単にアフィニティと呼びます。
このようなことが起こりえる場合にもパフォーマンスを向上させるための1つの方法は、ある論理スレッドを物理スレッドとそのローカルメモリにバインドしスケジューリングやメモリ割り当てをあるノード内で完結するように強制してしまう事です。
NUMAの様なシステムにおいてC++開発者が現在および将来のアーキテクチャに渡って最高のパフォーマンスを得るためには、この様なスレッドとメモリの配置の制御をC++標準機能としてネイティブサポートする必要がある、というのが提案の要旨です。
次のようなadjacencyプロパティグループを定義しておき、これを実行ポリシーに与えることで、Excecutor実装に対してアフィニティ制御に関するヒントを提供できるようにします。
namespace std { namespace experimental { namespace execution { struct adjacency_t { struct no_implication_t; struct constructive_t; struct destructive_t; // デフォルト、普通にアフィニティ制御をしてほしい constexpr no_implication_t no_implication; // 以下二つは、隣接するワークアイテム(スレッド?)を離した上でアフィニティ制御を行うかを指定する // キャッシュラインの配置までコントロールするか否か? // 実行する処理はconstructive interferenceの恩恵を受けうる // すなわち、参照局所性が重要 constexpr constructive_t constructive; // 実行する処理はdestructive interferenceの恩恵を受けうる // すなわち、false sharingが問題になる constexpr destructive_t destructive; }; constexpr adjacency_t adjacency; } // execution } // experimental } // std
このように、アフィニティ制御をどのように行うかを指定するポリシーを渡すことで実装へのヒントとし、実装の抽象化度を維持し移植性を持たせたまま必要なら高パフォーマンスな実装を選択できるようになります。
提案文書よりサンプルコード(Executor分からないから読めない
// bulk algorithmの各インデックスについて、そこで使用されるメモリ領域用のポインタ列 std::vector<std::unique_ptr<float>> data{}; data.reserve(SIZE); // NUMA対応Executorの作成 numa_executor numaExec; // bulk algorithmの各実行に与えるインデックス auto indexRng = ranges::iota_view{SIZE}; // std::par実行ポリシーに加えてadjacency.constructiveプロパティを要求する新しい実行ポリシーを作成 // 実装に対して、実行する処理はconstructive interferenceの恩恵を受けうることをヒントとして与える // adjacencyプロパティはここで指定する auto adjacencyPar = std::execution::require(std::par, adjacency.constructive); // bulk algorithmの各実行毎に初期化を行うCallableオブジェクト auto initialize = [=](size_t idx, std::vector<unique_ptr<float>> &value) { value[idx] = std::make_new<float>(0.0f); }; // 実行する処理内容 auto compute = [=](size_t idx, std::vector<unique_ptr<float>> &value) { do_something(value[idx]); }; // 入力となるdataを受けて、NUMA対応Executorを使用してスケジューリングし、 // indexed_forによって、まず初期化を行いその後で計算を行うsenderを作成 // 実行ポリシーはここで指定する auto sender = std::execution::just(data) | std::execution::via(numaExec) | std::execution::indexed_for(indexRng, adjacencyPar, initialize) | std::execution::indexed_for(indexRng, adjacencyPar, compute); // senderをExecutorへ送り、結果を待機 std::execution::sync_wait(sender, std::execution::sink_receiver{});
- NUMAについて - so tired
- P0443R13 : A Unified Executors Proposal for C++
- P1897R2 : Towards C++23 executors: A proposal for an initial set of algorithms
- P2155 進行状況
P2156R0 : Allow Duplicate Attributes
属性指定時に同じ属性を重複して指定しても良いようにする提案。
現在の規定では、一つの属性指定[[]]の中で同じ属性が複数回現れることは出来ません。しかし、属性指定を複数に分割すれば同じ属性が何回重複してもokです。
// ng [[noreturn, carries_dependency, deprecated, noreturn]] void f(); // ok [[noreturn]] [[carries_dependency]] [[deprecated]] [[noreturn]] void g();
この挙動は一貫していないので、属性指定の重複を認める(上記NGの例f()を適格にする)方向に変更すべし、という提案です。
EWGの見解としては、属性指定を分ければ重複可能なのはマクロによって属性を条件付きで追加していくことをサポートするためのもので、一つの属性指定のなかでそれを行う事はレアケースなのでこの制限を解除する必要はない、という事。
しかし、これをそのままにしておくと、重複不可能な属性を標準に追加するたびにその旨を一々記述しておく必要があり、逆に重複可能な属性に対しては重複した時の振る舞いを記述しておく必要が生じます。これは明らかに標準を太らせ望ましくないので重複可能をデフォルトにするべき、というのが筆者の主張です。また、これは欠陥として過去のバージョンにさかのぼって適用されるのが望ましいとも述べています。