文書の一覧
全部で55本あり、SG22(C/C++相互互換性に関する研究グループ)のCの提案を除くと48本になります。
エラーハンドリングを戻り値で行うための型、std::expected<T, E>の提案。
std::expected<T, E>のオブジェクトは型TかEのどちらかの値を保持しており、Tの値を期待される値(正常値)、Eの値をエラーとして扱うことでエラーハンドリングを行います。これは、RustではResult<T, E>として重宝されています。
std::expectedを使うと、std::optional<T>はstd::expected<T, std::nullopt_t>のように書くことができ、std::optionalをエラー処理に用いる時に失われてしまっていたエラー詳細を同時に保持しておくことができるようになります。
std::expectedのインターフェースはstd::optionalをベースに、エラー値を保持している場合の操作を加えた形のものになります。
#include <expected>
auto maybe_succeed() -> std::expected<int, std::string_view> {
bool is_err = false;
if (is_err) {
return 46;
} else {
return {std::unexpect, "error!"};
}
}
int main() {
auto exp = maybe_succeed();
if (exp or exp.has_value()) {
int n = *exp;
int m = exp.value();
exp.error();
} else {
std::string_view s = exp.error();
*exp;
exp.value();
}
}
優れたエラーハンドリングメカニズムには、次のような事が求められます。
- エラーの可視性 : なんらかの処理が失敗するケースがコード上で隠されず、明確に表示されている
- エラーの情報 : エラーにはその発生場所や原因などが含まれる
- クリーンコード : エラー処理はできる限り目立たないように行われる。エラー処理は読みやすくなければならない
- 被侵入的 : エラーが通常の処理フローのためのチャネルを独占しない。それらはなるべく分離されているべき
この観点から、std::expectedと例外機構や通常のエラーコード戻り値によるエラー処理を比較すると
| 性質 |
std::expected |
例外 |
エラーコード戻り値 |
| 可視性 |
◯ |
△ |
◯ |
| 情報 |
◯ |
◯ |
△ |
| クリーンコード |
◯※ |
◯ |
× |
| 非侵入的 |
◯ |
◯ |
× |
※ monadicインターフェースがある場合(現在の提案には欠けている)
このように、std::expectedはエラー処理という観点から既存の方法よりも優れています。また、例外機構と比べるとパフォーマンスでも勝ります。
この部分の6割は以下の型のご指摘によって構成されています。
要素が削除されない限りそのメモリ位置が安定なコンテナであるstd::colonyの提案。
以前の記事を参照
このリビジョンでの変更は、実装を過度に指定しないように文言を修正したことと、一部の非メンバ関数をfriend関数に変更したことなどです。
標準ライブラリにハザードポインタを導入する提案。
以前の記事を参照
このリビジョンでの変更は、一般的な設計に関する情報と例の追記、用語の変更・追加・整理、一部のデフォルトコンストラクタを非explicitにし、一部のコンストラクタにnoexeceptを追加したことなどです。
この提案はLWGのレビューを完了しており、このリビジョンをもってConcurency TS v2導入のための全体投票にかけられる事が決まっています。何事もなければ、次の全体会議にてConcurency TSに入ることになります。
標準ライブラリにRead-Copy-Update(RCU)を導入する提案。
RCUは並行処理におけるデータ共有のための仕組みで、ロックフリーデータ構造の実装に用いることができます。
RCUでは、共有対象のデータはアトミックなポインタによって共有されており、共有データを更新する際は別の領域にデータを構築してから、ポインタを差し替えることで行います(ここまではハザードポインタと同じ)。共有データに触る際のクリティカルセクションでは、スケジューリング(プリエンプション)が起こらないようにして、クリティカルセクションはあるスレッドを占有して実行されるようにしてから、共有データへアクセスします。クリティカルセクションに入る際はOSの機能を使用してそのスレッドがスケジューリングされないようにしますが、何かロックを取得したりするわけではないのでオーバーヘッドはほぼゼロです。
読み取りの際は、共有データを読みだしている間そのスレッドはスケジューリングされず、データを見終わった後で通常通りスケジューリング対象に戻ります。
更新の際は、更新後のデータを別の領域に用意してからクリティカルセクションに入り、共有データを指すポインタを新しいデータを指すように差し替えます(この差し替えはアトミック)。その後、他のスレッドが最低一回以上スケジューリングされるまで待機してから、差し替え前の古いデータを削除しクリティカルセクションを抜けます。
クリティカルセクション中そのスレッドはスケジューリングされないので、処理はOSによって中断される事なく実行されています。そのため、更新スレッドから見て他のスレッドに対してスケジューリング一回以上行われたということは、共有データを読み取っている(更新前の古いデータを見ている)可能性のあるスレッドが読み取り処理を終えている事を意味します。
スレッドがスケジューリングされないようになるということは、クリティカルセクションの実行はCPUの論理コアを占有することになります。従って、更新スレッドが実行されているコアを除いたシステムのCPUの残りの論理コアにおいてスレッドの切り替えが一回以上行われていれば、更新スレッドが保持している古いデータを見ているスレッド(=クリティカルセクション)が無いこと分かるため、安全に削除できるということです。
データの差し替えはポインタによってアトミックに行われるため、更新が同時に行われてもデータ競合を起こしませんし、デッドロックすることもありません。ただし、RCUの全ての保証はユーザーが正しくクリティカルセクションを運用する事を前提としています。
RCUを使用して、複数のリーダー(reader)が並行して存在する時に、共有データの更新を実行する例。
std::atomic<std::string *> name;
void print_name() {
std::rcu_reader rr;
std::string *s = name.load(std::memory_order_acquire);
}
void update_name(std::string_view &nn) {
std::string *new_name = new std::string(nn);
std::string *s = name.exchange(new_name, std::memory_order_acq_rel);
std::rcu_retire(s);
}
リーダー(print_name())は1つのスレッドで実行され、更新処理(update_name())はそれとは別のスレッドで実行されます。print_name()内rcu_readerのオブジェクトは、リーダーの処理が完了するまで参照しているオブジェクトが、rcu_retire()によって削除されないように保護しています。
RCUは読み取りが頻繁に起こるが更新はあまりされないような場合に適した方法です。
この提案は別の提案(P0461R2)の標準へ提案する文書をまとめたもので、Concurrency TSに向けて提案され、議論されています。
著者の方(Paul McKenneyさん)の実装経験をベースにして長い時間をかけて議論されてきており、Concurrency TSに向けての議論がLWGまで進行しているのでConcurrency TSには入りそうですが、標準ライブラリの一部として利用可能となるにはもう少しかかりそうです。
スマートポインタとポインタのポインタを取るタイプのC APIとの橋渡しを行う、std::out_ptrの提案。
C APIでは、関数の中でのメモリアロケーションの結果などを呼び出し元に出力するために、ポインタのポインタ(T** / void**)を引数に取るものがよく見られます。ポインタではなくポインタのアドレスを渡す必要があり、std::unique_ptrをはじめとするスマートポインタはそれを取得する手段がないため、相性が良くありませんでした。
提案文書より、ffmpegにおけるサンプル。
#include <memory>
#include <avformat.h>
struct AVFormatContextDeleter {
void operator() (AVFormatContext* c) const noexcept {
avformat_close_input(&c);
avformat_free_context(c);
}
};
using av_format_context_ptr = std::unique_ptr<AVFormatContext, AVFormatContextDeleter>;
int main (int, char* argv[]) {
av_format_context_ptr context(avformat_alloc_context());
AVFormatContext* raw_context = context.release();
if (avformat_open_input(&raw_context, argv[0], nullptr, nullptr) != 0) {
std::stringstream ss;
ss << "ffmpeg_image_loader could not open file '"
<< path << "'";
throw FFmpegInputException(ss.str().c_str());
}
context.reset(raw_context);
return 0;
}
std::out_ptr/std::inout_ptrはこのような場合のrelease()とreset()の呼び出しを自動化し、スマートポインタに内包されているポインタのアドレスを抽出するものです。
int main (int, char* argv[]) {
av_format_context_ptr context(avformat_alloc_context());
if (avformat_open_input(std::inout_ptr(context), argv[0], nullptr, nullptr) != 0) {
std::stringstream ss;
ss << "ffmpeg_image_loader could not open file '"
<< argv[0] << "'";
throw FFmpegInputException(ss.str().c_str());
}
return 0;
}
このようなユーティリティは、大小様々な企業において再発明されていますが、その用途や目的はC APIの出力ポインタ(T**)引数にスマートポインタを直接渡せるようにする事で一貫しています。この提案は、そのような目的が同じでありながらそれぞれで再実装されているユーティリティの、将来性があり高性能で使いやすい共通の実装を標準で提供する事を目指したものです。
std::out_ptr/std::inout_ptrは関数であり、引数で受け取ったスマートポインタをラップした型(std::out_ptr_t/std::inout_ptr_t)のオブジェクトを返します。それらの型は元のポインタ型やvoid**への暗黙変換演算子を備えており、コンストラクタとデストラクタでrelease()とreset()を行います。
std::out_ptrとstd::inout_ptrの違いは、対象となるスマートポインタが予めリソースの所有権を持っているか否かによって使い分けるためにあります。
error_num c_api_create_handle(int seed_value, int** p_handle);
error_num c_api_re_create_handle(int seed_value, int** p_handle);
void c_api_delete_handle(int* handle);
struct resource_deleter {
void operator()( int* handle ) {
c_api_delete_handle(handle);
}
};
void normal_case() {
std::unique_ptr<int, resource_deleter> resource(nullptr);
error_num err = c_api_create_handle(24, std::out_ptr(resource));
if (err == C_API_ERROR_CONDITION) {
}
}
void reallocate_case(std::unique_ptr<int, resource_deleter> resource) {
error_num err = c_api_re_create_handle(24, std::inout_ptr(resource));
if (err == C_API_ERROR_CONDITION) {
}
}
std::out_ptrは空のスマートポインタにC API経由でリソースをセットするときに使用し、std::inout_ptrは予めリソースの所有権を保持しているスマートポインタをC APIに渡すときに使用します。
その他のサンプル
#include <memory>
#include <cstdio>
int fopen_s(std::FILE** f, const char* name, const char* mode);
struct fclose_deleter {
void operator()(std::FILE* f) const noexcept {
std::fclose(f);
}
};
int main(int, char*[]) {
constexpr const char* file_name = "ow.o";
std::unique_ptr<std::FILE, fclose_deleter> file_ptr;
int err = fopen_s(std::out_ptr<std::FILE*>(file_ptr), file_name, "r+b");
if (err != 0) {
return 1;
}
return 0;
}
#include <memory>
struct StarFish* starfish_alloc();
int starfish_populate(struct StarFish** ps, const char *description);
struct StarFishDeleter {
void operator() (struct StarFish* c) const noexcept;
};
using StarFishPtr = std::unique_ptr<StarFish, StarFishDeleter>;
int main(int, char*[]) {
StarFishPtr peach(starfish_context());
int err = starfish_populate(std::inout_ptr(peach), "caring clown-fish liker");
return err;
}
この提案は元々C++20入りを目指していましたが間に合いませんでした。C++20作業終了時点で提案は既にLWGに送付済みで、コロナウィルス流行などによって遅れていましたが、既にLWGでの最後のレビューが完了しています。次の全体会議で投票にかけられ、何事もなければC++23に導入されます。
この部分の6割は以下の方々のご指摘によって構成されています。
関数呼び出し演算子(operator())を、静的メンバ関数として定義できるようにする提案。
任意の関数オブジェクトを取ることで処理をカスタマイズできるようにすることは、標準ライブラリの多くの所で行われています。関数呼び出し演算子をテンプレートにすることで、オーバーロードを用意するよりもより簡易かつ便利に関数オブジェクトを利用できます。
また、C++20からはカスタマイゼーションポイントオブジェクト(CPO)と呼ばれる関数オブジェクトが多数追加されています。これらのCPOはメンバを持たないことが規定されています。
ラムダ式にせよ、ユーザー定義のものにせよ、CPOにせよ、関数呼び出し演算子のオーバーロードによって関数オブジェクトは成り立っていますが、関数呼び出し演算子は非静的メンバ関数としてしか定義できません。従って、その呼び出しに当たっては暗黙のthis引数が渡されています。
CPOやキャプチャしていないラムダのようにメンバアクセスの必要が皆無だったとしても、関数呼び出しがインライン展開されなければ関数呼び出し演算子オーバーロードによる呼び出しは常にthisポインタを引き渡すオーバーヘッドを埋め込んでいます。
struct X {
bool operator()(int) const;
static bool f(int);
};
inline constexpr X x;
int count_x(std::vector<int> const& xs) {
return std::count_if(xs.begin(), xs.end(),
#ifdef STATIC
X::f
#else
x
#endif
);
}
決して使用されない事が分かっていても、コンパイラは必ずしもこのオーバーヘッドを取り除くことができません。これはゼロオーバーヘッド原則に違反していますが、関数呼び出し演算子を静的メンバ関数として定義することはできません。
この提案は、この様なオーバーヘッドを取り除くために、関数呼び出し演算子を静的メンバ関数として定義できるようにしようとするものです。ステートレスな関数オブジェクトの有用性は、C++11のラムダ式導入以降広く認識されており、この様な制限を課しておく事に利益はありません。
そのほかのオーバーロード可能な演算子にも同様の事が言えますが、関数呼び出し演算子以外のものを静的メンバ関数として定義できるようにするユースケースが見られないため、ここでは関数呼び出し演算子だけを対象としています。
この提案の後では、キャプチャをしていないラムダ式の関数呼び出し演算子をstaticに定義することができるようになりますが、それをしてしまうとラムダ式の関数呼び出し演算子のメンバポインタを取り出すようなコードが壊れ、またABI破損に繋がります。
そのため、キャプチャしていないラムダ式の関数呼び出し演算子をstaticになるようにしてしまうことは出来ないため、オプトインする構文を提案しています。
auto four = []() static { return 4; };
auto five = []() { return 5; };
constexpr ifやstatic_assertの引数でのみ、整数型からbool型への暗黙の縮小変換を定数式で許可する提案。
以前の記事を参照
このリビジョンでの変更は、CWGからの指摘を受けて提案する文言を調整した事です。
この提案はEWGのレビューを通過し、CWGに転送されています。
viewによって別のrangeに変換されてしまった範囲を、元のrange(と同じ型)に戻す操作、std::ranges::reconstructと関連するコンセプトの提案。
Range Adopterの適用では、入力のrangeはviewの型に包まれる形で変換され、元の型とは別の型になってしまい、元には戻らなくなります。
template <typename T>
using span = quickcpplib::span<T>;
std::vector<int> vec{1, 2, 3, 4, 5};
span<int> s{vec.data(), 5};
span<int> v = s | views::drop(1) | views::take(10)
| views::drop(1) | views::take(10);
auto v2 = s | views::drop(1) | views::take(10)
| views::drop(1) | views::take(10);
この例では、decltype(v)からspan<int>への変換方法がないためコンパイルエラーを起こしています。
views::take/views::dropは指定された数だけイテレータを保存するor落とすことで、指定された数だけ要素を取り出すor無視する、という処理を行っており、viewの適用後も元のイテレータをそのまま利用しています。そのため、元のイテレータを用いれば元の型を再構成できるはずです。しかし、現在はその方法や判別方法がありません。
この提案は、そのような場合に再構成できるrangeを表すReconstructible Rangesという概念を導入し、そのためのADL-foundな関数とコンセプトを整備するものです。
先程の例の場合のようにイテレータとセンチネルのペアから元の型を再構成できる場合、それを行うためのカスタマイゼーションポイントとしてreconstruct関数を利用します。
それをstd::ranges::reconstructCPOによって呼び出すようにし、reconstructCPOによってpair_reconstructible_rangeとreconstructible_rangeの二つのコンセプトを定義します。
namespace std::ranges {
inline namespace unspecified {
inline constexpr nspecified reconstruct = unspecified;
}
template <class R,
class It = ranges::iterator_t<remove_reference_t<R>>,
class Sen = ranges::sentinel_t<remove_reference_t<R>>>
concept pair_reconstructible_range =
ranges::range<R> &&
ranges::borrowed_range<remove_reference_t<R>> &&
requires (It first, Sen last) {
reconstruct(
in_place_type<remove_cvref_t<R>>,
std::move(first),
std::move(last)
);
};
template <class R, class Range = remove_reference_t<R>>
concept reconstructible_range =
ranges::range<R> &&
ranges::borrowed_range<remove_reference_t<R>> &&
requires (Range first_last) {
reconstruct(
in_place_type<remove_cvref_t<R>>,
std::move(first_last)
);
};
}
std::ranges::reconstructCPOはタグ型(in_place_type<R>)とRのイテレータペア、もしくはタグ型とrangeを受け取り、そのイテレータ型について呼び出し可能なreconstruct関数を呼び出し、処理を委譲します。
reconstruct関数では、それぞれのイテレータ(range)に最適な方法によってイテレータペアから元のrangeの再構成を行います。
そして、標準ライブラリのviews::take/views::dropの呼び出しは、reconstructible_rangeコンセプトのモデルとなる型に対して、元のイテレータを使用して直接元の型を再構成して結果を返すようにします。
これによって冒頭のコードは次のようになります
template <typename T>
using span = quickcpplib::span<T>;
std::vector<int> vec{1, 2, 3, 4, 5};
span<int> s{vec.data(), 5};
auto v = s | views::drop(1) | views::take(10)
| views::drop(1) | views::take(10);
他の例
std::u8string name = "𐌀𐌖𐌋𐌄𐌑𐌉·𐌌𐌄𐌕𐌄𐌋𐌉𐌑 𐑡𐑹𐑡 ·𐑚𐑻𐑯𐑸𐑛 ·𐑖𐑷";
char16_t conversion_buffer[432];
std::u8string_view name_view(name);
std::span<char16_t> output(conversion_buffer, 432);
auto encoding_result = ztd::text::transcode(input, output);
auto unprocessed_code_units = encoding_result.input;
auto unconsumed_output = encoding_result.output;
標準ライブラリに、BLASをベースとした密行列のための線形代数ライブラリを追加する提案。
この提案は、BLASのAPIをベースとした密行列のための各種操作を行うフリー関数を追加する提案もので、ベクトル型や行列型を追加するものではなく、これらの関数は特定のデータ構造に依存していません。
関数はテンプレートで定義され、提案中のmdspanを用いることで特定のデータ型に依存しないようにされています。また、演算子オーバーロードを用いたexpressionテンプレートなインターフェースでもありません。
線形代数ライブラリ(ベクトル/行列型)を追加する提案は別に進行しておりユーザーが触れるインターフェースとなるのはそちらで、これは線形代数ライブラリの基礎となるものです。
提案文書より、コレスキー分解のサンプル
#include <linalg>
#include <cmath>
template<class inout_matrix_t, class Triangle>
int cholesky_factor(inout_matrix_t A, Triangle t)
{
using element_type = typename inout_matrix_t::element_type;
constexpr element_type ZERO {};
constexpr element_type ONE (1.0);
const ptrdiff_t n = A.extent(0);
if (n == 0) {
return 0;
}
else if (n == 1) {
if (A(0,0) <= ZERO || std::isnan(A(0,0))) {
return 1;
}
A(0,0) = std::sqrt(A(0,0));
}
else {
const std::ptrdiff_t n1 = n / 2;
const std::ptrdiff_t n2 = n - n1;
auto A11 = std::subspan(A, std::pair{0, n1}, std::pair{0, n1});
auto A22 = std::subspan(A, std::pair{n1, n}, std::pair{n1, n});
const int info1 = cholesky_factor(A11, t);
if (info1 != 0) {
return info1;
}
using std::linalg::symmetric_matrix_rank_k_update;
using std::linalg::transposed;
if constexpr (std::is_same_v<Triangle, upper_triangle_t>) {
auto A12 = subspan(A, std::pair{0, n1}, std::pair{n1, n});
using std::linalg::triangular_matrix_matrix_left_solve;
triangular_matrix_matrix_left_solve(transposed(A11),upper_triangle, explicit_diagonal, A12);
symmetric_matrix_rank_k_update(-ONE, transposed(A12), A22, t);
}
else {
auto A21 = std::subspan(A, std::pair{n1, n}, std::pair{0, n1});
using std::linalg::triangular_matrix_matrix_right_solve;
triangular_matrix_matrix_right_solve(transposed(A11), lower_triangle, explicit_diagonal, A21);
symmetric_matrix_rank_k_update(-ONE, A21, A22, t);
}
const int info2 = cholesky_factor(A22, t);
if (info2 != 0) {
return info2 + n1;
}
}
}
なお、Wordingのページだけで120P近くを占めており、とてつもなく巨大です・・・
MISRA C++およびWG23の文書についてのWG21 SG12でのレビュー作業の進捗状況に関する文書。
WG23は様々なプログラミング言語における脆弱性を調査するISOのワーキンググループです。2017年以降、WG23とWG21はC++の脆弱性を文書化するための作業を共同で行っています。その後、途中でMISRA C++の関係者もレビュープロセスに加わりました。
この作業の目的は単に脆弱性がどのようなコードから発生するのかを文書化することにあります。
標準ライブラリにいくつかの統計関数を追加する提案。
以前の記事を参照
このリビジョンでの変更は、NumPyを参考に一部の関数仕様を調整したことと、stats_errorを定数からクラスへ変更した事です。
この提案はSG16でのレビューを通過し、LEWGに転送されています。どうやらNumeric TSへ導入することを目指して議論されています。
クラスのデータメンバのメモリレイアウトを、宣言順に一致するように規定する提案。
現在の規定では、アクセス制御(private, public, protected)が異なる場合、実装はデータメンバを並べ替えてメモリに配置することができます。ただ、実際にそれを行う処理系は存在せず、実際のプログラムでは並べ替えを考慮されていないことがほとんどです。
この提案は、そのような慣行に従うように規定を修正し、クラスのデータメンバのメモリレイアウトが常にコード上の宣言順と一致するようにするものです。それによって、規則が単純になり、将来クラスレイアウトをコントロールするための機能を追加する際の土台とすることができます。
クラスレイアウトに関するこの制限は当初のC++から存在していたものではなく、C++11から偶発的に混入したもののようです。
当初のC++には、POD構造体はC言語との互換性がある必要がありましたがそれ以外のところに制限は特にありませんでした。そこで、クラスレイアウトをコントロールしたいユーザーから、ブロックやラベルによってクラスのデータメンバの配置をコントローする構文が提案されていました。これはC++11以前のことです。
C++11でその提案は採択されず、アクセス制御のみによってデータメンバの配置が変更されうるようにされました(N2342)。これは標準レイアウトクラスに関する作業で、クラスのレイアウトが不定になるような制限を導入する意図はなかったようです。
N2342による変更はC++が標準化されてから10年以上経過した後になされたもので、潜在的にはABIを破損する可能性がありましたが、これを活用する実装は現れなかったため実際に問題になることはありませんでした。
N2342による変更は最適ではなく、この点からもこのことは修正すべきです。ABI破損の可能性は悩ましいですが、目的を持って制御できなければ利点はありません。
constevalとstd::is_constant_evaluated()にある分かりづらい問題点を解決するためのconsteval ifステートメントの提案
以前の記事を参照
このリビジョンでの変更は、提案する文言の調整です。
この提案は、CWGとLWGでのレビューを終えており、次の会議で全体投票にかけられることが決まっています。何事もなければC++23に入りそうです。
識別子(identifier)の構文において、不可視のゼロ幅文字や制御文字の使用を禁止する提案。
以前の記事を参照
このリビジョンの変更点は、よくわかりません。
この提案はCWGのレビューを終え、次の全体投票にかけられることが決まっています。何事もなければC++23に入りそうです。
コンパイル時(プリプロセス時)にバイナリデータをインクルードするためのプリプロセッシングディレクティブ#embedの提案。
ハードリセット時にハードをフラッシュするためのベースイメージ、アイコンファイル、プログラムと強く連携するスクリプトなど、アプリケーションにバイナリデータを同梱したい場合があります。しかし、C/C++においてそれを行う簡易な方法はありません。
xxdコマンドを利用して16進リテラルとして埋め込んだり、環境のリンカを直接叩いてデータを埋め込み、それを指すexternポインタを利用するなど、様々な方法が考案されてきましたが、それを移植可能にしたり、ビルドシステムで管理しようとしたりすることは非常に困難です。
この提案は#embedというプリプロセッシングディレクティブを導入することで、簡易かつ移植可能な方法でバイナリデータをプログラムに埋め込めるようにしようとするものです。
新しいプリプロセッシングディレクティブという言語機能としてサポートしようとしているのは、数値リテラルの配列としてバイナリデータを埋め込む方法が非効率極まりないためです。
#embedは#includeに従うように設計されており、ほぼ同様に使用できます。
const unsigned char icon_display_data[] = {
#embed "art.png"
};
const char reset_blob[] = {
#embed "data.bin"
};
ただしこれは、あたかもバイナリデータを整数値としてコンマ区切りリストで展開しているかのように動作するというだけで、実際にそのような展開が起きているわけではありません。それをするとコンパイル時間を著しく増大させるためです。
すなわち、#embedによるバイナリデータ読み取りと展開はコピペではなく、コンパイラによって最適な方法で処理されています。
また、無限あるいは巨大なファイルの一部だけを読むために、長さを指定できるようになっています。
const int please_dont_oom_kill_me[] = {
#embed 32 "/dev/urandom"
};
ただし、この指定は上限であり厳密な要求値ではありません。実際に読み取った長さはより小さくなる可能性があります(その場合でも、配列長でコンパイル時に判定可能)。
std::string_viewのコンストラクタにrangeオブジェクトから構築するコンストラクタを追加する提案。
以前の記事を参照
このリビジョンでの変更は、LWGのレビューを受けて文言を修正したことです。
この提案はLWGのレビューを終えており、次の全体会議で投票にかけられることが決まっています。これもC++23に入りそうです。
↓
多次元コンテナサポートのために添字演算子([])が複数の引数を取れるようにする提案。
前回の記事を参照
R4での変更は、動機付けや代替案についての議論をより追記した事と、機能テストマクロを追加した事などです。
このリビジョンでの変更は、EWGの指示に基づいて、動機付けやユースケースについて追記した事などです。
この提案はEWGでのレビューが終了し、CWGに転送するための投票にかけられる予定です。
Rangeライブラリと連携可能なT型の要素列を生成するコルーチンジェネレータstd::generator<T>の提案。
前回の記事を参照
このリビジョンでの変更は、文言の修正、アロケータサポートの解説の改善、実装例の更新などです。
ガベージコレクタサポートのために追加された言語とライブラリ機能を削除する提案。
以前の記事を参照
このリビジョンでの変更は、削除するライブラリ名の名前を専用のセクションに追記した事です。
この提案はCWGとLWGのレビューを終えており、次の全体会議で投票にかけられる事が決まっています。何事もなければ、C++23に適用されます。
異なるエンコードプレフィックスを持つ文字列リテラルの連結を禁止する提案。
このリビジョンでの変更は、この変更を規格書のAnnex Cセクションに追記されるように文言を追加した事です。
この提案はすでにCWGのレビューを終え、次の全体会議で投票にかけられる事が決まっています。
また、これと同等の内容がすでにC言語には適用されているようです(N2594)。
バックスラッシュ+改行による行継続構文において、バックスラッシュと改行との間にホワイトスペースの存在を認める提案。
以前の記事を参照
このリビジョンでの変更は、CWGのレビューを受けて提案する文言を修正した事です。
この提案はすでにCWGのレビューを終え、次の全体会議で投票にかけられる事が決まっています。
std::spanとstd::string_viewはtrivially copyableである、と規定する提案。
以前の記事を参照
このリビジョンでの変更は、動機付けを追記した事、LEWGでの投票結果を記載した事、3つの主要実装がすでにそうなっている事を確認できるCompiler Explorerへのリンクを追記した事などです。
この提案は非常に小さいため、LEWGのレビューを簡易にパスして、LWGに送るためのLEWGでの投票待ちをしています。
一時オブジェクトが参照に束縛されたことを検出する型特性を追加し、それを用いて一部の標準ライブラリの構築時の要件を変更する提案。
以前の記事を参照
このリビジョンでの変更は、この提案によって影響を受けるtuple/pairのコンストラクタをオーバーロード解決から除外するのではなくdeleteとして定義するようにした事です。
この提案はEWGでのレビューをパスしてLEWGのレビュー待ちをしています。
提案中のany_invocableの名前を変更する提案。
以前の記事を参照
このリビジョンでの変更はよくわかりません。この提案はすでにP0288に適用されています。
std::unique_ptrを全面的にconstexpr対応する提案。
以前の記事を参照
このリビジョンでの変更は、機能テストマクロを__cpp_lib_constexpr_memoryをバージョンアップするように変更したことと、nullptrに対してもconstexprでswap、比較とdefault_deleterが機能するようにしたことです。
<memory>にある未初期化領域に対する操作を行う各関数をconstexprにする提案。
以前の記事を参照
このリビジョンでの変更は、機能テストマクロを追加したこと、文言の影響範囲を明確にしたこと、default_construct_atの必要性の説明を追記したことです。
↓
↓
C++コンパイラが少なくともUTF-8をサポートするようにする提案。
以前の記事を参照
R1での変更は、ホワイトスペースについてのセクションと関連する文言を取り除いたことです。どうやら、空白文字を具体的に指定することを避けたようです(SG16では合意自体は取れていたようですが)。
R2での変更は、BOMについてのガイドラインを追記したこと、Clangが将来的に幅広いエンコーディングを採用する予定であることを明確にしたこと、翻訳フェーズ5時点でのコードポイントの保存がP22314R1によって処理されることを明確にしたことなどです。
R3での変更は、SG16のガイダンスに従って、文言を修正したことです。
<ranges>にzip_view, adjacent_view, zip_transform_view, adjacent_transform_viewを追加する提案。
以前の記事を参照
このリビジョンでの変更は機能テストマクロを追加したこと、前方向またはそれよりも弱いzip_viewのイテレータのoperator==についての説明を追記したこと、adjacent_viewがinput_rangeをサポートしない事についての説明、簡単なサンプルコードの追加および文言の修正です。
std::vector v1 = {1, 2};
std::vector v2 = {'a', 'b', 'c'};
std::vector v3 = {3, 4, 5};
fmt::print("{}\n", std::views::zip(v1, v2));
fmt::print("{}\n", std::views::zip_transform(std::multiplies(), v1, v3));
fmt::print("{}\n", v2 | std::views::pairwise);
fmt::print("{}\n", v3 | std::views::pairwise_transform(std::plus()));
rangeアルゴリズムであるranges::foldの提案。
以前の記事を参照
このリビジョンでの変更は、weakly-assignable-fromコンセプトを使用していたところをassignable_fromコンセプトに置き換えた事、foldの戻り値型は初期値の型ではなくなった事です。
foldの戻り値型の問題は次のようなコードで結果がどうなるのかという事です。
namespace std::ranges {
template <range R, movable T, typename F,
typename U = >
auto fold(R&& r, T init, F f) -> U {
}
}
std::vector<double> v = {0.25, 0.75};
auto r = ranges::fold(v, 1, std::plus());
この場合に、ranges::foldの戻り値型をU = std::decay_t<std::invoke_result_t<F&, T, ranges::range_reference_t<R>>の様に決めることで戻り値型が初期値から決まらないようにしています。それに伴って必要な制約を追加して、この提案では上記のrはdoubleの2.0になります。
Viewとみなされる型にデフォルト構築可能性を要求しない様にする提案。
以前の記事を参照
このリビジョンでの変更は、標準に提案する文言を追加した事です。
この提案はまだLEWGでのレビュー中ですが、採択された際にC++20にさかのぼって適用される可能性があります。
非推奨となったvolatile値に対する複合代入演算子を再考する提案。
C++はOSの無い組み込みのプログラミングにおいても利用されています。そこではメモリにマップされたレジスタ(メモリマップドI/O)を操作することによってハードウェアを操作し、多くの場合特定の1bitにしか触りません。そこでは次のようなコードが頻出します。
struct ADC {
volatile uint8_t CTRL;
volatile uint8_t VALUE;
...
};
#define ADC_CTRL_ENABLE ( 1 << 3 )
ADC1−>CTRL |= ADC_CTRL_ENABLE;
ADC1−>CTRL &= ~ADC_CTRL_ENABLE;
このようなコードは、ベンダから提供されたマクロや関数の中で使用される場合もあるほか、コードジェネレーターが生成するコードに含まれていることもあります。
しかしこのようなvolatile値に対する複合代入演算子の使用は、アクセス回数が誤解されやすいためC++20からは非推奨とされました。
今日、Cライブラリの多くの所でこのような操作は利用されており、非推奨化はそれらのライブラリがC++から利用できなくなることを意味します。ベンダ提供のヘッダファイルは多くの場合安定性を優先するために更新されることは稀で、むしろ新しいバージョンのコンパイラを使用しないようにする可能性があります。
また、volatile値に対する複合代入演算子の仕様を推奨されているように書き直したとき、気づき辛いバグを埋め込むことになる可能性があります
UART1−>UCSR0B |= (1<<UCSZ01 ) ;
UART1−>UCSR0B = UART1−>UCSR0B | (1<<UCSZ01 ) ;
UART2−>UCSR0B = UART1−>UCSR0B | (1<<UCSZ01 ) ;
^^^^^
このように、別のデバイスの特定のレジスタを読まなければならないのに、コピペミスによって元のデバイスのレジスタを参照し続けてしまいます。このエラーは発見が難しく、volatileが誤って使用された場合のエラーとコードの冗長化によるこのエラーとを交換しているだけになっています。
これらの理由により、volatile値に対する複合代入演算子の非推奨化は間違った判断であり、元に戻そうという提案です。
<cmath>および<complex>の数学関数のconstexpr対応を、ランタイムの実装が正しくなるまで遅らせる提案。
C++における数学関数はIEEE754を参照しているため、そこで定義される正しい丸めによって結果を返す必要がありますが、現在のランタイムの実装は特に32bit浮動小数点数で誤っています。すなわち、ある数学関数に対する同じ入力に対して得られる出力は必ずしも実装間で一致しません。
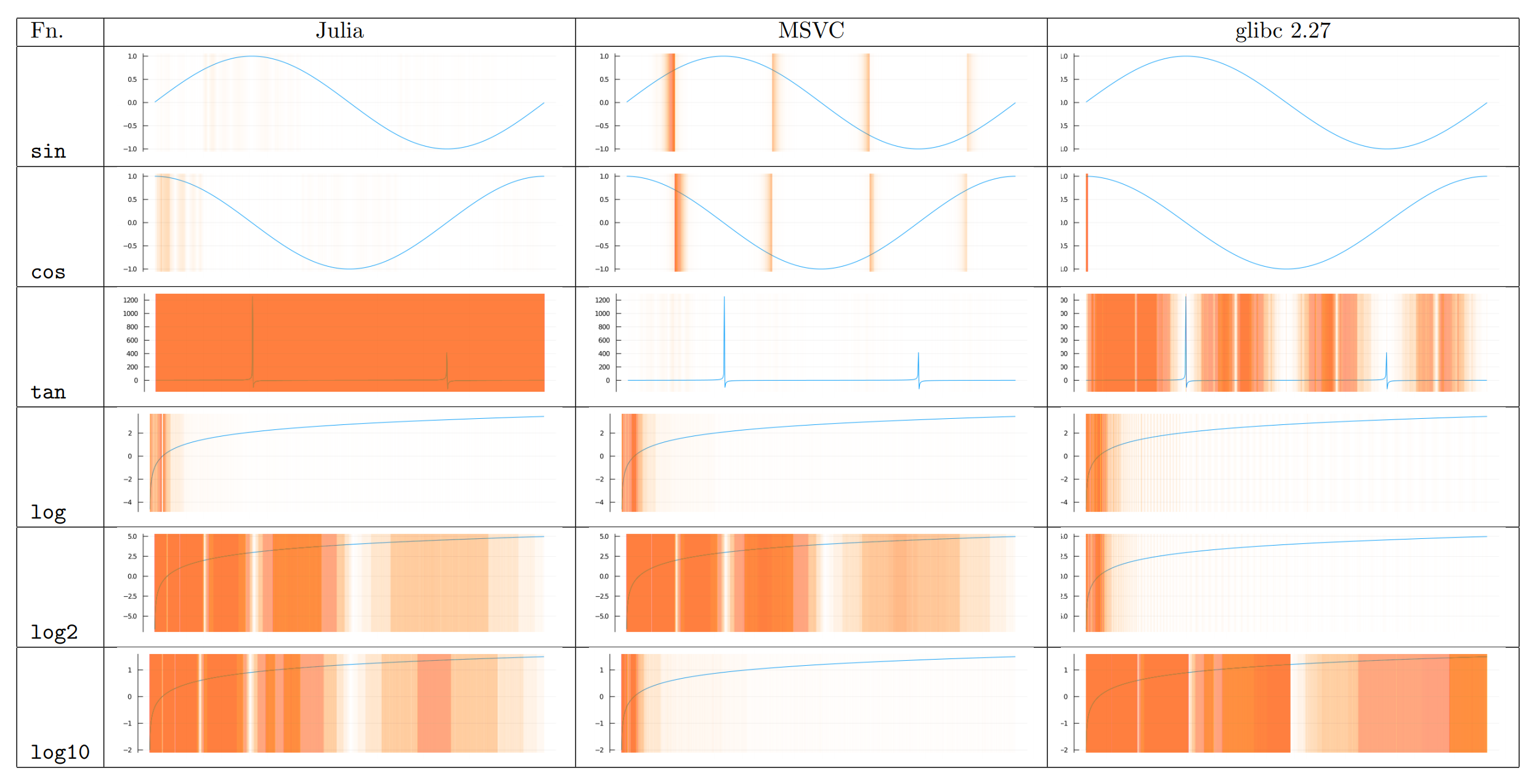
(色のついた部分が誤った丸めが行われている部分)
これは浮動小数点数計算の移植性を損ねていると同時に、コンパイル時と実行時でその結果が一致しないことが同じ実装においても生じうることを意味しています。
正しいにしても間違っているにしても、ある特定の実装における丸めの結果に依存している様なコードは、コンパイル時計算と実行時計算の間の結果の不一致によって静かなバグを埋め込むことにつながりかねません。
実行時に同様の問題が既に存在していることが分かっているのに、同じ問題を追加するのは避けるべきであり、ランタイムの実装が正しくなるまではconstexpr対応をしない方がいい、という提案です。
また、C言語に対して進行中のISO/IEC TS 18661-4:2015で提案されている、crプリフィックスをもつ関数(正しい丸めによる結果を返すことが保証されている関数)をC++にも追加して、それに対してのみconstexprを付加することを代替案として挙げています。
この部分の6割は以下の型のご指摘によって構成されています
ドル記号($)、アットマーク(@)、バッククオート(`)の3つが将来の機能のためのトークンとして使用可能であることを説明する文書。
AsciiとEBCDICにある記号のうち、$と@と`の3つだけがC++で使用されていません。これらによる構文は将来の提案のために使用できる可能性があります。この文書はその可能性を検討したものです。
バッククオート以外の記号はC++を拡張した言語や外部ツールなどでよく使用されており、そこでの構文とバッティングする可能性が高そうです。どうやら、@<...>, ${...}, $(...)のような構文は使用可能のようです。
ムーブ後オブジェクトの要件を緩和する提案。
movableコンセプトあるいはassignable_fromコンセプトでは、ムーブ後オブジェクトの状態を「有効だが未規定(valid but unspecified)」と定めています。一方で、ライブラリ要件ではムーブ後オブジェクトの状態は単に「未規定(unspecified)」とされています。
ここでの「有効」は定義されていませんが、クラスの不変条件を満たしていて、クラスの全ての操作が規定された振る舞いをしたうえで、未規定の状態、のような意味だと思われます。
しかし実際のところ通常のムーブ操作では「有効」な状態にしておくことは難しく、これを強いることは余計なオーバーヘッドの原因や、ユーザー定義操作の可能性を妨げています。一方で完全に未規定にしてしまうのも望ましくないため、「有効」の意味を詳しく規定することでムーブ後オブジェクトの状態をある程度規定しようとする提案です。
既存の標準ライブラリの実装では、ムーブ後オブジェクトに対して次のような操作だけが必要なようです。
mf.~()mf = amf = move(a)mf = move(mf)
この提案はムーブ後オブジェクトは少なくともこれらの操作は行えることを要求しようとするものです。
この提案では特に、セルフスワップ(std::swap(a, a))をサポートすることに焦点を当てています。セルフスワップはstd::random_shuffe()などの古い標準ライブラリの実装に現れることがあり、結局はセルフムーブ代入(a = std::move(a))操作に帰着します。
ただし、セルフムーブ代入が有効な操作となるのはムーブ後オブジェクトにおいてのみです。a = std::move(b)の様な代入では、事後条件としてaはbの操作前の値を保持し、bは未規定の値を保持します。しかし、a = std::move(a)を考慮するとその指定は矛盾しており、それでもその両方の保証が満たされるのはaが既に未規定の値となっている、すなわちムーブ後オブジェクトである場合のみです。ここに有効性を要求してしまうと、セルフムーブ代入操作は有効な操作とはなりません。
この提案では、ムーブ後オブジェクトに対してのみセルフムーブ代入操作を有効であると規定する案と、より一般のオブジェクトに対してセルフムーブ代入操作を有効であると規定する案の二つのどちらかを選択することを提案しています。
ユニコードの使用に従う形で、改行と空白を明確に定義する提案。
この提案では以下の点が変更されます。
- whitespaceを文法用語として導入する
- whitespaceという言葉は別に定義するwhitespaceの集合を参照する
- 垂直タブは
//コメントを終了することを規定
- new-lineをline-breakで置き換える
- new-lineはLFによる改行文字を示すようになる
- 翻訳フェーズ1-7まで、コメントを含めたすべてのホワイトスペースが保存されるようになる
- 文字の集合は、現在のものから拡張しない
- ホワイトスペースとみなされるものを追加しない
- ただし、CRLFが一つの改行(line-break)とみなされるようになる
- line-breakは生文字列リテラル中ではLF(new-line)にマップされる
変更は多岐にわたりますが、破壊的な変更は意図されていません。
constexpr対応クラスの簡易構文の提案。
C++20にてstd::vector/std::stringの全てのメンバがconstexpr対応され、そのほかのコンテナやスマートポインタも対応させる提案が提出されています。
クラスメンバ関数をconstexpr対応させるにはすべてのメンバ関数にconstexprを付けて回らねばならず、冗長な記述となっています。
この提案では、クラス宣言にconstexprを付加することでクラスのメンバがすべて暗黙constexpr関数となるようにする構文を提案しています。
| C++20 |
この提案 |
class SomeType {
public:
constexpr bool empty() const { }
constexpr auto size() const { }
constexpr void clear() { }
};
|
class SomeType constexpr {
public:
bool empty() const { }
auto size() const { }
void clear() { }
};
|
これは丁度finalを指定できるところにおけるようにするものです。
また、これはちょうどそのクラスのみに作用するように提案されています。つまり、派生先や基底クラスには影響を与えません。
他にもconstやconstevalも考えられますが、この提案ではconstexprに絞られています。
SG16(Unicode study group)の2020/12/09-2021/03/24までの間のミーティングにおける議事録。
P2237で提案されたmetaprogramとinjectionをテンプレートパラメータなど、カンマ区切りリストの文脈でも使用可能に拡張する提案。
P2237およびP0712では、constevalを用いたシンプルなコードジェネレーション機能であるmetaprogramを導入しました。
consteval {
for (int i = 0; i < 10; ++i) {
generate_some_code(i);
}
}
generate_some_code()はここにソースコードを注入するconsteval関数です。metaprogramは無名変数の初期化子として呼び出される無名のconsteval関数と捉えることができます。
P2237ではmetaprogramを発展させたコードfragmentのinjectionを提案しています。
template<struct T>
class Interface {
public:
consteval {
template for (auto data : meta::data_members_of(^T))
<< <class {
virtual typename [:meta::type_of(data):]
|#"get_" + meta::name_of(data)#|() const = 0;
}>;
}
};
consteval void inject_field() {
<< <class { int i = 4; }>;
}
consteval void inject_vardecl() {
<< <{ int i = 4; }>;
}
class A {
consteval {
inject_field();
}
};
void f() {
consteval {
inject_vardecl();
}
}
これらの構文は名前空間スコープやクラススコープ、ブロックスコープ内でのみ使用可能なものとして提案されており、それ以外の所、とくにテンプレートパラメータリストをはじめとするカンマ区切りリスト内では使用できませんでした。
この提案は、consteval{}を書くことのできるコンテキストを拡張したうえで、新しいいくつかのfragmentを追加することを提案しています。そして、fragmentの種類を増やしたことで、P2237の構文の拡張が困難になったことから、^<K>{}の形式の新しいfragmentの構文も提案しています。
^<frag::stmt>{ [:m:] = 42; }
^<frag::expr>{ 3, [:m:] + 4 }
^<frag::parm>{ int i, int j }
^<frag::tparm>{ typename T, int N }
^<fram::targ>{ [:Trefl:], [:Nrefl:] }
^<frag::init>{ 3, .[:m:] = 4 }
^<frag::cinit>{ [:m:](3), [:n:](4) }
^<frag::base>{ public Foo, private virtual [:Barrefl:] }
可変長テンプレートの畳み込み式において、() []の2つの演算子を使用可能にする提案。
[]は添え字演算子に複数の引数を渡せるようにする提案(P2128R3)の検討で発案され、言語サポートによってそれを達成する代わりに使用できる可能性があります。
decltype(auto) index(auto &arr, auto ...args) {
return arr[args...];
return arr[arg1, arg2, ..., argN];
}
decltype(auto) index(auto &arr ,auto ...args) {
return (arr[...][args]);
return arr[arg1][arg2]...[argN];
}
この[]による構文と展開を自然に()に拡張することができます。それによって、畳み込み式で利用するためだけに演算子オーバーロードを使用するようなワークアラウンドをいくらか簡単にすることができます。
namespace detail {
template<class F>
struct call {
F &&f;
template<class T>
decltype(auto) operator|(T &&t) const {
return std::forward<F>(f)(std::forward<T>(t));
}
};
}
template<class T, class X>
decltype(auto) nest_tuple(T &&t,X &&x) {
return std::apply(
[&x]<class ...TT>(TT &&...tt) -> decltype(auto) {
return (detail::call<TT>{std::forward<TT>(tt)} | ... | std::forward<X>(x));
return tt1 | (tt2 | (... | (ttN | x)));
},
std::forward<T>(t));
}
template<class T,class X>
decltype(auto) nest_tuple(T &&t,X &&x) {
return std::apply(
[&x]<class ...TT>(TT &&...tt) -> decltype(auto) {
return (std::forward<TT>(tt)(...(std::forward<X>(x)));
return tt1(tt2(...(ttN(x))));
},
std::forward<T>(t));
}
これらの利点から、畳み込み式で[] ()を使えるようにしようとする提案です。
パラメータパックをpack、[] or ()による呼び出しが可能な型のオブジェクトをc、任意の初期項をaとすると、この提案による拡張は次の様な構文になります
(pack[...]);
(...[pack]);
(pack[...[a]]);
(c[...][pack]);
(pack(...));
(...(pack));
(pack(...(a)));
(c(...)(pack));
packの中身をarg1, arg2, ..., argNとして、それぞれ次のように展開されます
arg1[arg2[arg3[...[argN]]]];
arg1[arg2][arg3]...[argN];
arg1[arg2[...[argN[a]]]];
c[arg1][arg2]...[argN];
arg1(arg2(arg3(...(argN))));
arg1(arg2)(arg3)...(argN);
arg1(arg2(...(argN(a))));
c(arg1)(arg2)...(argN);
複雑ではありますが、()と[]は対応する構文によって同じ記述が可能で、その構文によって従来の4つの畳み込みのいずれかに帰着され、適用される演算子opを[] ()に変更しパックの要素を包み込むように展開されます。
さらに、これらの構文による二項畳み込みの...の後の()内には、pack, lists...の形のリストを書くことができます。
(pack(...(a, b, c)));
(c(...)(pack, a, b, c));
これは次のように展開されます
arg1(arg2(...(argN(a, b, c))));
c(arg1, a, b, c)(arg2, a, b, c)...(argN, a, b, c);
[]の時はこのリストを{}で包む必要がある以外は、()と同様になります。
(pack[...[{a, b, c}]]);
(c[...][{pack, a, b, c}]);
Factoryパターンを自動的に実装する方法についてのプレゼンテーション資料。
これはSG7のメンバに向けて、現在提案中のリフレクションを用いて、外部のメタデータから任意のクラスのオブジェクトを構築するコードを生成するメタプログラミング手法について解説されています。
SG21で議論されているContracts関連の用語を定義する文書。
これはContractsについて何か設計を提案するものではなく、SG21の議論で頻出する概念について、対応する言葉と意味を定義しておくものです。
主に想定されるバグの種類、契約違反を検出したときの振る舞いの各候補についてなどに名前を当て意味を説明しています。
if forなどのinit-statementに、using宣言を書けるようにする提案。
C++17でif switch、C++20で範囲forの構文が拡張され、init-statementという初期化領域を置けるようになりました。
そこには通常の変数の初期化宣言の他にtypedef宣言も書くことができますが、なぜかusingは書けません。
この提案はusing/typedefの一貫性を向上させるために、init-statement内でusingによるエイリアス宣言を書けるようにする提案です。
for (typedef int T; T e : v) { ... }
for (using T = int; T e : v) { ... }
モダンC++ではtypedefよりもusingの使用が推奨されていますが、init-statementはそれができない唯一の場所のようです。
また、対応としては逆にinit-statementにおけるtypedefを禁止するという方法もありますが、typedefのスコープを制限するために利用されているらしく、usingでも同じことができるようにすることを提案しています。
コンパイル時にのみ使用され、実行時まで残らない文字列リテラルについての扱いを明確化する提案。
_Pragma, asm, extern, static_assert, [[deprecated]], [[nodiscard]]など、文字列リテラルはコンパイル時にのみ使用される文脈に現れることができます。このような文字列はナローエンコーディングやエンコーディングプリフィックスで指定されたエンコーディングに変換されるべきではありません。
そのため、これらの文字列にはユニコード文字を含めることができる点を除いて、エンコーディングに関して制約されるべきではありません。
しかし、現在これらの文字列は区別されることなく実行時にも使用される文字列と同じ扱いを受けており、エンコーディングの制約も同様です。
この提案は、コンパイル時メッセージなどでユニコードを活用できるようにするために、コンパイル時にのみ使用される文字列について特別扱いするようにする提案です。
この提案は、コンパイル時にのみ使用される文字列について次のように扱われるようにします
この変更は破壊的なものですが、オープンソースのコードベース調査ではほとんど影響がないようです。
エンコード可能ではない、あるいは複数文字を含むワイド文字リテラルを禁止する提案。
文字リテラルには複数の文字を指定することができ、それはワイド文字リテラルにおいても同様です。ワイド文字リテラルではそれに加えて、1文字が1つのコード単位に収まらない文字リテラルを書くことができます。
wchar_t a = L'🤦<200d>♀️';
wchar_t b = L'ab';
wchar_t c = L'é́';
上記のaはwchar_tのサイズが4バイトである環境(Linuxなど)では書いたままになりますが、2バイトの環境(Windowsなど)だと表現しきれないためUTF-16エンコーディングで読み取られた後に、上位か下位の2バイトが最終的な値として取得されます(Windowsは上位2バイトが残る)。
bはマルチキャラクタリテラルと呼ばれるもので、どの文字が残るか、あるいはどういう値になるかは実装定義とされます。MSVCでは最初の文字が、GCC/Clangでは最後の文字が残るようです。
cは2つのユニコード文字から構成されており、これもマルチキャラクタリテラルの一種です。これは1文字で同じ表現ができる文字がユニコードに存在していますが(\u00e9)、eと́́の2文字を組み合わせて表現することもでき、後者の場合は表示上は1文字ですが、1コード単位ではなく2コード単位の文字列となります。
このように、これらの文字列の扱いは実装間で一貫しておらず移植性もなく、視認しづらいことからバグの原因となりえるため、禁止しようという提案です。
ただし、wchar_tのサイズが4バイトである環境の上記aのケースは適正であるため、引き続き使用可能とされます。
これは破壊的変更となりますが、コンパイラのテストケースを除いて、オープンソースのコードベースでは使用されているコードは発見できなかったようです。
連想コンテナの透過的操作を、さらに広げる提案。
C++20では、非順序連想コンテナに対して透過的な検索を行うことのできるオーバーロードが追加されました。「透過的」というのは連想コンテナのキーの型と直接比較可能な型については、一時オブジェクトを作成することなくキーの比較を行う事が出来ることを指します。これによって、全ての連想コンテナで透過的な検索がサポートされました。
現在、C++23に向けて削除の操作に関して同様にしようとする提案(P2077R2)がLWGにおいて議論中です。
この提案は、その対象さらに広げて、以下の操作を透過的にするものです。
std::set/std::unorderd_setのinsertstd::map/std::unorderd_mapのinsert_or_assign/try_emplace/operator[]/at- 非順序連想コンテナの
bucket
この提案の後では、これらの操作の際にKeyと異なる型の値について一時オブジェクトの作成が回避されるようになり、パフォーマンス向上が期待できます。