文書の一覧
全部で75本あります。(新規35本
- N4924 WG21 2022-10 Admin telecon minutes
- N4925 2023-02 Issaquah meeting information
- N4926 Working Draft, C++ Extensions for Library Fundamentals, Version 3
- N4927 Editor's Report: C++ Extensions for Library Fundamentals, Version 3
- P0901R10 Size feedback in operator new
- P1018R18 C++ Language Evolution status 🦠 pandemic edition 🦠 2022/07–2022/11
- P1018R19 C++ Language Evolution status
- P1028R4 SG14 status_code and standard error object
- P1202R5 Asymmetric Fences
- P1264R2 Revising the wording of stream input operations
- P1478R8 Byte-wise atomic memcpy
- P1619R2 Functions for Testing Boundary Conditions on Integer Operations
- P2164R8 views::enumerate
- P2167R3 Improved Proposed Wording for LWG 2114 (contextually convertible to bool)
- P2248R7 Enabling list-initialization for algorithms
- P2396R1 Concurrency TS 2 fixes
- P2434R0 Nondeterministic pointer provenance
- P2539R4 Should the output of std::print to a terminal be synchronized with the underlying stream?
- P2546R3 Debugging Support
- P2548R2 copyable_function
- P2548R3 copyable_function
- P2548R4 copyable_function
- P2552R1 On the ignorability of standard attributes
- P2559R1 Plan for Concurrency Technical Specification Version 2
- P2564R1 consteval needs to propagate up
- P2564R2 consteval needs to propagate up
- P2564R3 consteval needs to propagate up
- P2570R1 Contract predicates that are not predicates
- P2588R2 Relax std::barrier phase completion step guarantees
- P2589R1 static operator[]
- P2602R2 Poison Pills are Too Toxic
- P2614R2 Deprecate numeric_limits::has_denorm
- P2615R1 Meaningful exports
- P2616R1 Making std::atomic notification/wait operations usable in more situations
- P2616R2 Making std::atomic notification/wait operations usable in more situations
- P2640R2 Modules: Inner-scope Namespace Entities: Exported or Not?
- P2644R1 Final Fix of Broken Range based for Loop Rev 1
- P2647R1 Permitting static constexpr variables in constexpr functions
- P2649R0 2022-10 Library Evolution Poll Outcomes
- P2650R0 2022-11 Library Evolution Polls
- P2652R1 Disallow user specialization of allocator_traits
- P2653R1 Update Annex E based on Unicode 15.0 UAX 31 Steve Downey
- P2655R1 common_reference_t of reference_wrapper Should Be a Reference Type
- P2657R1 C++ is the next C++
- P2658R1 temporary storage class specifiers
- P2659R1 A Proposal to Publish a Technical Specification for Contracts
- P2664R0 Proposal to extend std::simd with permutation API
- P2674R1 A trait for implicit lifetime types
- P2679R1 Fixing std::start_lifetime_as and std::start_lifetime_as_array
- P2681R0 More Simple Statistics
- P2693R0 Formatting thread::id and stacktrace
- P2695R0 A proposed plan for contracts in C++
- P2696R0 Introduce Cpp17Swappable as additional convenience requirements
- P2697R0 Interfacing bitset with string_view
- P2698R0 Unconditional termination is a serious problem
- P2700R0 Questions on P2680 “Contracts for C++: Prioritizing Safety”
- P2701R0 Translating Linker Input Files to Module Metadata Files
- P2702R0 Specifying Importable Headers
- P2703R0 C++ Standard Library Ready Issues to be moved in Kona, Nov. 2022
- P2704R0 C++ Standard Library Immediate Issues to be moved in Kona, Nov. 2022
- P2705R0 C++ Library Fundamentals TS Issues to be moved in Kona, Nov. 2022
- P2706R0 Drafting for US 26-061: Redundant specification for defaulted functions
- P2708R0 No Future Fundamentals TSes
- P2708R1 No Future Fundamentals TSes
- P2709R0 Core Language Working Group “ready” Issues for the November, 2022 meeting
- P2710R0 Core Language Working Group NB comment resolutions for the November, 2022 meeting
- P2711R0 Making multi-param (and other converting) constructors of views explicit
- P2711R1 Making multi-param constructors of views explicit
- P2712R0 Classification of Contract-Checking Predicates
- P2718R0 Wording for P2644R1 Fix for Range-based for Loop
- P2722R0 Slides: Beyond operator() (P2511R2 presentation)
- P2723R0 Zero-initialize objects of automatic storage duration
- P2725R0 std::integral_constant Literals
- P2726R0 Better std::tuple Indexing
- P2727R0 std::iterator_interface
- おわり
N4924 WG21 2022-10 Admin telecon minutes
WG21の各作業部会の管理者ミーティングの議事録。
前回から今回の会議の間のアクティビティの報告がされています。
N4925 2023-02 Issaquah meeting information
2023年2月に行われる予定のWG21全体会議のインフォメーション。
次回は、アメリカのワシントン州イサクアで行われる予定で、内容は主に会場の案内についてです。
N4926 Working Draft, C++ Extensions for Library Fundamentals, Version 3
Library Fundamental TS v3のワーキングドラフト。
N4927 Editor's Report: C++ Extensions for Library Fundamentals, Version 3
↑の差分を記した文書。
変更点は
- P2705R0 : 報告されたIssueの解決
- P0987R2 : 型消去の代わりに
polymorphic_allocator<>を使用するように変更 - P2708R1 : LFTSをこれ以上更新しないことを明記
の内容を適用したことなどです。
P0901R10 Size feedback in operator new
::operator newが実際に確保したメモリのサイズを知ることができるオーバーロードを追加する提案。
以前の記事を参照
- P0901R7 Size feedback in operator new interface - [C++]WG21月次提案文書を眺める(2020年11月)
- P0901R8 Size feedback in operator new interface - [C++]WG21月次提案文書を眺める(2021年01月)
- P0901R9 Size feedback in operator new interface - [C++]WG21月次提案文書を眺める(2022年05月)
このリビジョンでの変更は、提案するnew式の設計の詳細を追記したこと、サイズを返さないoperator new()にフォールバックする振る舞いの削除、セクションの整理、などです。
P1018R18 C++ Language Evolution status 🦠 pandemic edition 🦠 2022/07–2022/11
2022年7月から11月にかけてのEWG活動報告書。
主にコア言語のIssueのレビューが主だったようです。
なお、C++23についての作業は終了しているらしく、これ以降コア言語の提案をC++23に向けて作業することはないようです。
P1018R19 C++ Language Evolution status
2022年11月のkona会議のEWG活動報告書。
コア言語のIssueやNBコメントのレビュー・投票が行われていたようです。
C++26に向けて、以下の提案がCWGに転送されました
- P1061R0 Structured Bindings can introduce a Pack
- P2361R0 Unevaluated string literals
- P2014R0 aligned allocation of coroutine frames
- P0609R1 Attributes for Structured Bindings
- P2558R0 Add @, $, and ` to the basic character set
- P2621R0 UB? In my Lexer?
- P2686R0 Updated wording and implementation experience for P1481 (constexpr structured bindings)
- P1967R0 #embed - a simple, scannable preprocessor-based resource acquisition method
- P2593R0 Allowing static_assert(false)
次の提案はLEWGに転送されました
- P2641R0 Checking if a union alternative is active
- P2546R0 Debugging Support
- P0876R5 fiber_context - fibers without scheduler
- P2141R0 Aggregates are named tuples
P1028R4 SG14 status_code and standard error object
現在の<sysytem_error>にあるものを置き換える、エラーコード/ステータス伝搬のためのライブラリ機能の提案。
<sysytem_error>ヘッダはstd::error_code関連のものを擁するヘッダで。C++11にて、当時のFilesystem TSから分離される形で先行導入されました。<filesystem>を使うとき以外はあまり使用されることはないようですが、これは標準の多くのヘッダファイルから参照されており、標準ヘッダの内部依存関係の一部を構成しています。
このエラーコードインターフェースの設計上の問題は近年(2018年ごろ)明らかになり、正しく使うことが難しく、エラー報告のためのインターフェースなのにエラーを起こしやすいなどの問題がありました。それはP0824R1で纏められて報告され、現在のstd::error_code周りの問題を改善した代替の機能が追求されました。
この提案は、そのようなライブラリ機能を実装するとともにBoost.Outcomeなどでの経験をベースとして、現在のエラーコードインターフェースの問題を解決し置き換えることを目指したライブラリ機能を提案するものです。
このライブラリの中核は、std::error_codeを置き換えるstd::system_codeというクラス型です。これはシステムの何かしらのコード(必ずしもエラーではない)を統一的に表現するためのクラスで、使用感はほぼstd::error_codeと同様です。
std::system_code sc; // デフォルト構築は空(成功でもエラーでもない) native_handle_type h = open_file(path, sc); // 失敗しているかをチェック if(sc.failure()) { // ファイルが見つからないため失敗したかをエラーコードとの比較によってチェック // この比較は値ベースではなく意味論的な比較となる if(sc != std::errc::no_such_file_or_directory) { std::cerr << "FATAL: " << sc.message().c_str() << std::endl; std::terminate(); } }
このopen_file()はプラットフォームによって次のように実装できます。
// POSIXシステムの場合 using native_handle_type = int; native_handle_type open_file(const char *path, std::system_code &sc) noexcept { sc.clear(); // 非エラー状態にする // ファイルオープン native_handle_type h = ::open(path, O_RDONLY); // エラーチェック if (h == -1) { // errnoはsystem_codeに型消去される sc = std::posix_code(errno); } return h; }
// Windowsの場合 using native_handle_type = HANDLE; native_handle_type open_file(const wchar_t *path, std::system_code &sc) noexcept { sc.clear(); // 非エラー状態にする // ファイルオープン native_handle_type h = CreateFile(path, GENERIC_READ, FILE_SHARE_READ|FILE_SHARE_WRITE|FILE_SHARE_DELETE, nullptr, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, nullptr ); // エラーチェック if (h == INVALID_HANDLE_VALUE) { // GetLastError()の結果はsystem_codeに型消去される sc = std::win32_code(GetLastError()); } return h; }
この新しいsystem_codeは、std::error_codeの次のような点を改善しています
<string>に依存しないconstexpr対応std::error_categoryの、リンク時にランダムに比較が壊れる問題が起きないbool変換時の曖昧さがないstd::error_codeのbool変換でtrueが帰るのはエラー状態の時とは限らない(値が非ゼロであることしか意味しない)
- 上記と関連して、
0を特別扱いせず、成功と失敗を任意に表現できる - 比較が意味ベース(エラーコードとの比較はその値の比較ではなく、意味するエラー状態の比較になる)
std::error_codeのように値ベースではないstd::error_conditionとstd::error_codeのように分かりづらい関係性のクラスを必要としない
- エラーコードの型が任意(
std::error_codeはint限定) - 複数のシステムエラーコードを扱うことができる
- エラーカテゴリの厳密な区別
また、この提案には含まれていないように見えますが、P0709で提案されている静的例外クラスstd::errorを実装し、それをエラー状態とする戻り値型result<T>も提案しようとしているようです。これは、std::expected<T, std::error>と非常によく似ているクラスですが、エラー型がハードコーティングされていることによって若干異なるインターフェースを持っています。
- P0824R1 Summary of SG14 discussion on <system_error>
- Reference implementation for proposed SG14 status_code (<system_error2>) in C++ 11 - Github
- P1028 進行状況
P1202R5 Asymmetric Fences
非対称なフェンスの提案。
以前の記事を参照
- P1202R3 Asymmetric Fences - [C++]WG21月次提案文書を眺める(2021年01月)
- P1202R4 Asymmetric Fences - [C++]WG21月次提案文書を眺める(2022年02月)
このリビジョンでの変更は、提案する文言の明確化のみのようです。
この提案は11月のkona会議でConcurrency TS v2へ導入することが決まっています。
P1264R2 Revising the wording of stream input operations
<istream>の例外に関する規定を改善する提案。
現在の<istream>の規定は非常に複雑になっており、特にいつ例外を投げるのかが分かりづらく、それによって実装間で振る舞いに差異が生じています。
空でないストリームからの抽出に失敗する入力操作の例
#include <iostream> #include <sstream> int main () { std::stringbuf buf("not empty"); std::istream is(&buf); // failbitがセットされたら例外を送出する is.exceptions(std::ios::failbit); bool threw = false; try { unsigned int tmp{}; // 数値を読み取れないので失敗する is >> tmp; } catch (std::ios::failure const&) { threw = true; } std::cout << "bad = " << is.bad() << std::endl; std::cout << "fail = " << is.fail() << std::endl; std::cout << "eof = " << is.eof() << std::endl; std::cout << "threw = " << threw << std::endl; }
この結果は、実装によって次のようになります
| libstdc++ | MSVC STL | libc++ | |
|---|---|---|---|
| bad | 0 | 0 | 1 |
| fail | 1 | 1 | 1 |
| eof | 0 | 0 | 0 |
| threw | 1 | 1 | 0 |
正しいのはlibstdc++/MSVC STLの振る舞いに思えますが、現在の複雑な規定によればlibc++の振る舞いも合法のようです。ただ、この振る舞いは有用ではなく、ほぼ無意味です。
空のストリームからの抽出に失敗する入力操作の例
#include <iostream> #include <sstream> int main () { std::stringbuf buf; // empty std::istream is(&buf); // failbitがセットされたら例外を送出する is.exceptions(std::ios::failbit); bool threw = false; try { unsigned int tmp{}; // 数値を読み取れないので失敗する is >> tmp; } catch (std::ios::failure const&) { threw = true; } std::cout << "bad = " << is.bad() << std::endl; std::cout << "fail = " << is.fail() << std::endl; std::cout << "eof = " << is.eof() << std::endl; std::cout << "threw = " << threw << std::endl; }
この結果は、実装によって次のようになります
| libstdc++ | MSVC STL | libc++ | |
|---|---|---|---|
| bad | 0 | 0 | 1 |
| fail | 1 | 1 | 1 |
| eof | 1 | 1 | 1 |
| threw | 1 | 1 | 0 |
正しいのはlibstdc++/MSVC STLの振る舞いに思えますが、やはりこれもlibc++の振る舞いが間違っているわけではないようです。
この提案は、このような状況を招いている複雑な規定を明確になるように修正し、libstdc++/MSVC STLの振る舞いを維持したままlibc++の振る舞いを修正しようとするものです。
P1478R8 Byte-wise atomic memcpy
アトミックにメモリのコピーを行うためのstd::atomic_load_per_byte_memcpy()/std::atomic_store_per_byte_memcpy()の提案。
以前の記事を参照
- P1478R4 Byte-wise atomic memcpy - [C++]WG21月次提案文書を眺める(2020年7月)
- P1478R5 Byte-wise atomic memcpy - [C++]WG21月次提案文書を眺める(2020年11月)
- P1478R6 Byte-wise atomic memcpy - [C++]WG21月次提案文書を眺める(2020年12月)
- P1478R7 Byte-wise atomic memcpy - [C++]WG21月次提案文書を眺める(2022年02月)
このリビジョンでの変更はP2396R1関するLEWGの要望を反映したことです。
この提案は11月のkona会議でConcurrency TS v2へ導入することが決まっています。
P1619R2 Functions for Testing Boundary Conditions on Integer Operations
整数演算の境界条件をチェックするためのライブラリ関数の提案。
C++の整数演算には誰もが遭遇する境界条件(最大値・最小値を跨ぐような演算)についての罠があります。これは初心者でも簡単に遭遇しうる一方で、その理解にはC++言語の知識や整数のハード上表現の知識、数学的な知識などを必要とし、アサーションのためにその判定を書くことはかなりの注意を必要とします。
提案より、整数の二項演算で行われることの流れ図
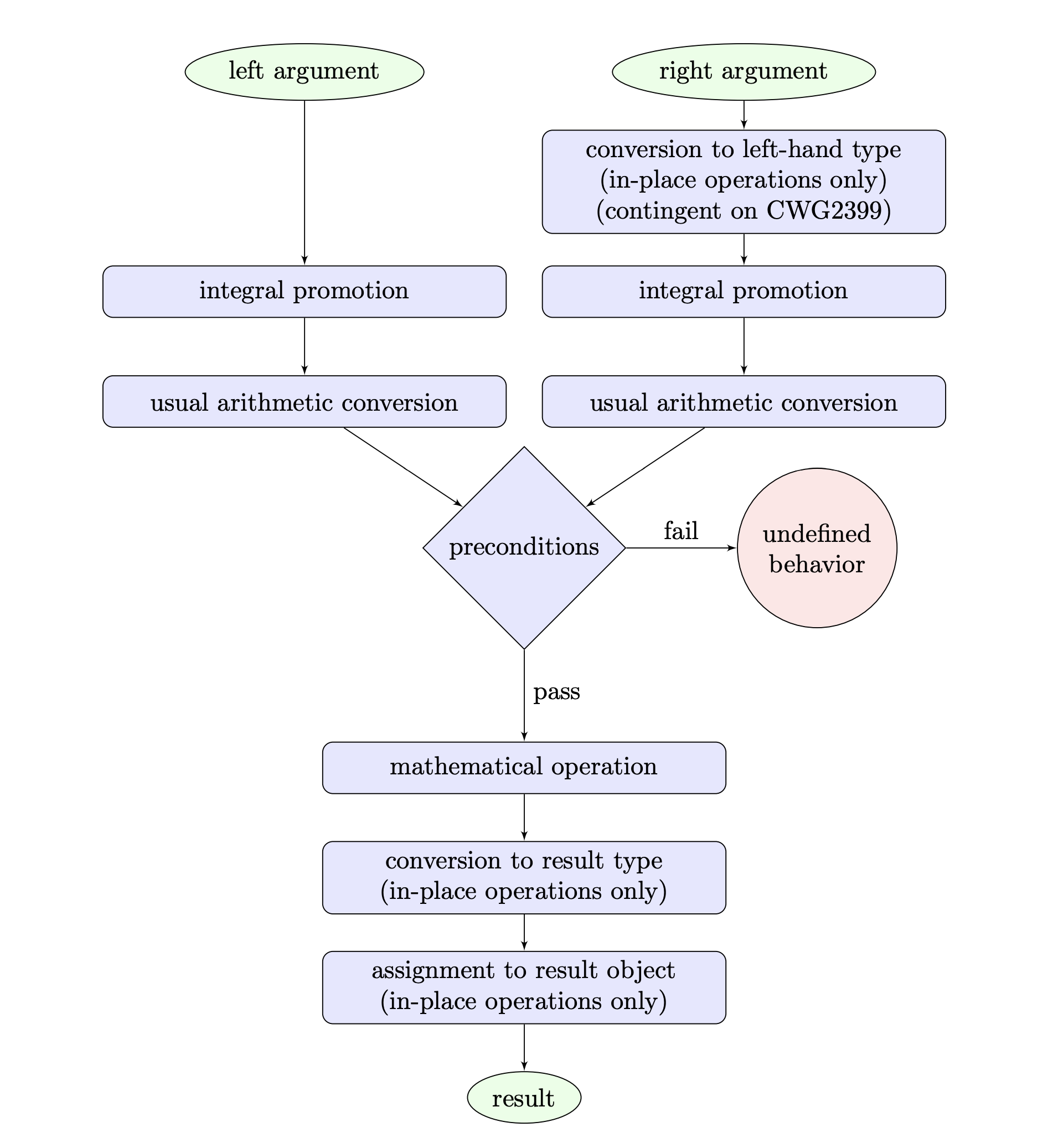
(提案によれば、この図は修正が必要な箇所があり、他の部分についても修正の必要がある可能性があり、それこそが整数演算の複雑さを現している、とのことです・・・)
この提案は、そのような境界条件に関するアサーションに使用するための、条件を簡単かつ直接的に命名及び表現したライブラリ関数を追加しようとするものです。
この提案による関数群は多岐に渡りますが、いずれもプリフィックスcan_~で始まり、bool値を返すconstexpr関数です。
#include <limits> int add(std::integral auto lhs, std::integral auto rhs) { // 2つの整数値の足し算が問題なく行えるか assert(std::can_add(lhs, rhs)); // 足し算の結果をintに正しく変換できるか assert(std::can_convert<int>(lhs + rhs)); return lhs + rhs; }
他にも、インクリメント等の単項演算子、四則演算と%などの2項演算子、+= *=などの複合代入演算子(_in_placeが後ろにつく)にそれぞれ対応した関数が用意され、全ての関数に_modularが後ろにつくバージョン(2^Nを法とするモジュロ演算によるもの)が用意されています。
この関数群は次の条件を全てパスする場合にtrueを返し、そうでなければfalseを返します。
- 各関数に指定された式が評価されると、その実行はwell-formed
- 各オペランドについて、整数昇格と変換が適用される前後の値は
2^Nを法として合同。また、比較演算と/ /= % %= >> >>=の両オペランド、<< <<=の右オペランドについて、整数昇格と変換の適用前後の値は等しくなる。 - 式の結果と数学演算の結果は
2^Nを法として合同。また、ポストフィックスに_modularが付かない関数では、式の結果と数学演算の結果は等しくなる。
この提案による関数群は、C++26以降で導入されるContractにおいても有用であると思われます。
P2164R8 views::enumerate
元のシーケンスの各要素にインデックスを紐付けた要素からなる新しいシーケンスを作成するRangeアダプタviews::enumerateの提案。
以前の記事を参照
- P2164R0 views::enumerate - [C++]WG21月次提案文書を眺める(2020年5月)
- P2164R1 views::enumerate - [C++]WG21月次提案文書を眺める(2020年6月)
- P2164R2 views::enumerate - [C++]WG21月次提案文書を眺める(2020年9月)
- P2164R3 views::enumerate - [C++]WG21月次提案文書を眺める(2020年11月)
- P2164R4 views::enumerate - [C++]WG21月次提案文書を眺める(2021年02月)
- P2164R5 views::enumerate - [C++]WG21月次提案文書を眺める(2021年06月)
- P2164R6 views::enumerate - [C++]WG21月次提案文書を眺める(2022年08月)
- P2164R7 views::enumerate - [C++]WG21月次提案文書を眺める(2022年10月)
このリビジョンでの変更は
enumerate_resultを削除(SG9での投票により要素型をstd::tupleで一貫させることが決定)- 1引数コンストラクタに
explicitを付加 enable_borrowed_range特殊化を追加- 入力の
view(元のシーケンス)のborrowed_range性を受け継ぐ
- 入力の
- インデックスのみを取得する
.index()をenumerate_viewのイテレータに追加 - その他文言の改善や修正
などです。
このリビジョンで追加された.index()は、入力のviewのoperator*()が重く(コストがかかり)、インデックスの値だけが必要な場合に、元の範囲のイテレータの間接参照を回避してインデックス数値を取得するためのものです。
#include <vector> #include <ranges> int main() { std::vector days{"Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"}; auto ev = days | std::views::enumerate; for (auto it = ev.begin(); it != ev.end(); ++it) { auto idx = it.index(); // 元のイテレータの間接参照を避け、インデックスのみを取得する ... } }
この提案はLEWGのレビュー中ですが、先行してLWGのレビューが完了しています。
P2167R3 Improved Proposed Wording for LWG 2114 (contextually convertible to bool)
contextually convertible to boolと言う規格上の言葉を、C++20で定義されたboolean-testableコンセプトを使用して置き換える提案。
- P2167R0 : Improved Proposed Wording for LWG 2114 - [C++]WG21月次提案文書を眺める(2020年5月)
- P2167R1 Improved Proposed Wording for LWG 2114 (contextually convertible to bool) - [C++]WG21月次提案文書を眺める(2021年7月)
- P2167R2 Improved Proposed Wording for LWG 2114 (contextually convertible to bool) - [C++]WG21月次提案文書を眺める(2021年7月)
このリビジョンでの変更は、フィードバックに基づく提案する文言の修正のみです。
この提案は11月のKona会議でC++23WDへの導入が決定しています。
P2248R7 Enabling list-initialization for algorithms
値を指定するタイプの標準アルゴリズムにおいて、その際の型指定を省略できるようにする提案。
以前の記事を参照
- P2248R0 Enabling list-initialization for algorithms - [C++]WG21月次提案文書を眺める(2020年11月)
- P2248R1 Enabling list-initialization for algorithms - [C++]WG21月次提案文書を眺める(2020年12月)
- P2248R2 Enabling list-initialization for algorithms - [C++]WG21月次提案文書を眺める(2021年10月)
- P2248R3 Enabling list-initialization for algorithms - [C++]WG21月次提案文書を眺める(2021年12月)
- P2248R4 Enabling list-initialization for algorithms - [C++]WG21月次提案文書を眺める(2022年01月)
- P2248R5 Enabling list-initialization for algorithms - [C++]WG21月次提案文書を眺める(2022年07月)
- P2248R6 Enabling list-initialization for algorithms - [C++]WG21月次提案文書を眺める(2022年10月)
このリビジョンでの変更は、Rangeアルゴリズムのテンプレートパラメータにデフォルトを指定するために必要な実装によるテンプレートパラメータの並べ替えが許可されるのか?についての疑問を追記したこと、projected_value_tをフリースタンディング指定したことなどです。
P2396R1 Concurrency TS 2 fixes
Concurrency TSv2を目指しているいくつかの提案について、本題と関係の薄い微修正の提案。
以前の記事を参照
このリビジョンでの変更は、ハザードポインタとRCUに対して配置するヘッダの変更と機能テストマクロの追加を提案していることです。
この提案は11月のKona会議でConcurrency TS 2への適用が決定しています。
P2434R0 Nondeterministic pointer provenance
現在のC++のポインタ意味論をポインタのprovenanceモデルに対して整合させるための提案。
ポインタにおけるprovenanceという概念は、ポインタのprovenance(出自・由来・出所)を重視したポインタの意味論のことで、現在の整数アドレス的なポインタ意味論で行えてしまっていることを制限しようとするものです。これによって、コンパイラのエイリアス解析においてより多くの仮定を行えるようになり、最適化が促進されます。そこでは特に、ポインタ値を整数にキャストした後で戻すという操作によってprovenanceがどこまで伝播するのかが問題となっています。
C/C++の規格にはこの概念はまだ導入されておらず、P2381R1にて提案段階にあります。そこでは、いくつかのprovenanceモデルが挙げられています
- PNVI (provenance-not-via-integer)
- (ポインタをキャストした)整数値を介してポインタのprovenanceの追跡をする代わりに、整数->ポインタのキャスト地点で指定されたアドレスが生存期間内にあるオブジェクトを指しているかをチェックし、問題がなければそこでprovenanceを再作成する
- PNVI-ae (PNVI exposed-address)
- PNVI-ae-udi (PNVI exposed-address user-disambiguation):
- PVI (provenance-via-integers)
- 整数演算を介したときでもprovenanceを追跡するモデル。ポインタ値だけでなく全ての整数値に対してprovenanceを関連づけ、整数/ポインタのキャスト前後でprovenanceを保持し、整数とポインタの
+ -整数演算の結果のprovenanceに関して特別な選択を行う。
- 整数演算を介したときでもprovenanceを追跡するモデル。ポインタ値だけでなく全ての整数値に対してprovenanceを関連づけ、整数/ポインタのキャスト前後でprovenanceを保持し、整数とポインタの
Cのprovenance導入議論においての最有力候補はPNVI-ae-udiモデルです。おそらくこれはC++においても同様となるでしょう。
規格には取り込まれていなくても、現在のC++(最新のC++23ドラフト N4917)が規定するポインタセマンティクスは既に整数アドレス的なものではなく、ポインタのprovenanceが禁止することを目的とする多くの状況は現在も未定義動作となります。
int main() { int jenny=0; // std::cout << &jenny; *(int*)8675309=1; return jenny; }
実装がこの整数値(8675309)に対するポインタを特別に定義していないとすると、このコードはPNVI-ae-udi及びPVIの両方で未定義動作となり(どちらも、整数値8675309にprovenanceを見出せない)、現在のC++においてもキャストが無効なポインタ値を生成する可能性があることから未定義動作になります。
int main() { int x,y=0; uintptr_t p=(uintptr_t)&x,q=(uintptr_t)&y; p^=q; q^=p; p^=q; *(int*)q=*(int*)p; return x; }
PVIでは、p, qの操作の結果得られる値はそのprovenanceを継承しない(^=は特別扱い演算の対象外な)ためこれを許可しません。PNVI-ae-udiでは、main()内2行目でストレージインスタンスが露出しており、整数演算(xorによるswap)後のp, qが生存期間内にあるオブジェクトを指していることから許可されます。
C++では、x, yのアドレスがどのように選択されたとしてもq(p)は結局x(y)のアドレスになるため、ポインタへのキャストは交換されたポインタを生成し、これは許可されます。この解釈は任意の整数演算やI/O操作に及びます。
int main() { int *p=new int; uintptr_t i=(uintptr_t)p; delete p; p=new int(1); if((uintptr_t)p==i) *(int*)i=0; return *p; }
PVIでは、新しいポインタpと以前のp由来の整数iを比較しただけではiにpのprovenanceが継承されないため、これを許可しません。PNVI-ae-udiでは、新しいオブジェクトのアドレス(pのポインタ値)が比較(後段2行目(uintptr_t)p==i)時に露出するため、それと同じ値を持つiのポインタへのキャストは新しいpと同じ値になるため、これは許可されます。
C++では、iが新しいpと同じ値を持っていれば、キャストによって同じポインタに戻されるため、これは許可されます。
このように、現在のC++のポインタ意味論と規定はPNVI-ae-udiモデルによく整合しているように見えます。しかし、現在のC++のポインタ規定はudi(user-disambiguation)を実装していません。往復変換が許可されるポインタは元の値を持つと規定されている([expr.reinterpret.cast]/5)ため、オブジェクトへのポインタとメモリ内でその直後の場所を指すポインタに対して同じ整数値を生成する実際の実装を(誤って?)禁止しています(つまり、1つの整数値に対するポインタ値が複数存在する可能性があり、実際にそのような実装があるようです)。
同様に、[basic.types.general]/2–4は、バイト列から構成されたポインタかもしれないものについても同様に元の値を持つこと(値表現が一致すること)を要求しており、そのような状況を許可していません。
std::bit_castは同じ値表現を持つ複数の値の可能性を認めるものの、結果の値は未規定としています。
この提案は、udi(user-disambiguation)を実装(該当する場合を未定義動作ではなく)するために、これらに関連する規定を修正しようとするものです。
変更は、ポインタの値表現(ビット列)については、同じビット列が複数のポインタ値に対応する可能性があり、(memcpyなどによって)そのビット値が取得される(acquires)時は、その複数ある中からwell-definedとなる(未定義動作とならない)1つを選択する、のようにします。これによって、udi(user-disambiguation)が実装され、現在のC++のポインタ規定をPNVI-ae-udiモデルにより整合させることができます。
- 旧石器時代のポインタをご利用の皆様へ ~provenance入門~ - Qiita
- Provenance-aware Memory Object Model for C - zenn.dev
- P2434 進行状況
P2539R4 Should the output of std::print to a terminal be synchronized with the underlying stream?
提案中のstd::print(P2093)が出力するストリームについて、同じストリームに対する他の出力との同期を取るようにする提案。
- P2539R0 Should the output of std::print to a terminal be synchronized with the underlying stream?` - WG21月次提案文書を眺める(2022年03月)
- P2539R1 Should the output of std::print to a terminal be synchronized with the underlying stream?` - WG21月次提案文書を眺める(2022年04月)
- P2539R3 Should the output of std::print to a terminal be synchronized with the underlying stream?` - WG21月次提案文書を眺める(2022年10月)
このリビジョンでの変更は、LWGのフィードバックに基づく文言の修正です。
この提案は11月のKona会議でC++23WDへの導入が決定しています。
P2546R3 Debugging Support
標準ライブラリにデバッグサポートの為のユーティリティを追加する提案。
以前の記事を参照
- P2546R0 Debugging Support - WG21月次提案文書を眺める(2022年02月)
- P2546R1 Debugging Support - WG21月次提案文書を眺める(2022年04月)
- P2546R2 Debugging Support - WG21月次提案文書を眺める(2022年10月)
このリビジョンでの変更は、提案する文言の修正とEWGでの投票の結果を追記した事です。
この提案はEWGでの承認が得られたためLEWGでのレビューが開始されます。
P2548R2 copyable_function
↓
P2548R3 copyable_function
↓
P2548R4 copyable_function
std::move_only_functionに対して、コピー可能なCallableラッパであるcopyable_functionの提案。
以前の記事を参照
- P2548R0
copyable_function- WG21月次提案文書を眺める(2022年07月) - P2548R1
copyable_function- WG21月次提案文書を眺める(2022年10月)
R2での変更は、以前に適用していたP2511R2(std::nontype)の内容を削除した事です(P2511がLEWGでコンセンサスを得られなかったため。
R3での変更は
- デザインセクションのcallable要件を修正
std::functionの非推奨化についてのOpen Questionを削除move_only_functionへの変換をmove_only_functionへ移動move_only_functionの変換コンストラクタを利用する
- 標準ライブラリのポリモルフィックCallableラッパ間の変換関係についてのセクションを追加
- アロケータサポートの可能性についてのセクションを追加
- この提案ではやらない
R4(このリビジョン)での変更は、move_only_functionの変換コンストラクタで変換時に例外を投げない規定を削除した事です。
- P2511R0 Beyond
operator(): NTTP callables in type-erased call wrappers - WG21月次提案文書を眺める(2022年01月) - P2548 進行状況
P2552R1 On the ignorability of standard attributes
属性を無視できるという概念について、定義し直す提案。
以前の記事を参照
このリビジョンでの変更は明確ではありませんが、全体的に説明や例が拡充されています。おそらくこのリビジョンはR0の後に提出されたCWG Issue2538とNBコメントを受けての更新です。
この提案では、属性の無視について次の3つの観点から決定が必要だとして、それぞれにオプションを提示しています
- 実装が標準属性を構文的に無視できるかを明確にする
- 標準属性を構文的に無視できないことを明確にする
- R0およびCWGの推奨
- 標準属性を構文的に無視できることを規定する
- 引数などは構文チェックされず、無視される属性内から参照されるエンティティはODR-usedではない
- 標準属性が条件付きでサポートされないことを明確化する
- 特定の標準属性を実装しない場合は文書化し、使用されたときは警告する
- 何もしない
- 標準属性を構文的に無視できないことを明確にする
- 標準属性が意味的に無視できるという時の意味を明確にする
- 標準属性が意味的に無視できることを規定し、これが正確に何を意味するかを標準で指定する
- 代わりに、これを別の新しいStanding Documentで指定する
- 何もしない
- 実装が無視する属性に対する
__has_cpp_attributeの動作を明確にする
11月のkona会議でNBコメントに関連してこれの選択に関する投票が行われたところ、1-1にコンセンサスが得られて採択された一方、2と3はどちらにもコンセンサスが得られませんでした。
CWG2538の採択によって、標準属性の無視とはその意味的な効果のみで属性の構文を無視することを意味しない、となったわけですが、投票に当たってはコンパイラ実装者が実装できないとして強く反対し続けていたようです。
- GB-055 9.12.1p6 [dcl.attr.grammar] Ignoring standard attributes
- CWG Issue 2538. Can standard attributes be syntactically ignored?
- CWG2538 Can standard attributes be syntactically ignored?
- P2552 進行状況
P2559R1 Plan for Concurrency Technical Specification Version 2
Concurrency TS v2発効に向けた作業計画書。
以前の記事を参照
このリビジョンでの変更は、ハザードポインタ(P1121R3)とRCU(P1122R4)がすでにConcurrency TS v2に採択されたことを反映した事です。
P2564R1 consteval needs to propagate up
↓
P2564R2 consteval needs to propagate up
↓
P2564R3 consteval needs to propagate up
consteval関数をconstexpr関数の中で呼び出すことができない問題を軽減する提案。
以前の記事を参照
R1での変更は、提案する文言とサンプルの追加です。
R2での変更は、集成体初期化に関する文言を追加したことです。
R3(このリビジョン)での変更は、機能テストマクロを追加したことです。
この提案は11月のKona会議でC++23WDへの導入が決定しています。
P2570R1 Contract predicates that are not predicates
コントラクト注釈に指定された条件式が副作用を持つ場合にどうするかについて、議論をまとめた文書。
以前の記事を参照
このリビジョンでの変更は
- 議論の範囲を拡張し、冪等性などの契約条件式の他のプロパティを含めた
- 契約条件式の実行時評価から、契約注釈に基づく静的解析に議論をシフト
- P2680R0で示唆された解決策に対処
- 純粋な契約条件とそうではないものが共存できるソリューションについて解説を追記
- N2956(
[[unsequenced]])が契約条件を制限するのに役立つ可能性についての議論を追加 - 契約条件式で標準ライブラリ機能をどの程度使用できるかを判断するための基準について説明を追記
などです。
P2588R2 Relax std::barrier phase completion step guarantees
std::barrierのバリアフェーズ完了時処理が、同じバリアで同期する任意のスレッドから起動できるようにする提案。
以前の記事を参照
- P2588R0 Relax std::barrier phase completion step guarantees - WG21月次提案文書を眺める(2022年05月)
- P2588R1 Relax std::barrier phase completion step guarantees - WG21月次提案文書を眺める(2022年09月)
このリビジョンでの変更は、バリアの完了関数が新しいスレッドで(スレッドを起動して)行われる事を許可しないようにしたことです。
- DE-135 33.9.3 [thread.barrier] Relax std::barrier phase completion guarantees
- US 63-131 33.9.3.3 [thread.barrier.class] Thread for running completion function
- P2588 進行状況
P2589R1 static operator[]
添え字演算子(operator[])を静的メンバ関数として定義できるようにする提案。
以前の記事を参照
このリビジョンでの変更は、機能テストマクロとして__cpp_multidimensional_subscriptの値を増やしたしたことです。
この提案は11月のKona会議でC++23WDへの導入が決定しています。
P2602R2 Poison Pills are Too Toxic
標準ライブラリから、Poison Pillと呼ばれるオーバーロードを削除する提案。
以前の記事を参照
- P2602R0 Poison Pills are Too Toxic - WG21月次提案文書を眺める(2022年06月)
- P2602R1 Poison Pills are Too Toxic - WG21月次提案文書を眺める(2022年07月)
このリビジョンでの変更は、提案する文言の表現を変更した事です。
この提案は11月のKona会議でC++23WDへの導入が決定しています。
P2614R2 Deprecate numeric_limits::has_denorm
std::numeric_limits::has_denorm関連の定数を非推奨化する提案。
以前の記事を参照
- P2614R0 Deprecate
numeric_limits::has_denorm- WG21月次提案文書を眺める(2022年07月) - P2614R1 Deprecate
numeric_limits::has_denorm- WG21月次提案文書を眺める(2022年10月)
このリビジョンでの変更はよくわかりません。
この提案はすでにC++23に向けてLWGの承認を得ていますが、LEWGでの作業が残っているようです。
P2615R1 Meaningful exports
無意味なexportを行えないようにする提案。
以前の記事を参照
このリビジョンでの変更は、EWGの要求に従って特定のexport(主に推論補助)を許可するように調整したことです。
P2616R1 Making std::atomic notification/wait operations usable in more situations
↓
P2616R2 Making std::atomic notification/wait operations usable in more situations
std::atomicのnotify_one()とwait()操作を使いづらくしている問題を解消する提案。
以前の記事を参照
R1での変更は、R0で提案していた2つの解決策に加えて3つ目の解決案を追加、R0のオプション2の制限に関するフィードバックを反映。
このリビジョン(R2)での変更は
- SG1の要請によりオプション3のみを提案に含めるようにした
- abstractを書き換え
- 設計ディスカッションを追加
- 提案する文言を追加
- 提案の対象を
std::atomic_flagに拡大
R1で追加されたOption3は、std::atomicオブジェクトから通知に使用できるトークンを取得できるようにするものです。このトークンは、アトミックオブジェクトが破棄された後でも、元のアトミックオブジェクトを待機しているエンティティに通知を行うために使用できます。
namespace std { // 提案するトークン型 template<typename T> class atomic_notify_token; template<typename T> class atomic { public: // Existing members... // 提案するトークンを取得する関数 atomic_notify_token<T> get_notify_token() noexcept; }; template<typename T> class atomic_ref { public: // Existing members... atomic_notify_token<T> get_notify_token() noexcept; }; // 提案するトークン型定義 template<typename T> class atomic_notify_token { public: // Copyable atomic_notify_token(const atomic_notify_token&) noxcept = default; atomic_notify_token& operator=(const atomic_notify_token&) noxcept = default; // Perform notifications void notify_one() const noexcept; void notify_all() const noexcept; private: // exposition-only friend class atomic<T>; explicit atomic_notify_token(std::uintptr_t p) noexcept : address(p) {} std::uintptr_t address; }; }
この背後にあるアイデアは、アトミックオブジェクトが破棄される可能性がある場合に、未定義動作を起こす可能性のある事を回避して待機中のスレッドに通知を行えるだけの情報をトークンが保持できることです。
そして、std::atomic, std::atomic_ref, std::atomic_flagにある通知関数を非推奨化します。
この方法では、前回の記事のサンプルコードは次のようになります
#include <atomic> #include <thread> int main() { { // 同期用アトミックオブジェクト std::atomic<bool> sync = false; std::thread{[&sync]{ // 破棄される前にトークンを取得 auto token = sync.get_notify_token(); // 値をtrueに更新 sync.store(true); // 通知 token.notify_one(); }}.detach(); // 値が更新(trueになる)されるまで待機 sync.wait(false); } }
おそらくSG1の選択はこのOption3のようですが、まだ明確に解決策が確定したわけではありません。
P2640R2 Modules: Inner-scope Namespace Entities: Exported or Not?
モジュール内で名前空間スコープに直接宣言を持たずに導入されるものについて、そのリンケージをどうするかを規定しようとする提案。
以前の記事を参照
- P2640R0 Modules: Inner-scope Namespace Entities: Exported or Not? - WG21月次提案文書を眺める(2022年09月)
- P2640R1 Modules: Inner-scope Namespace Entities: Exported or Not? - WG21月次提案文書を眺める(2022年10月)
このリビジョン(実質R1)での変更は
- シンボルレベルの影響に関する説明を追加
- 弱い所有権による実装を削除する提案を追加
などです。
この問題を引き起こしている物体についてリンケージを知る必要性があるのは、弱い所有権モデルを許可するためであるようです。強い所有権モデルであれば、外部リンケージとモジュールリンケージの区別をなくすことができるため、そのリンケージを知る必要性がなくなるためです。
ただし、その場合でも名前解決についての問題は解決されないようです。
P2644R1 Final Fix of Broken Range based for Loop Rev 1
範囲for文の13年間放置されているバグを修正する提案。
以前の記事を参照
このリビジョンでの変更は、CWGのフィードバックを受けて提案する文言を改善し例を追加したことです。
この提案は11月のKona会議でC++23WDへの導入が決定しています。
P2647R1 Permitting static constexpr variables in constexpr functions
関数スコープのstatic constexpr変数をconstexpr関数内で使用可能にする提案。
以前の記事を参照
このリビジョンでの変更は、提案する文言の改善、例の追加、機能テストマクロの追加などです。
この提案は11月のKona会議でC++23WDへの導入が決定しています。
P2649R0 2022-10 Library Evolution Poll Outcomes
2022年10月に行われたLEWGにおける全体投票の結果。
次の提案が投票にかけられ、一部の投票に当たって寄せられた賛否のコメントが記載されています。
- C++23
- C++26
- P2631R0 Publish The Library Fundamentals v3 Technical Specification Now
- P1083R6 resource_adaptor
- P2587R3 to_string Or Not to_string
- P2495R1 Interfacing stringstreams With string_view
- P2510R3 Formatting Pointers
- P2572R0 std::format Fill Character Allowances
- P2511R2 Beyond operator(): NTTP Callables In Type-Erased Call Wrappers
- P2592R2 Hashing Support For chrono Value Classes
- P0543R2 Saturation Arithmetic
- P0870R4 is_convertible_without_narrowing
- P2614R1 Deprecate numeric_limits::has_denorm
このうち、P2511R2がコンセンサスを得られず、P2614R1はターゲットの設定を間違えていたためやり直しになったようです。
P2650R0 2022-11 Library Evolution Polls
2022年11月に行われるLEWG全体投票の予定表。
次の提案(およびNBコメント)が投票にかけられます。
- C++23
- P2164R8 views::enumerate
- P2711R1 Making Multi-Param Constructors Of Views Explicit
- P2655R1 common_reference_t Of reference_wrapper Should Be A Reference Type
- FR-015-026 Remove cbegin/cend From Spans And Views
- FR-013-020 Replace repeat With cycle
- P2693R0 Formatting thread::id And stacktrace
- LWG3806 Should Concept formattable<T, charT> Default To char?
- FR-003-010 Formatting Of Ranges Of tuple-like Objects
- P2588R2 Relax barrier Phase Completion Step Guarantees
- US-43-104 subspan Type Confusion
- FR-002-015 Return A span From strides
- GB-087 start_lifetime_as Is Broken And Inconsistent For Arrays
- P2679R1 Fixing start_lifetime_as For Arrays
- P2674R1 is_implicit_lifetime
- US-30-072 Predefined Macros From The C Library
- GB-080 Sync intmax_t And uintmax_t With C2x
- P2652R0 Disallow User Specialization Of allocator_traits
- P2614R1 Deprecate numeric_limits::has_denorm
- GB-081 Deprecate Contents Of <stdalign.h>
- GB-082 Deprecate Contents Of <stdbool.h>
- GB-084 Deprecate errc Constants Related To UNIX STREAMS
- GB-121 Remove voidify
- C++26
NBコメントの投票は否決するか?を問うようで、コンセンサスが得られた場合にそのNBコメントをリジェクトする(受け入れない)ことになるようです。
P2652R1 Disallow user specialization of allocator_traits
std::allocator_traitsのユーザーによる特殊化を禁止する提案。
以前の記事を参照
このリビジョンでの変更は、前回提案していた2つの解決のうちの1つ目(std::allocator_traitsのユーザーによる特殊化を禁止)がLEWGで好まれたことを受けて2つ目の解決策を削除したこととallocation_result(), allocate_at_least()のサイズパラメータの型をsize_typeを使うように修正したこと(この提案とは直接関係ない)です。
この提案はすでに1つ目の解決策がLWGによって承認されており、このリビジョンでの変更をレビューした後C++23に向けて全体投票に進みます。
P2653R1 Update Annex E based on Unicode 15.0 UAX 31 Steve Downey
ユニコードのUAX#31への準拠の文面を更新する提案。
以前の記事を参照
このリビジョンでの変更、提案の動機が追記されたことなどです。
この提案はCWG Issue 2636としてすでにWDにマージされています。
P2655R1 common_reference_t of reference_wrapper Should Be a Reference Type
std::reference_wrapper<T>とT&の間のcommon_referenceがT&になるようにする提案。
以前の記事を参照
このリビジョンでの変更は、結果がstd::reference_wrapper<T>ではなくT&となる理由を追記したこと、std::reference_wrapper<T>のTがconst/volatileの場合に対応したこと、派生クラスから基底クラスの変換をサポートしたことなどです。
この提案はどうやらC++23に向けて進行しているようです。
P2657R1 C++ is the next C++
C++言語機能として静的解析を組み込む提案。
以前の記事を参照
このリビジョンでの変更は
static_analysis属性における解析器の種類の指定をinclusions/exclusionsによって行うように変更no_unsafe_castsにstd::reinterpret_pointer_castとstd::const_pointer_castの使用(の禁止)を追加use_ranges解析器を追加std::findなどに対してstd::ranges::findの使用を促すもの
use_function_refをsaferのサブ解析器に移動- Tooling Opportunitiesセクションを追加
- CIでの利用の可能性について
- Reserved Behaviorセクションを追加
- 静的解析の適用範囲について(現在はモジュール内の各翻訳単位ごと)
- Frequently Asked Questionsセクションの整理
- How do we configure future analyzersセクションの削除
- P2687R0との関連に関するセクションを追加
などです。
このリビジョンでは、静的解析器の有効化の指定方法が変わっています
// プライマリモジュールインターフェース単位で有効化、自動的にこのモジュール内全域に適用 export module some_module_name [[static_analysis(inclusions{"safer"}, exclusions{"", ""})]]; // もしくは、実装単位で有効化 module some_module_name [[static_analysis(inclusions{"modern"}, exclusions{"use_ranges"})]];
[[static_analysis(...)]]の中で、inclusions{"analyzer", ...}のようにして有効にする解析器を指定し、その後にカンマで区切ってexclusions{"analyzer", ...}のようにして有効化した解析器に含まれるサブ解析器から無効化するものを指定します。
P2658R1 temporary storage class specifiers
一時オブジェクトのための記憶域指定を追加する提案。
以前の記事を参照
このリビジョンでの変更は
- Value Categoriesセクションの追加
- 寿命延長されたオブジェクトの値カテゴリについて
- Automatic or Configurable Default or Exceptional Rules
- P2623R0との選択や適用範囲などについて
- Tooling Opportunitiesセクションを追加
などです。
P2659R1 A Proposal to Publish a Technical Specification for Contracts
契約プログラミング機能に関するTechnical Specificationを発効する提案。
以前の記事を参照
このリビジョンでの変更は
- overviewセクションの追加
- より詳細な背景を個別のセクションとして追加
- モチベーションを拡充し明確化
- 寄せられた疑問に対する回答のセクションを追加
- TSの進行スケージュールに関するセクションを追加
- conclusionセクションの追加
- P2000R3で提起された問題に対するappendixを追加
などです。
P2664R0 Proposal to extend std::simd with permutation API
Parallelism TS v2にあるstd::simdに、permute操作のサポートを追加する提案。
SIMDにおけるpermute命令とは、SIMDレジスタ内で要素を並び替える命令の1つです。ある計算の際に効率的なデータの並びとその後の別の計算の際に効率的なデータの並びが異なる場合など、SIMDレジスタ内にデータを載せたまま並べ替えが必要になることはよくあり、その際にpermute命令を使用できます。
現在のstd::simdにはこのような操作を直接的に行うAPIがなく、要素の抽出(extract())やstd::simd値の分割(split())と、連結(concat())や挿入(insert())を組み合わせて行うしかありません。これは複雑であるとともにコンパイル時の操作となってしまうため動的な並べ替えを行うことができません。また、直接的なAPIが提供されていないことによって、操作とSIMD命令を1対1でマッピングすることが難しくなります。
この提案は、ハードウェアのSIMD permute命令に対応するstd::simd値の要素の並べ替えを行う関数を追加しようとするものです。
この提案ではpermute操作を行うための3種類のAPIを提案しています
- コンパイル時にインデックス計算を行う
- 並べ替えパターンを生成する関数を受け入れることで、インデックス計算をコンパイラに任せる
- 別の
std::simd値による実行時インデックス指定 - SIMDマスクによって、入力の要素を出力に使用するかを決定する
int main() { // 入力例(この提案のAPIは入力のstd::simd型に依存しない) std::fixed_size_simd<float, 10> values = ...; // 1. コンパイル時のインデックス計算 { // 出力のインデックスは入力インデックス[0, 1, 2…)を用いて[0 0 2 2 4 4…)のようにマップされる const auto dupEvenIndex = [](size_t idx) -> size_t { return (idx / 2) * 2; }; const auto de = std::permute(values, dupEvenIndex); // deは入力と同じ要素数で同じ要素型 // 出力サイズの明示的な指定 // stride3で4つの値を生成(つまり、出力配列は入力インデックスによって[0, 3, 6, 9]のようにマップされる) const auto stride3 = std::permute<4>(values, [](size_t idx) -> size_t { return idx * 3; }); // stride3は4要素で同じ要素型 } // 2. 実行時インデックス指定 { // 実行時インデックス std::fixed_size_simd<unsigned, 8> indexes = ...; // indexesの先頭から、そのインデックスに対応する入力(values)要素を出力にマップする const auto result = std::permute(values, indexes); // resultは8要素(インデックス配列と同じ要素数)で入力と同じ要素型 } { // SIMDマスク std::fixed_size_simd<unsigned, 10> mask = ...; // 要素を半分に圧縮する // maskによって入力から出力に使用する要素をフィルタする const auto result = std::compress(values, mask); // resultは入力の半分の要素数で入力と同じ要素型 } }
これらの関数は、実行環境(CPU)の直接的なSIMD命令によって効率的に処理されることが期待できます。
また、提案では、これらのAPIを拡張して一般のメモリに対するスキャッタ/ギャザー操作を行うAPIとすることもできるとしています。
- AVXの倍精度実数シャッフル系命令チートシート - Qiita
- Day 7 : SIMD化 - 一週間でなれる!スパコンプログラマ
- P2638R0 Intel's response to P1915R0 for std::simd parallelism in TS 2 - WG21月次提案文書を眺める(2022年09月)
- P2664 進行状況
P2674R1 A trait for implicit lifetime types
implicit lifetime typeを識別するための型特性、is_implicit_lifetime<T>の提案。
以前の記事を参照
このリビジョンでの変更は、事前条件の文言を修正したことと機能テストマクロを追加したことです。
P2679R1 Fixing std::start_lifetime_as and std::start_lifetime_as_array
std::start_lifetime_asの既存機能等との非一貫性を正す提案。
以前の記事を参照
このリビジョンでは、R0で提案していた大掛かりなAPIの変更がリジェクトされたため、それを削除しました。代わりに、別のNBコメントで指摘された第二引数n == 0のケースを未定義ではなく効果なしになるように修正することを提案しています。
void processData(unsigned char* dataFromNetwork, size_t numObjectsToRead) { Data* data = std::start_lifetime_as_array<Data>(dataFromNetwork, numObjectsToRead); // numObjectsToReadが0でもUBにならない for (size_t i = 0; i < numObjectsToRead; ++i) processObject(data[i]); }
また、以前の提案で問題視していたように、std::start_lifetime_asは単一のオブジェクト型もしくは静的な配列型(要素数が既知の配列型)のためのもので、そこに要素数不明な配列型を渡すのは間違った使用法です。ただし、現在それはエラーにはなりません。このリビジョンではこれをエラーにすることも提案しています。
unsigned char* buf = ...; auto* p1 = std::start_lifetime_as<int[]>(buf); // 現在はUB、この提案ではill-formed
- CA-086 20.2.6p5 [obj.lifetime] Allow 0 for the second parameter to start_lifetime_as_array
- P2679 進行状況
P2681R0 More Simple Statistics
標準ライブラリにいくつかの統計関数を追加する提案。
この提案は、P1708R6をベースとして、同様の設計で次の5つの統計計算関数を追加しようとするものです
- 一変量統計
- パーセンタイル
- 最頻値
- 二変量統計
- 共分散
- 相関係数
- 線形回帰
これらのものにはP1708と同様にrangeを入力としてその要素から統計量を計算する関数と、各値をオンラインで入力していき統計量を計算するaccumulatorオブジェクト(クラス)の2つのAPIが用意されています。
#include <stats> #include <vector> #include <iostream> int main() { std::vector vec = {1, 1, 2, 3, 4, 4, 4, 5}; // 最頻値の計算(フリー関数) auto mode = std::mode_of_sorted(vec); // mode == 4 // 相関係数の計算(accumulatorオブジェクト) std::correlation_accumulator acc{}; // データ入力 acc(50, 40); acc(60, 70); acc(70, 90); acc(80, 60); acc(90, 100); // 計算結果の取得 auto corr = acc.value(); // corr == 0.73 }
P2693R0 Formatting thread::id and stacktrace
std::thread::idとstd::stacktraceをstd::format()及びstd::print()で出力できるようにする提案。
標準ライブラリ型のstd::format対応はP1636R2で提案され、LEWGのレビューを通過しLWGにおけるレビューで改訂が必要とされましたが、どうやら著者の方と連絡がつかなくなり進展が望めなくなっています(提出されたのは2019年でした)。
C++23 CDへのNBコメントにおいて、std::thread::idのstd::format対応が推奨され、この提案はそれを受けてそのための文言を提供するものです。
NBコメントでstd::thread::idだけが特別視されたのはデバッグ目的だったようで、同様にデバッグに有用なstd::basic_stacktraceとstd::stacktrace_entryも含めることになったようです。
一方で、P1636R2で提案されていた他の物(std::bitsetやstd::unique_ptrなど)は含まれていません。
// この提案が採択されたC++23以降の例 import std: int main() { // スレッドIDの出力 std::print("This thread id : {}", std::this_thread::get_id()); auto st = std::stacktrace::current(); // スタックトレース全体の出力 std::print("Entire stack trace\n{}", st); // 1フレームだけ出力 std::print("Top of stack trace\n{}", st[0]); }
これはC++23に対するNBコメントを受けてのものなので、C++23をターゲットとして作業されています。
P2695R0 A proposed plan for contracts in C++
C++ Contracts(契約プログラミング)のC++26導入へ向けた予定表。
計画によれば、2023年中に現在のMVPと呼ばれる機能セットの設計を完了し、2024年中でEWG/CWGによるレビューを行い、2025年初頭にC++26 WDへマージする、という予定です。ただし、必要に応じてロードマップは修正されるとしています。
この予定表はSG21で採用することに合意が取れており、EWG/CWGの合意が必要かもしれませんが、SG21としてはC++26に向けてContractを進めていくようです。
P2696R0 Introduce Cpp17Swappable as additional convenience requirements
Cpp17Swappableという要件を追加する提案。
現在規格書中で使用されているswappable要件は、型Tの右辺値または左辺値がTの任意の右辺値または左辺値とそれぞれswap可能であること、のように規定されており、Tについてのswappable要件は左辺値と右辺値の両方について値の交換可能性を要求しています。これによって、単に左辺値だけがswap可能であればよい場合に規定を追加で記述しなければならなくなっており、文章の肥大化を招くとともに分かりづらくなっています。
この提案のいうCpp17Swappable要件とは、型Tの左辺値がswappableであること、のような規定で、swappable要件のサブセットになっています。これを用いて、現在単に左辺値のswappableだけが必要なところの規定を書き換えるのがこの提案の目的です。
この提案は意味論の変更を意図するものではなく、規格書の記述の改善を目的としています。
P2697R0 Interfacing bitset with string_view
std::bitsetにstd::string_viewを受け取るコンストラクタを追加する提案。
std::bitsetは、符号なし整数もしくは文字列(std::basic_string、文字列リテラル)から構築することができます。しかし、これはC++11で追加されたインターフェースであるため、std::string_view(std::basic_string_view)を受け取ることができません。
#include <bitset> int main() { std::bitset b0{""}; // ok ✔ std::bitset b1{""sv}; // ng ❌ std::bitset b2{""s}; // ok ✔ }
std::string_viewを渡そうとすると、std::stringに明示的に変換してその一時オブジェクトを渡すか、.data()からconst CharT*を渡すかすることになります。前者は不要な文字列コピーが入ってしまい、後者はnull終端が保証されないため危険となり、どちらも適切な解決策とは言えません。
std::bitsetコンストラクタは入力文字列を変更せずに読み取りだけを行うため、不変な文字列を表すstd:string_viewを渡すことは自然であるはずです。しかし、現在はそのために不要なコピーやバッファオーバーランの危険性が挿入されてしまいます。
この提案は、std::bitsetのコンストラクタに、現在のstd::stringを受け取るコンストラクタをベースにしたstd::string_viewを受け取るコンストラクタを追加することによってこの問題の解決を図るものです。
#include <bitset> int main() { std::bitset b0{""}; // ok ✔ std::bitset b1{""sv}; // ok ✔ std::bitset b2{""s}; // ok ✔ }
P2698R0 Unconditional termination is a serious problem
議論中の契約プログラミング機能において、実行時に契約条件が違反したときに即終了するしかない事の問題を指摘する文書。
現在の契約プログラミング(Contracts)の議論においては、契約条件を実行時にチェックするかしないかについて次の2つの振る舞いを許可する方向で進んでいます。
- No_eval : コンパイラは契約条件の構文的な妥当性をチェックするものの、実行時に条件チェックはされない。
- Eval_and_abort : 契約条件は実行時にチェックされ、破られたら(
falseを返したら)プログラムは終了する。
契約条件を実行時にチェックして、それが破られていることが分かった時にどうするか?という所はC++20の契約プログラミング機能においても議論の的となった点で、現在のところはこの2点の最小の振る舞いを先行して導入することを目指しています。
ここで問題となるのは、Eval_and_abortモードにおいて契約条件の違反による終了をハンドルしたりキャンセルする方法が無い所です。契約を実行時にチェックするためにはこのモードしかないため、無条件に終了することが許されないようなプログラムにおいては契約機能を使用することができなくなります。
例えば、標準ライブラリで契約機能を使ったアノテーションが行われていると、無条件で終了できないプログラムにおいては標準ライブラリを使用することができなくなります。
そのようなプログラムは得てして信頼性や性能に厳しい要件があり、本来契約プログラミング機能の恩恵を最も受けることができるはずのプログラムです。
では、そのようなプログラムにおいては契約の実行時チェックをオフにすれば良いかというと、それだけの問題ではありません。契約アノテーションの主な目的は関数の入出力で満たされるべき不変条件の記述及びチェックを、テストコードや文書などから本番のコードへより認識しやすい形で移管することにあります。それらの契約アノテーションを、本番環境での実行時チェックを目的とするものと、デバッグや静的解析のためのものとに分離して管理することはスケールしません。
さらには、終了を判別できる必要性もあります。すなわち、プログラムが終了したときにそれが契約違反によるものなのか、別の例外によるものなのか、はたまた予期しないソフトやハードのエラーによるものなのか、が判別できる必要があります。現在最も広く使われていると思われる契約システムのAda SPARKにおいては、実行時の契約違反を報告するために専用の例外を使用します。実行時に行われるテストを契約アノテーションとして持つことは、通常のロジックとは区別され、静的解析器が利用できることを意味します。
契約違反のハンドルの理想は、起きたプログラムとは別のシステムで行えることですが、そのようなシステムがいつも存在するとは限りません。OSカーネルや金融アプリケーションや人の命に係わるプログラムなど、契約違反も含めたエラーに遭遇しても何らかの方法で処理を進めなければなりません。
そのような問題の管理を終了ハンドラ(違反ハンドラ)に押し付けてしまうと、終了ハンドラが様々な種類の終了を処理することになり、終了ハンドラに必要なシンプルさが損なわれます。
P2521R2の設計は最小の実行可能(minimally viable)を謳われていますが、その最小にはこのような重要なユースケースが含まれていません。P2521R2は最小のものであり議論が必要なものについては後から追加できる、としていますがそれは現実的ではなく、実際には改善の動機が少なくなり拡張を試みる提案が失敗するか、何年も論争が続く可能性があります。
契約違反後にすぐに終了しないためのメカニズムは、最低限許容される契約設計の一部です。
これらの懸念と主張から、この提案では契約違反が起きた際にすぐ終了せずに何らかの作業を行うために、3つ目の動作モードを追加することを提案しています。
- Eval_and_throw : 契約条件は実行時にチェックされ、破られたら(
falseを返したら)例外を投げる
これは、違反が起きた後に元の処理を継続したいと言っているわけではなく、その議論を蒸し返すものでもありません。また、実行時に契約違反を処理する方法を変更しようとするものでもありません。
P2700R0 Questions on P2680 “Contracts for C++: Prioritizing Safety”
P2680R0で提唱されている契約条件の副作用の扱いについて、幾つかの疑問点を提出する文書。
P2680R0については以前の記事を参照。
P2680R0では、C++契約機能は安全性を第一として設計されるべきという方針を表明するとともに、そのための施策の一環として契約条件における副作用の振る舞いモデルを定数式における関数実行と同じにすることを提案しています。すなわち、契約条件式の処理内の副作用はその条件式の実行内部に留まっている限り許可されます(グローバル状態の変更は許可されない)。
さらには、SG21(契約に関するStudy Group)の会合でP2680R0の著者の方は契約機能はUBフリー(未定義動作と無縁)であるべき、という主張もしたようです。
この提案は、更なる議論の促進のために、P2680R0に関してSG21メンバーが持っている疑問をまとめたものです。意図としてはP2680R0の有用性や実現可能性を明確にするとともに、最終的な契約条件における副作用の扱いの決定に資するものにすることを目的にしています。したがって、P2680R0を否定したり置き換えたりするものではありません。
疑問は大きく次の5つのトピックからなります
- 契約条件内での標準ライブラリ機能の使用について
- 契約条件内で使用できる標準ライブラリ機能はどれか?(再起的な契約を考慮しないとして)次の例はコンパイルできるか?
-
void test(const std::vector<int> &v) [[ pre : v.begin() < v.end() ]];
-
- 1の例をコンパイルするために、
std::vectorの規定をどのように変更すればよいか? - 1の例がコンパイルできる場合、
std::vector::begin()がメモリ割り当てを引き起こすことがわかっているMSVC STLのデバッグ版でもコンパイルできるか?- P2680の枠組みの元ではメモリ確保は契約条件内では許可されないので、この呼び出しはどのようなメカニズムで許可されるのか?
- 1の例がコンパイルされない場合、契約条件の一部としてメモリを割り当てたり副作用を引き起こす
std::vector(今日のMSVC STLのような)を作成するにはどうすればいいか?- 別のビルドモードが必要な場合、そのようなモードは提案されているか?
- 次の例は許可されるか?(STLアルゴリズム、ユーザー提供の関数オブジェクトとイテレータの間接参照を含んでいる)
-
void test(auto begin, auto end) [[ pre: std::all_of(begin, end, is_cute{}) ]];
-
- 契約条件内で使用できる標準ライブラリ機能はどれか?(再起的な契約を考慮しないとして)次の例はコンパイルできるか?
- サードパーティライブラリ機能を契約条件内で使用した場合の問題点
- Q1.1がコンパイル可能であると仮定した時、同様の動作をするサードパーティライブラリを作成するにはどうすればいいか?
- サードパーティライブラリ内の関数でログ出力をする場合に、その関数は契約条件に使用できるか?
- できない場合、エラーはどのように報告されるか?
- また、どうすればそれが可能になるか?追加の注釈が必要なのか?そのような注釈はどのようなものでどのように機能するか?
- 関数の定義が他の翻訳単位にある場合、その関数を契約条件に使用できるか?
- できない場合、エラーはどのように報告されるか?
- また、どうすればそれが可能になるか?追加の注釈が必要なのか?そのような注釈はどのようなものでどのように機能するか?
- 関数の定義が動的ライブラリにある場合、その関数を契約条件に使用できるか?
- できない場合、エラーはどのように報告されるか?
- また、どうすればそれが可能になるか?追加の注釈が必要なのか?そのような注釈はどのようなものでどのように機能するか?
- 契約条件で、既存のサードパーティライブラリが提供する状態検証関数(ソースコードがないか、異なる言語で実装されている)をどのように利用できるか?
- 現在の式の評価ルールと、契約条件における安全な評価のために提案されているルールとの違いについて
- 符号付き整数演算はオーバーフローによるUBを回避するために、言語の他の部分とは異なる動作をするのか?
- もしそうなら、どのように?
- 1の回答がyesの場合、同じ式が契約条件内とその契約がなされている関数内で異なって評価される可能性がある。
- そのような矛盾が発生すると考えるのは正しいか?正しくない場合、なぜか?
- この種類の式の解釈の違いはそれ自体が別の危険性の原因になる可能性があるか?そうではない場合、なぜか?
- P2680の枠組みのもとでUBからwell-definedに変更される動作は何か?その理由は?
- そのようなものそれぞれについて、どのような振る舞いが規定され、それはなぜか?
- 契約条件内の浮動小数点環境はプログラムの他の部分と同じか?
- 契約条件内の浮動小数点演算は、浮動小数点例外を発生させたり
errnoを設定したりできるか? - 5の答えがyesの場合、次のコードはコンパイルできるか?
-
void foo(double x) [[ pre: x/3.0 < 1.0 ]] {...}
-
- 6の答えがyesの場合、浮動小数点環境と
xの組み合わせによってFE_INEXACTが発生する場合、実行時に何が起こるか?
- 符号付き整数演算はオーバーフローによるUBを回避するために、言語の他の部分とは異なる動作をするのか?
- 契約条件内に存在しうるUBのコンパイル時検出に関する詳細
- 一般的な設計目標とその意味
(力尽きたので4以降の詳細は省略)
ぱっと見ただけでもかなり厳しい(が当然の)疑問が並んでいるのがわかります。
P2701R0 Translating Linker Input Files to Module Metadata Files
リンカへの入力ファイルをモジュールメタデータファイルへ変換するためのルールを確立しようとする提案。
この提案は、P2577R2で提案されているモジュールのメタデータを取得する手順の中で、リンカへの入力ファイルからモジュールメタデータファイルへどのように変換するか、と言う部分の詳細を記述しようとするものです。
P2577の概要については以前の記事を参照
提案されているルールは次のようなものです
- シンボリックリンクを解決しない
- リンカへの入力ファイルはその名前を使用する
- ビルドシステムはモジュールのメタデータファイルを探す前にライブラリファイルの実パスを解決しようとするべきではない
- 同じディレクトリ
- ディレクトリエントリの名前(ファイル名)の変換
そして、3の結果として取得されたメタデータファイル名の集合を順番(ISA種別などによる)に探索することで、モジュールメタデータファイルを発見します。
この提案ではさらに、既存のビルドシステムがこの変換を個別に実装しなくても良いように、C++のツールチェーン実装の1つとして次のものを提供することを推奨しています
- リンカ引数辺を実装の使用に応じて関連するメタデータファイルへ変換する(上記の手順を実行する)ツール
- 生成されるライブラリの実装定義の特性を考慮して、ライブラリのメタデータファイルパスを記述する(配置すべきパスを出力する)ツール
ツールの提供に関しては提案ではなく推奨なので、それほど強い要求ではありません。
P2702R0 Specifying Importable Headers
ヘッダユニットとしてインポート可能なヘッダを識別する仕組みについての提案。
C++20モジュール仕様では、従来のヘッダファイルをヘッダユニットというモジュールの一形態としてimportすることができます。しかし、どのヘッダがインポート可能なのかについては実装定義とされており、現在の実装ではコンパイラオプションなどで明示的に指定したもののみがインポート可能とされているようです。これは必ずしもユーザーが決定できることでも、コンパイラが決定できるものでもありません(ユーザーが指定したものがヘッダユニットとして使用できるかはコンパイラ次第だし、コンパイラがヘッダユニットとして使用可能として認識したものをユーザーが指定できるわけでもない)。
この提案は主に、ビルドシステムとコンパイラの間でどのヘッダがインポート可能なのかの情報を伝達できるようにするために、いくつかの推奨事項を提供するものです。
importと#include間の対称性- あるヘッダが
importと#includeの両方で使用される時、同じヘッダへ意味的にマップすることを実装が保証する
- あるヘッダが
- 同じヘッダを示す代替トークン
- ディレクトリ順序の脆弱性
- 複数のインポートを1回のインポートに統合する
- あるヘッダ名が
#includeされるとき、そのインクルードが別のヘッダユニットまたは名前付きモジュールのimportによって置き換えられることを指定する方法を提供する
- あるヘッダ名が
- 別の翻訳単位内のヘッダユニット
- 依存関係スキャン前のヘッダユニットの識別
#includeからimportへの変更によって翻訳単位の依存関係が変更されうるため、コンパイラは依存関係のスキャンの前にヘッダユニットのリストにアクセスできる必要がある。ただし、使用されていないヘッダユニットのBMIへのコンパイルは不要な作業となりうる。それを回避するために- 実際に使用されているヘッダユニットのみがコンパイルされるように、依存関係スキャン実行前にヘッダユニットのBMIを生成することなくヘッダユニットのリストを指定する方法を提供する
- ビルドシステムは、依存関係スキャン時に全てのヘッダユニットの翻訳フェーズ4までのコンパイルを実行するために必要なプリプロセッサ引数をコンパイラに伝達する
これらのことは全て推奨事項であるため、C++標準に導入されるかは分かりません。もしかしたら、ツール環境の標準化の方で規定されるかもしれません。
P2703R0 C++ Standard Library Ready Issues to be moved in Kona, Nov. 2022
11月に行われたkona会議でWDに適用されたライブラリに対するIssue報告の一覧
- 3118. fpos equality comparison unspecified
- 3594.
inout_ptr— inconsistentrelease()in destructor - 3636.
formatter<T>::formatshould be const-qualified - 3754. Class template
expectedsynopsis contains declarations that do not match the detailed description - 3028. Container requirements tables should distinguish const and non-const variables
- 3177. Limit permission to specialize variable templates to program-defined types
- 3545.
std::pointer_traitsshould be SFINAE-friendly - 3597. Unsigned integer types don't model advanceable
- 3600. Making
istream_iteratorcopy constructor trivial is an ABI break - 3629.
make_error_codeandmake_error_conditionare customization points - 3646.
std::ranges::view_interface::sizereturns a signed type - 3677. Is a cv-qualified pair specially handled in uses-allocator construction?
- 3732.
prepend_rangeandappend_rangecan't be amortized constant time - 3736.
move_iteratormissingdisable_sized_sentinel_forspecialization - 3738. Missing preconditions for
take_viewconstructor - 3743.
ranges::to's reserve may be ill-formed - 3745.
std::atomic_waitand its friends lacknoexcept - 3746.
optional's spaceship withUwith a type derived fromoptionalcauses infinite constraint meta-recursion - 3747.
ranges::uninitialized_copy_n,ranges::uninitialized_move_n, andranges::destroy_nshould usestd::move - 3750. Too many papers bump
__cpp_lib_format - 3751. Missing feature macro for
flat_set - 3755. tuple-for-each can call user-defined
operator, - 3757. What's the effect of
std::forward_like<void>(x)? - 3759.
ranges::rotate_copyshould usestd::move - 3760.
cartesian_product_view::iterator'sparent_is never valid - 3761.
cartesian_product_view::iterator::operator-should pass by reference - 3762.
generator::iterator::operator==should pass by reference - 3764.
reference_wrapper::operator()should propagatenoexcept - 3765.
const_sentinelshould be constrained - 3770.
const_sentinel_tis missing - 3773.
views::zip_transformstill requires F to becopy_constructiblewhen empty pack - 3774.
<flat_set>should include<compare> - 3775. Broken dependencies in the Cpp17Allocator requirements
- 3778.
vector<bool>missing exception specifications - 3781. The exposition-only alias templates cont-key-type and cont-mapped-type should be removed
- 3782. Should
<math.h>declare::lerp? - 3784.
std.compatshould not provide::byteand its friends - 3785.
ranges::tois over-constrained on the destination type being a range - 3788.
jthread::operator=(jthread&&)postconditions are unimplementable under self-assignment - 3792.
__cpp_lib_constexpr_algorithmsshould also be defined in<utility> - 3795. Self-move-assignment of
std::futureandstd::shared_futurehave unimplementable postconditions - 3796. movable-box as member should use default-initialization instead of copy-initialization
- 3798. Rvalue reference and
iterator_category - 3801. cartesian_product_view::iterator::distance-from ignores the size of last underlying range
P2704R0 C++ Standard Library Immediate Issues to be moved in Kona, Nov. 2022
11月に行われたkona会議でWDに適用されたライブラリに対するIssue報告の一覧。こちらはC++23で新規追加されたライブラリ機能に対するものか、NBコメントを受けてのIssue報告です。
- 3515. §[stacktrace.basic.nonmem]:
operator<<should be less templatized - 3569.
join_viewfails to support ranges of ranges with non-default_initializable iterators - 3717.
common_view::endshould improverandom_access_rangecase - 3737.
take_view::sentinelshould provideoperator- - 3753. Clarify entity vs. freestanding entity
- 3766.
view_interface::cbeginis underconstrained - 3814. Add freestanding items requested by NB comments
- 3816.
flat_mapandflat_multimapshould impose sequence container requirements - 3817. Missing preconditions on
forward_listmodifiers - 3818. Exposition-only concepts are not described in library intro
- 3822. Avoiding normalization in
filesystem::weakly_canonical - 3823. Unnecessary precondition for
is_aggregate - 3824. Number of bind placeholders is underspecified
- 3826. Redundant specification [for overload of yield_value]
P2705R0 C++ Library Fundamentals TS Issues to be moved in Kona, Nov. 2022
Library Fundamentals TS v2に対する解決されたIssue報告の一覧
- 3136. [fund.ts.v3] LFTSv3 awkward wording in propagate_const requirements
- 3411. [fund.ts.v3] Contradictory namespace rules in the Library Fundamentals TS
- 3771. [fund.ts.v3] remove binders typedefs from function
P2706R0 Drafting for US 26-061: Redundant specification for defaulted functions
クラスの特殊メンバ関数のデフォルト実装がいつ定義されるかについての規則の改善。
クラスの特殊メンバ関数のデフォルト実装(明示的なdefault宣言、もしくは暗黙宣言)はodr-usedされた時、もしくは定数評価に必要(needed for constant evaluation)であるときに定義されます。
規格書中でこの規則は特殊メンバ関数のそれぞれの規定毎に現れていましたが、この提案ではそれを一箇所にまとめようとしています。これは振る舞いを変化させるものではなく、規格の記述を単純化するためのものです。
これはNBコメントの解決かつほぼ編集上のものであるので、すでにC++23WDに適用されています。
P2708R0 No Future Fundamentals TSes
↓
P2708R1 No Future Fundamentals TSes
Library Fundamentals TSをこれ以上更新しないようにする提案。
Library Fundamentals TSが必要とされたのは、C++11の策定が8年間遅れた失敗を踏まえてのものであり、将来のライブラリ機能の評価が同じだけ遅れることを回避するためだったようです。
しかし、現在は3年ごとのリリースサイクルが定着し、C++11の時ほど遅延するということは無くなりました。
一方で、Library Fundamentals TSに機能を追加するプロセスはライブラリ機能を直接標準へ導入するプロセスと同じであり、現在のLibrary Fundamentals TSへの機能追加は一般に標準に直接導入するのに比べて優先度が低く見られがちで、それによってLibrary Fundamentals TSは遅延することが多くなっています。
さらに、各SG->LEWG->LWG->標準、という議論とリリースの手順にも慣れてきた現在では、新規提案を直接標準へ導入することをより自信を持って行えています。これはC++11当時の委員会とは異なる文化です。そして、LEWGの総意としては今後はLibrary Fundamentals TSに機能を送らずに直接標準に導入することにしているようです。
この提案は、これらの環境の変化を反映し、これ以上のLibrary Fundamentals TSを計画しないという意図を明確にするために、現在のLibrary Fundamentals TS v3にその意図を記載しようとするものです。
この提案は、すでにLEWGの投票を反対がほぼなく通過し、11月のkona会議で全体承認されています。これによって、Library Fundamentals TSはv3が最後となり、今後のライブラリ機能は直接標準入りを目指すことが基本となります。
P2709R0 Core Language Working Group “ready” Issues for the November, 2022 meeting
11月に行われたkona会議でWDに適用されたコア言語に対するIssue報告の一覧。
- 2392. new-expression size check and constant evaluation
- 2407. Missing entry in Annex C for defaulted comparison operators
- 2410. Implicit calls of immediate functions
- 2428. Deprecating a concept
- 2440. Allocation in core constant expressions
- 2451. promise.unhandled_exception() and final suspend point
- 2508. Restrictions on uses of template parameter names
- 2583. Common initial sequence should consider over-alignment
- 2590. Underlying type should determine size and alignment requirements of an enum
- 2598. Unions should not require a non-static data member of literal type
- 2599. What does initializing a parameter include?
- 2601. Tracking of created and destroyed subobjects
- 2602. consteval defaulted functions
- 2603. Holistic functional equivalence for function templates
- 2604. Attributes for an explicit specialization
- 2605. Implicit-lifetime aggregates
- 2610. Indirect private base classes in aggregates
- 2611. Missing parentheses in expansion of fold-expression could cause syntactic reinterpretation
- 2612. Incorrect comment in example
- 2613. Incomplete definition of resumer
- 2614. Unspecified results for class member access
- 2616. Imprecise restrictions on break and continue
- 2618. Substitution during deduction should exclude exception specifications
- 2619. Kind of initialization for a designated-initializer-list
- 2620. Nonsensical disambiguation rule
- 2622. Compounding types from function and pointer-to-member types
- 2624. Array delete expression with no array cookie
- 2625. Deletion of pointer to out-of-lifetime object
- 2626. Rephrase ones' complement using base-2 representation
- 2627. Bit-fields and narrowing conversions
- 2629. Variables of floating-point type as switch conditions
- 2630. Syntactic specification of class completeness
- 2635. Constrained structured bindings
- 2641. Redundant specification of value category of literals
P2710R0 Core Language Working Group NB comment resolutions for the November, 2022 meeting
11月に行われたkona会議でWDに適用されたコア言語に対するNBコメントに伴うIssue報告の一覧。
- 2242. ODR violation with constant initialization possibly omitted
- 2538. Can standard attributes be syntactically ignored?
- 2615. Missing __has_cpp_attribute(assume)
- 2621. Kind of lookup for using enum declarations
- 2631. Immediate function evaluations in default arguments
- 2636. Update Annex E based on Unicode 15.0 UAX #31
- 2639. new-lines after phase 1
- 2640. Allow more characters in an n-char sequence
- 2642. Inconsistent use of T and C
- 2643. Completing a pointer to array of unknown bound
- 2644. Incorrect comment in example
- 2645. Unused term "default argument promotions"
- 2646. Defaulted special member functions
- 2647. Fix for "needed for constant evaluation"
- 2648. Correspondence of surrogate call function and conversion function
- 2649. Incorrect note about implicit conversion sequence
- 2650. Incorrect example for ill-formed non-type template arguments
- 2651. Conversion function templates and "noexcept"
- 2652. Overbroad definition of STDCPP_BFLOAT16_T
- 2653. Can an explicit object parameter have a default argument?
- 2654. Un-deprecation of compound volatile assignments
P2711R0 Making multi-param (and other converting) constructors of views explicit
↓
P2711R1 Making multi-param constructors of views explicit
<ranges>のviewの2引数以上のコンストラクタをexplicitにするべきかどうかを問う提案。
C++20で追加されたviewのコンストラクタは基本的に1引数のものにだけexplicitが指定されており、それ以外のコンストラクタには指定されていません。一方で、C++23で追加されたviewでは、2引数以上のコンストラクタに対してもexplicitが指定されていることがあり、これによってコピーリスト初期化という形態の初期化(= {...};による初期化)ができなくなっています。
#include <ranges> #include <vector> int main() { std::vector v{42}; // C++20時点 std::ranges::take_view r1 = {v, 1}; // ✅ std::ranges::filter_view r2 = {v, [](int) { return true; }}; // ✅ // C++23 std::ranges::chunk_view r3 = {v, 1}; // ❌ std::ranges::chunk_by_view r4 = {v, [](int, int) { return true; }}; // ❌ std::ranges::chunk_view r5{v, 1}; // ✅ std::ranges::chunk_by_view r6{v, [](int, int) { return true; }}; // ✅ }
しかし、コピーリスト初期化が禁止されているだけならばそれほど有害ではなく、=をなくすだけで初期化を行うことはできます。あるいは、viewはほとんどの場合std::views::filterなどのRangeアダプタオブジェクトを用いて初期化されるものであり、このように直接構築されることは稀なはずです。
この提案は、この点を指摘するLWG Issue 3714を受けて提出されたものです。この問題は確かに一貫性を欠いているのですが、どちらに倒しても(explicitを付けても外しても)それほど有用性はありません。
explicitを付加しない場合 : 推奨されない初期化の書き方(コピーリスト初期化)をサポートしているとみなすことができるexplicitを付加する場合 : 誰でも書けるコードに何か意味のある保護を提供するものでもない(コピーリスト初期化を禁止する効果しかない)
とはいえ一貫性を欠いておりそれに明確な理由や有用性がないのは事実なので、どちらを選ぶかを決定する必要があります。この提案はその決定を促すために提出されたものです。
この提案のR0を受けてのLEWGの投票はどちらにも明確なコンセンサスが得られない微妙な結果でしたが、最終的にはviewの2引数以上のコンストラクタはexplicitをデフォルトとすることで合意されたようです。
R1ではそのためにC++20のviewに対する変更を提案する文言を含んでおり、これはC++20に対する破壊的変更となります(今のところDRではないようですが)。
- LWG Issue 3714. Non-single-argument constructors for range adaptors should not be explicit
- P2711 進行状況
P2712R0 Classification of Contract-Checking Predicates
契約条件内での副作用を禁止するために、契約条件に使用可能な言語のサブセットを作ることを避けるべきという提案。
プログラムに対する契約(Contract)は、自然言語で記述されたものだけでなくライセンスや法的なものなども含みますが、C++契約機能による契約条件の実行時チェックで検証可能な契約とはそのうちのごく一部、プログラム中の個別の関数の個別の不変条件や期待する状態の要求などのみです。
そのような、C++契約機能で検証可能な契約の中にも、コードによる実行時条件として書き下すことができないものがあり、あるいは契約条件の実行そのものが契約を破るような場合もあります。また、ある関数に対しては安全で有効な契約条件が別の関数で使用されたときは未定義動作を引き起こすこともあります。結果的に、契約条件として有用なあらゆる契約条件式は、潜在的にこれらの問題を引き起こす可能性を抱えています。
その安全性の度合いはその契約条件式の持つ副作用の程度によって決まり、副作用はコンテキストによって変化します。したがって、コンパイラはコンパイル時にある契約条件式が安全であるかどうか、いつ安全なのかを決定可能ではありません。
これらのことから、契約条件に副作用がないことは、契約条件の安全性や使用可能性を判断する根拠としては不十分で、不必要です。一方で、この客観的な判断はある程度可能であり、それは実際のプログラミングとそのデバッグなどの実践を通して培われる技術です。
このことを考えると、契約の実行時チェックを可能にするときの主たる関心ごとは、ある契約条件が与えられたコンテキストで安全かどうか、どの程度安全かを理解することです。前述のように、これはコンテキストによって変化するため、言語のルールによって契約条件の安全性を規定することは実質不可能でしょう。
このような理由によりこの提案では、安全な契約条件式の記述だけを許すように見える(特に、副作用を禁止するだけの方向性の)言語のサブセットを規定するよりも、契約条件内で行われることが安全であると思われることを評価する方法の基本的理解を教育することを奨励しています。これによって、契約条件式内でのみ使用可能な安全(に思えるが実効性の低い)言語のサブセットを定義・標準化し、教育することを避けることができます。
P2718R0 Wording for P2644R1 Fix for Range-based for Loop
P2644R1(上の方)の提案する文言だけを抽出した文書。
CWGのガイダンスに基づく修正が適用されていますが、大筋の内容に変更はありません。
P2722R0 Slides: Beyond operator() (P2511R2 presentation)
P2511R2(std::nontype)の解説スライド。
P2511R2については以前の記事を参照
- P2511R0 Beyond operator(): NTTP callables in type-erased call wrappers - WG21月次提案文書を眺める(2022年08月)
- P2511R2 Beyond operator(): NTTP callables in type-erased call wrappers - WG21月次提案文書を眺める(2022年01月)
スライドでは、Java/C#/Rustで関数インターフェースの変換(あるいは型消去)をどのように行うのかやC++が現在それをどう行えるのかを見せた後で、std::nontypeがどのようにこれを改善するのかを説明しています。
しかし、P2511R2はLEWGで合意を得ることができず、追及はストップされています。
P2723R0 Zero-initialize objects of automatic storage duration
自動記憶域期間の変数が初期化されない場合に常にゼロ初期化されるようにする提案。
現在のC++では自動記憶域期間、すなわち関数のローカルスコープの変数の初期化が必ず行われるとは限りません。組み込み型をはじめとするトリビアルにデフォルト構築可能な型では初期化子が提供されない場合にその値は不定となります。初期化されていない(不定の)値を読みだすことは未定義動作です。
int main() { int n; // ok、未初期化 int m = n; // UB、未初期化領域の読み出しは未定義動作 n = 0; // ok int l = n; // ok }
このような未初期化領域の読み取りは、既知のセキュリティ問題の原因となることがあります。この提案は、このようなローカル変数が初期化されない場合に常にゼロ初期化されることを規定することで、未定義動作を規定された振る舞いに変更する事を提案するものです。これによって、セキュリティリスクが低減され、C++をデフォルトでより安全な言語に進歩させます。
static char global[128]; // ゼロ初期化される thread_local int thread_state; // ゼロ初期化される int main() { char buffer[128]; // 現在ゼロ初期化されない、この提案の適用後はゼロ初期化される struct { char type; int payload; } padded; // パディングビットはこの提案の適用後はゼロ初期化される union { char small; int big; } lopsided = '?'; // パディングビットはこの提案の適用後はゼロ初期化される int size = getSize(); char vla[size]; // CのVLAだが、実装でサポートされている場合はこの提案の適用後はゼロ初期化される char *allocated = malloc(128); // ゼロ初期化されない(変更なし) int *new_int = new int; // ゼロ初期化されない(変更なし) char *new_arr = new char[128]; // ゼロ初期化されない(変更なし) }
最後の3つの例のように、この提案はあくまでローカルスコープの未初期化変数だけを対象としています。
提案によれば、この変更によって既知のエクスプロイトの10%を軽減または解消できる、としています。
この提案の内容は既に主要なコンパイラ(clang, GCC, MSVC)においてオプトインのコンパイラフラグによって実装されており、WindowsやAndroid等のOS、Chrome等Webブラウザ等で有効にされているようです。
この提案の影響として最も気になるのはパフォーマンスへの影響です。この提案の意味するところは初期化されないローカル変数は常にゼロフィルされるという事であり、パフォーマンスへの影響は不可避です。
この提案によれば、パフォーマンスへの影響はごくわずか(0.5%未満の低下、一部は1%の高速化)であり、コードサイズへの影響も無視できるレベル(0.5%未満)とのことです。ただし、これはゼロ初期化を最適化するための実装を行ったLLVMによる計測であり、コンパイラの最適化を前提とした数字です(最適化が不十分だった過去の場合は、2.7~5.4%のパフォーマンス低下が計測されたようです)。
また、GCCは不明ですが、MSVCは同種のゼロ初期化関連の最適化を既に実装済みのようです。
ただ、それでもさすがにローカルに大きな配列があるケースなどではパフォーマンスへの影響が無視できないようで、この変更をオプトアウトするための属性[[uninitialized]]も同時に提案しています。これは変数宣言に対して指定する属性で、明示的に付加させることでプログラマーが何が起きるかを意図したうえで使用していることを表明します。
セキュリティリスクの例
提案で紹介されている未初期化メモリの読み出しによるエクスプロイトの例(どちらもC言語かつLinuxにおけるもの)をコピペしておきます
int get_hw_address(struct device *dev, struct user *usr) { unsigned char addr[MAX_ADDR_LEN]; // 未初期化、値を読みだすことでメモリの内容がリークしうる if (!dev->has_address) return -EOPNOTSUPP; dev->get_hw_address(addr); // addrの全部を何かしらの値で埋めない return copy_out(usr, addr, sizeof(addr)); // addrの全要素をコピーする }
ローカル変数が未初期化の場合、その領域には以前にスタック上に配置されていた何らかの値がそのままになっている可能性があります。これによってASLRの情報が漏れる可能性があり、それを利用するとReturn-oriented programming(ROP)を有効化したり、別の情報がどこにあるかを把握したりすることができます。
int queue_manage() { struct async_request *backlog; // ポインタ値は未初期化(非ゼロである可能性がある if (engine->state == IDLE) // 大抵はtrueになる条件 backlog = get_backlog(&engine->queue); // backlogが初期化される if (backlog) backlog->complete(backlog, -EINPROGRESS); // backlogの初期化有無にかかわらずここに来る可能性がある return 0; }
攻撃者は、以前の関数呼び出しを行い同じスタックスロットが再利用されるようにすることで、backlogの値を制御できます。
これそのもの及び似たような問題はC++でも起こりえることで、現在の言語仕様ではそれをどうすることもできません。
- Automatic variable initialization
- [RFC][patch for gcc12][version 1] add -ftrivial-auto-var-init and variable attribute "uninitialized" to gcc
- Join the Windows kernel in wishing farewell to uninitialized plain-old-data structs on the stack
- Solving Uninitialized Stack Memory on Windows - Microsoft Security Response Center
- P2723 進行状況
P2725R0 std::integral_constant Literals
std::integral_constantの値を生成するユーザー定義リテラルの提案。
std::integral_constantはコンパイル時整数値を通常の引数と同じ経路で渡すために使用されます。ただし、型名が長いため表記が冗長になってしまいます。
// submdpsnのstride指定に使用する例 // 実行時の値とコンパイル時の値を同じインターフェースで同時に渡すことができる auto const sir1 = strided_index_range{integral_constant<size_t, 0>{}, integral_constant<size_t, 10>{}, 3}; auto y1 = submdspan(x, sir1); auto const sir2 = compute_index_range(integral_constant<size_t, 0>{}, integral_constant<size_t, 3>{}, integral_constant<size_t, 8>{}, integral_constant<size_t, 5>{}, integral_constant<size_t, 2>{}, integral_constant<size_t, 10>{}); auto y2 = submdspan(x, sir2);
std::mdspan/std::submdspanではその次元と要素数やstrideを指定するために似たような指定を行うため、C++23以降はこのようなコードがより目立つことになるかもしれません。
この提案はこのような構文上の冗長性・ノイズを取り除くために、std::integral_constantの値(オブジェクト)を生成するユーザー定義リテラル(UDL)演算子を標準ライブラリに追加しようとするものです。
この提案によって、先程のコードは次のように改善されます
// UDLを有効化 using namespace std::literals::integal_constant_literals; // strided_index_rangeの改善 auto y = submdspan(x, strided_index_range{0uzic, 10uzic, 3}); // compute_index_rangeの改善 auto const sir = compute_index_range(0ic, 3ic, 8ic, 5ic, 2ic, 10ic); auto y = submdspan(x, sir);
このuzic, icがこの提案によるUDLで、それぞれstd::integral_constant<std::size_t, N>とstd::integral_constant<int, N>を返し、Nにはリテラルが添付された整数値が入れられます。
提案されているUDLは、組み込みの整数リテラルサフィックス(u U l L z Zとその組み合わせ)+icの形で、全部で33個あります。
また、この提案は他のコードの改善の機会となる可能性もあります。例えば、std::tupleに[]を追加することができるかもしれません
using namespace std::literals::integal_constant_literals; // tupleに添字演算子を追加できる auto t = std::tuple<int, std::string>(0, "some text"); t[1ic] = "some different text"; // getのインデックス指定を引数で行う auto t = std::tuple<int, std::string>(0, "some text"); std::get(t, 1ic) = "some different text";
また、UDLを使用する場合は対象数値の符号-がUDL内部からは見えないため、それを反映させるためにstd::integral_constantに単項operator-()を追加しています。
P2726R0 Better std::tuple Indexing
std::integral_constantとそのUDLを利用した、std::tupleの添字演算子([])の提案。
これは、1つ前のP2725R0の最後で紹介していた、std::tupleのインデックスアクセスをicリテラルによって行うインターフェースを提案するものです。
| 現在 | 提案 |
|---|---|
auto t = std::tuple<int, std::string>{42, "how many ..."}; assert(std::get<0>(t) == 42); assert(std::get<1>(t) == "how many..."); |
auto t = std::tuple<int, std::string>{42, "how many ..."}; using namespace std::literals; assert(t[0ic] == 42); // Option 1. assert(std::get(t, 1ic) == "how many..."); // Option 2. |
この提案では、添字演算子を導入する(Option1)か既存のgetを拡張する(Option2)かはオプションとしています。
どちらのオプションにおいても、ネストしたstd::tupleのアクセスのインデックス順序がその順番通りになるという利点も得られます。
int main() { std::tuple<int, std::tuple<double, bool, int>> t; // 現在 std::get<2>(std::get<1>(t)) = 42; // Option1 t[1ic][2ic] = 42; // Option2 std::get(std::get(t, 1ic), 2ic) = 42; }
Option1の実装はBoost.Hanaで実装され数年の実装経験があるようで、P2725R0を前提とすれば、どちらのオプションにしても実装はかなり簡単なはずです。
P2727R0 std::iterator_interface
イテレータを簡単に書くためのヘルパクラスの提案。
STLのイテレータを書くのは難しく、冗長なコードが大量に必要とされます。
たとえば、指定された文字列内の文字を繰り返すイテレータを書くとすると
repeated_chars_iterator first("foo", 3, 0); // 3 is the length of "foo", 0 is this iterator's position. repeated_chars_iterator last("foo", 3, 7); // Same as above, but now the iterator's position is 7. std::string result; std::copy(first, last, std::back_inserter(result)); assert(result == "foofoof");
次のようになります
struct repeated_chars_iterator { using value_type = char; using difference_type = std::ptrdiff_t; using pointer = char const *; using reference = char const; using iterator_category = std::random_access_iterator_tag; constexpr repeated_chars_iterator() : first_(nullptr), size_(0), n_(0) {} constexpr repeated_chars_iterator( char const * first, difference_type size, difference_type n) : first_(first), size_(size), n_(n) {} constexpr reference operator*() const { return first_[n_ % size_]; } constexpr value_type operator[]( difference_type n) const { return first_[(n_ + n) % size_]; } constexpr repeated_chars_iterator & operator++() { ++n_; return *this; } constexpr repeated_chars_iterator operator++(int)noexcept { repeated_chars_iterator retval = *this; ++*this; return retval; } constexpr repeated_chars_iterator & operator+=(difference_type n) { n_ += n; return *this; } constexpr repeated_chars_iterator & operator--() { --n_; return *this; } constexpr repeated_chars_iterator operator--(int)noexcept { repeated_chars_iterator retval = *this; --*this; return retval; } constexpr repeated_chars_iterator & operator-=(difference_type n) { n_ -= n; return *this; } friend constexpr bool operator==( repeated_chars_iterator lhs, repeated_chars_iterator rhs) { return lhs.first_ == rhs.first_ && lhs.n_ == rhs.n_; } friend constexpr bool operator!=( repeated_chars_iterator lhs, repeated_chars_iterator rhs) { return !(lhs == rhs); } friend constexpr bool operator<( repeated_chars_iterator lhs, repeated_chars_iterator rhs) { return lhs.first_ == rhs.first_ && lhs.n_ < rhs.n_; } friend constexpr bool operator<=( repeated_chars_iterator lhs, repeated_chars_iterator rhs) { return lhs == rhs || lhs < rhs; } friend constexpr bool operator>( repeated_chars_iterator lhs, repeated_chars_iterator rhs) { return rhs < lhs; } friend constexpr bool operator>=( repeated_chars_iterator lhs, repeated_chars_iterator rhs) { return lhs <= rhs; } friend constexpr repeated_chars_iterator operator+(repeated_chars_iterator lhs, difference_type rhs) { return lhs += rhs; } friend constexpr repeated_chars_iterator operator+(difference_type lhs, repeated_chars_iterator rhs) { return rhs += lhs; } friend constexpr repeated_chars_iterator operator-(repeated_chars_iterator lhs, difference_type rhs) { return lhs -= rhs; } friend constexpr difference_type operator-( repeated_chars_iterator lhs, repeated_chars_iterator rhs) { return lhs.n_ - rhs.n_; } private: char const * first_; difference_type size_; difference_type n_; };
このイテレータはランダムアクセスイテレータであり、その性質を満たすために必要とする操作を全て記述するとこのように長大なコードを書くことがほとんど避けられません。これらの操作は実際には4つの操作から合成することができますが、このように似たようなコードが画面を埋め尽くしバグが混入しても発見するのを難しくしています(実際に、上記のコードには1箇所意図的にバグが混入されています)。
実際に、この提案のベースとなっているBoostライブラリ(Boost.STLInterfaces)では上記のようなコードを例として使用していたところ、改善前のコードにバグがあることが指摘されました。しかし、それ以前から別のライブラリでその例のイテレータを多用していたにも関わらず、そのバグが実際に問題となることはなかったようです。このことは、イテレータのように非常に大きなAPIではコピペが多用される可能性が高い一方で、APIの個別要素が完全にテストされる可能性は低いことを示唆しています。
また、STLの要件(コンセプト)に準拠することが難しいことから、簡単なイテレータであっても手書きすることは通常避けられます。それによって、カスタムイテレータを使って表現できたはずのアルゴリズムはそれを使用するロジックと混在して直接書かれることになり、複雑化するとともにエラーが発生しやすくなります。イテレータを書くためのコストが低ければ、より多くの場所でカスタムイテレータによって解決できる問題があることに気づける可能性があります。
この提案は、std::ranges::view_interfaceがviewの作成を補助するように、イテレータに対する同様の補助を提供するインターフェースクラスを標準ライブラリに導入しようとするものです。
この提案の機能によって、上記の例は次のように改善されます。
struct repeated_chars_iterator : std::iterator_interface< repeated_chars_iterator, std::random_access_iterator_tag, char, char> { constexpr repeated_chars_iterator() : first_(nullptr), size_(0), n_(0) {} constexpr repeated_chars_iterator(char const * first, difference_type size, difference_type n) : first_(first), size_(size), n_(n) {} constexpr char operator*() const { return first_[n_ % size_]; } constexpr repeated_chars_iterator & operator+=(std::ptrdiff_t i) { n_ += i; return *this; } constexpr auto operator-( repeated_chars_iterator other) const { return n_ - other.n_; } private: char const * first_; difference_type size_; difference_type n_; };
この提案では、std::iterator_interfaceというCRTPによってインターフェースを注入するクラスを導入して、それをイテレータ実装クラスで継承して使うことで多くのインターフェースの実装を自動化します。これによって、イテレータを書く際に必要となるのは* += -(と必要なら==)だけで済むようになり、ボイラープレートコードがかなり削減されます。そして、イテレータを書く際にイテレータの準拠のための実装が簡略化されることで、イテレータで表現したいこと(アルゴリズム)の実装に集中することができるようになります。
- C++20のイテレータ事情 - Qiita
- boostorg/stl_interfaces: A C++14 and later CRTP template for defining iterators
- P2727 進行状況