<charconv>ヘッダはC++17から導入されたヘッダで、ロケール非依存、動的確保なし、例外なげない、などを謳ういいことづくめで高速な文字列⇄数値変換を謳う関数が提供されています。現在フルで実装しているのはMSVCだけですが、実際速いってどのくらいなの?既存の手段と比べてどうなの??という辺りが気になったので調べてみた次第です。
計測環境
一応電源プランを高パフォーマンスにして、VS以外を終了させた状態で計測。ビルドは/std:c++latestを追加したリリースモードで行っています。
std::to_chars()
std::to_chars()は数値を文字列へ変換する関数です。出力はcharの文字列限定で、戻り値を調べることでエラーの有無と文字列長が分かります。
これとの比較対象は以下のものです。これらは同じく数値→文字列への変換を行います。
std::to_string()std::stringstreamsnprintf()
測定方法
100万件のランダムな数値を用意してそれを1つづつ全件変換にかけ、それにかかる時間を計測します。それを10回繰り返して各種統計量で見てみることにします。整数型(64bit整数型)と浮動小数点型(double)それぞれで実験を行います。
コードは以下のようになります。
#include <iostream> #include <charconv> #include <vector> #include <random> #include <chrono> #include <type_traits> #include <cassert> #include <thread> #include <numeric> #include <string> #include <sstream> template<typename NumericType> auto make_data(unsigned int N) -> std::vector<NumericType> { auto rng = []() { if constexpr (std::is_integral_v<NumericType>) { return std::uniform_int_distribution<NumericType>{}; } else if constexpr (std::is_floating_point_v<NumericType>) { return std::uniform_real_distribution<NumericType>{}; } else { static_assert([] { return false; }, "You have to specify a number type, right?"); } }(); std::mt19937_64 urbg{ std::random_device{}() }; std::vector<NumericType> vec; vec.reserve(N); for (auto i = 0u; i < N; ++i) { vec.emplace_back(rng(urbg)); } return vec; } template<typename Container> void report(Container&& container) { const auto first = std::begin(container); const auto last = std::end(container); const auto N = std::size(container); using value_type = typename std::iterator_traits<std::remove_const_t<decltype(first)>>::value_type; std::sort(first, last); const auto max = *(last - 1); const auto min = *first; std::cout << "min : " << min.count() << " [ms]" << std::endl; std::cout << "max : " << max.count() << " [ms]" << std::endl; const auto medpos = first + (N / 2); std::cout << "median : " << (*medpos).count() << " [ms]" << std::endl; const auto sum = std::accumulate(first, last, value_type{}); const auto ave = sum.count() / double(N); std::cout << "average : " << ave << " [ms]" << std::endl; const auto var = std::inner_product(first, last, first, 0ll, std::plus<>{}, [](auto& lhs, auto& rhs) {return lhs.count() * rhs.count(); }) / N - (ave * ave); std::cout << "stddev : " << std::sqrt(var) << "\n" << std::endl; } template<typename NumericType, typename F> void profiling(const char* target, F&& func) { using namespace std::chrono_literals; constexpr int trialN = 10; constexpr int sampleN = 1'000'000; std::chrono::milliseconds results[trialN]{}; for (int i = 0; i < trialN; ++i) { //データの準備 auto input = make_data<NumericType>(sampleN); //計測開始 auto start = std::chrono::steady_clock::now(); for (auto v : input) { func(v); } //計測終了 auto end = std::chrono::steady_clock::now(); results[i] = std::chrono::duration_cast<std::chrono::milliseconds>(end - start); std::this_thread::sleep_for(200ms); } std::cout << target << std::endl; report(results); } int main() { char buf[21]; auto first = std::begin(buf); auto last = std::end(buf); profiling<std::int64_t>("to_chars() int64", [first, last](auto v) { auto [ptr, ec] = std::to_chars(first, last, v); if (ec != std::errc{}) throw new std::exception{}; }); }
整数(std::int64_t)
単位は全てms
| 方法 | 最小値 | 最大値 | 中央値 | 平均値 | 標準偏差 |
|---|---|---|---|---|---|
std::to_chars() |
27 | 36 | 28 | 29.2 | 2.71293 |
std::to_string() |
79 | 98 | 81 | 82.4 | 5.31413 |
std::stringstream |
525 | 602 | 533 | 543.9 | 22.8427 |
snprintf() |
236 | 246 | 240 | 240 | 2.44949 |
浮動小数点数(double)
| 方法 | 最小値 | 最大値 | 中央値 | 平均値 | 標準偏差 |
|---|---|---|---|---|---|
std::to_chars() |
45 | 51 | 46 | 47.3 | 1.92614 |
std::to_string() |
481 | 517 | 488 | 492.8 | 10.6846 |
std::stringstream |
617 | 761 | 628 | 639.1 | 41.1241 |
snprintf() |
245 | 264 | 250 | 250.4 | 4.98397 |
圧倒的じゃないか!というくらいにぶっちぎりでto_chars()最速です。
std::from_chars()
std::from_chars()は文字列から数値へ変換するものです。入力はcharの文字列限定で出力は引数に取った数値型変数への参照で返します。戻り値の扱いなどはto_chars()と似た感じです。
これとの比較対象は以下のものです。これらは同じく文字列→数値への変換を行います。
std::stoll()/std::stod()std::stringstreamsscanf()strtoll()/strtod()
測定方法
100万件のランダムな数値をto_chars()で文字列に変換しておき、それを全件変換にかけかかる時間を計測します。それを10回繰り返して各種統計量で見てみることにします。整数型(64bit整数型)と浮動小数点型(double)それぞれで実験を行います。
先ほどの処理と似たようなことになります。
#include <iostream> #include <charconv> #include <vector> #include <random> #include <chrono> #include <type_traits> #include <cassert> #include <thread> #include <numeric> #include <string> #include <string_view> template<typename NumericType> auto make_data(unsigned int N) -> std::pair<std::vector<char>, std::vector<std::string_view>> { auto rng = []() { if constexpr (std::is_integral_v<NumericType>) { return std::uniform_int_distribution<NumericType>{}; } else if constexpr (std::is_floating_point_v<NumericType>) { return std::uniform_real_distribution<NumericType>{}; } else { static_assert([] { return false; }, "You have to specify a number type, right?"); } }(); std::mt19937_64 urbg{ std::random_device{}() }; std::vector<char> buffer(N * 21); auto* pos = buffer.data(); std::vector<std::string_view> vec; vec.reserve(N); for (auto i = 0u; i < N; ++i) { const auto num = rng(urbg); const auto [end, ec] = std::to_chars(pos, pos + 21, num); if (ec != std::errc{}) { --i; continue; } const std::size_t len = end - pos; vec.emplace_back(pos, len); pos += (len + 1); } return {std::move(buffer), std::move(vec)}; } /* report()関数は変更ないので省略 */ template<typename NumericType, typename F> void profiling(const char* target, F&& func) { using namespace std::chrono_literals; constexpr int trialN = 10; constexpr int sampleN = 1'000'000; std::chrono::milliseconds results[trialN]{}; for (int i = 0; i < trialN; ++i) { //データの準備 auto [buf, input] = make_data<NumericType>(sampleN); //計測開始 auto start = std::chrono::steady_clock::now(); for (auto sv : input) { func(sv); } //計測終了 auto end = std::chrono::steady_clock::now(); results[i] = std::chrono::duration_cast<std::chrono::milliseconds>(end - start); std::this_thread::sleep_for(200ms); } std::cout << target << std::endl; report(results); } int main() { std::int64_t v; profiling<std::int64_t>("to_chars() int64", [&v](auto sv) { auto [ptr, ec] = std::from_chars(sv.data(), sv.data() + sv.length(), v); if (ec != std::errc{}) throw new std::exception{}; }); }
整数(std::int64_t)
単位は全てms
| 方法 | 最小値 | 最大値 | 中央値 | 平均値 | 標準偏差 |
|---|---|---|---|---|---|
std::from_chars() |
24 | 32 | 26 | 26.3 | 2.07605 |
std::stoll() |
129 | 159 | 132 | 134.5 | 8.23104 |
std::stringstream |
409 | 438 | 412 | 416.5 | 9.26013 |
sscanf() |
181 | 196 | 185 | 186.6 | 5.14198 |
strtoll() |
53 | 57 | 55 | 54.7 | 1.38203 |
浮動小数点数(double)
| 方法 | 最小値 | 最大値 | 中央値 | 平均値 | 標準偏差 |
|---|---|---|---|---|---|
std::from_chars() |
163 | 196 | 168 | 174.2 | 12.2213 |
std::stod() |
287 | 316 | 297 | 296 | 8.42615 |
std::stringstream |
445 | 531 | 456 | 464.6 | 23.5338 |
sscanf() |
339 | 352 | 348 | 346.6 | 3.66606 |
strtod() |
195 | 200 | 197 | 196.9 | 1.17898 |
以外にstrtoll()/strtod()が検討していますが、こちらもfrom_chars()最速です。しかし浮動小数点数変換は際どい・・・
なお、実装をチラ見するにstd::stoll()/std::stod()は対応するstrtoll()/strtod()によって変換を行っているだけなので、その速度差はstd::stringのオブジェクト構築と動的メモリ確保のオーバーヘッドから来るもののようです(std::stringstreamも結局は同じようにstrto~に投げていますが、こっちは更にもう少し色々してるみたいです)。
グラフで見てみる
先程のprofiling()を少し変更して処理時間をCSVに吐き出してグラフ化してみましょう。
template<typename NumericType, typename F> auto profiling(const char* target, F&& func) -> std::vector<std::chrono::milliseconds> { using namespace std::chrono_literals; constexpr int trialN = 10; constexpr int sampleN = 1'000'000; std::vector<std::chrono::milliseconds> results(trialN, 0); for (int i = 0; i < trialN; ++i) { //データの準備 auto [buf, input] = make_data<NumericType>(sampleN); //計測開始 auto start = std::chrono::steady_clock::now(); for (auto sv : input) { func(sv); } //計測終了 auto end = std::chrono::steady_clock::now(); results[i] = std::chrono::duration_cast<std::chrono::milliseconds>(end - start); std::this_thread::sleep_for(200ms); } std::cout << target << std::endl; return results; } template<std::size_t N> void output(const char* filename, std::vector<std::chrono::milliseconds>(&array)[N]) { std::ofstream ofs{ filename , std::ios::out | std::ios::trunc}; //BOM付加 unsigned char bom[] = { 0xEF, 0xBB, 0xBF }; ofs.write(reinterpret_cast<char*>(bom), sizeof(bom)); auto datanum = array[0].size(); for (auto i = 0u; i < datanum; ++i) { for (auto j = 0u; j < N; ++j) { ofs << array[j][i].count() << ", "; } ofs << "\n"; } } int main() { std::int64_t v; std::vector<std::chrono::milliseconds> res_array[5]{}; res_array[0] = profiling<std::int64_t>("from_chars() int64", [&v](auto sv) { auto [ptr, ec] = std::from_chars(sv.data(), sv.data() + sv.length(), v); if (ec != std::errc{}) throw new std::exception{}; }); output("from_chars_int64.csv", res_array); }
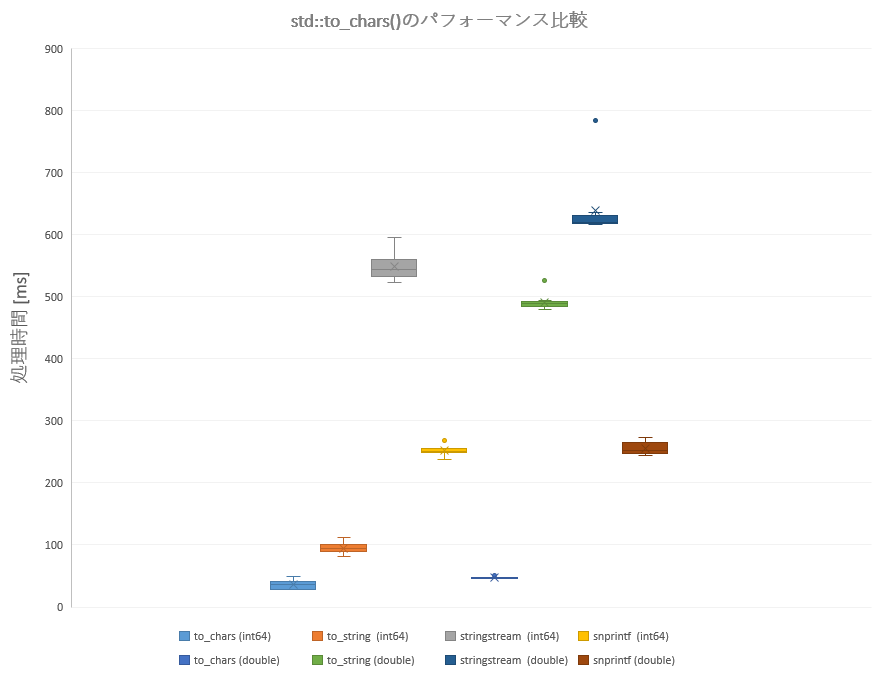
グラフは箱ひげ図で見てみます。
各箱は100万件の整数/浮動小数点数値に対する文字列⇄数値変換にかかった処理時間とばらつきを表しており、各箱に含まれるデータ数は10です。
箱の上辺は第三四分位点、下辺は第一四分位点、中央の線が中央値、×点が平均値を表しています。ひげの上辺は最大値、下辺は最小値を表し、それらから外れた孤立点は外れ値を表しています。
これによって、各処理方法毎のおおよその処理時間とそのばらつきを視覚的に確認・比較できます。
なお、データはここまでの実験とは別に取りなおしたものなので数値は上の表と一致していません。しかし、大まかな傾向に変化はないはずです。
std::to_chars()
std::from_chars()
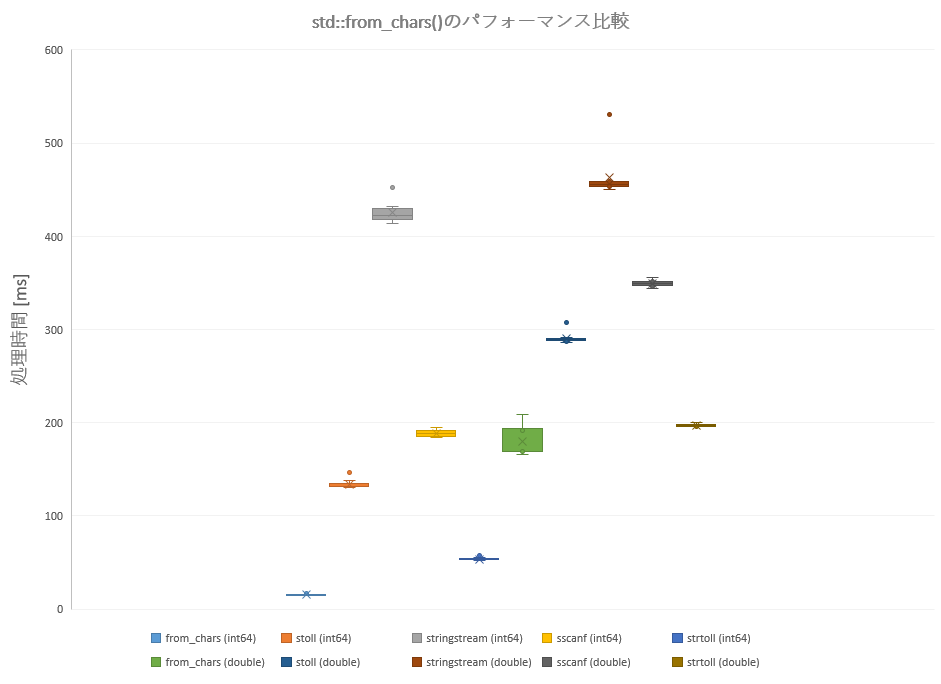
to_chars()/from_chars()が他よりも明らかに速い事が改めて確認できます。また、全体の傾向として整数変換よりも浮動小数点数変換の方が重いことも分かります。
相対比較
代表値として平均値を採用し、to_chars()/from_chars()の処理時間を1としたときの他の方法の処理時間の比を見てみます。これによって、系統的な誤差要因を無視したうえで他の方法がto_chars()/from_chars()の何倍遅いか?を見ることができます。
データは上の表にある平均値を利用します。
std::to_chars()
| 方法 \ 数値型 | int64_t |
double |
|---|---|---|
std::to_chars() |
1.00 | 1.00 |
std::to_string() |
2.82 | 10.4 |
std::stringstream |
18.6 | 13.5 |
snprintf() |
8.21 | 5.29 |
std::from_chars()
| 方法 \ 数値型 | int64_t |
double |
|---|---|---|
std::from_chars() |
1.00 | 1.00 |
std::stoll()/std::stod() |
5.11 | 1.70 |
std::stringstream |
15.8 | 2.67 |
sscanf() |
7.09 | 1.99 |
strtoll()/strtod() |
2.08 | 1.13 |
例えばこれをもって、std::stringstreamによる数値→文字列変換はstd::to_chars()に比べて、整数で18.6倍、浮動小数点数で13.5倍遅い!などという事ができます。
結論
使えるならto_chars()/from_chars()使いましょう!ちょっぱやです!!
注意点
これはあくまでMSVCの実装における結果なので、GCCやclang等ではまた違った結果になるかもしれません。C++標準はto_chars()/from_chars()の実装については何も規定していないためです・・・
GCCやclangは良い環境が手元に無いのと<charconv>の浮動小数点型対応がまだなので実験していません。