文書の一覧
全部で46本あります。
- P0009R17 MDSPAN
- P0429R9 A Standard flat_map
- P0447R20 Introduction of std::hive to the standard library
- P0792R10 function_ref: a non-owning reference to a Callable
- P0957R8 Proxy: A Polymorphic Programming Library
- P1018R16 C++ Language Evolution status 🦠 pandemic edition 🦠 2022/02–2022/06
- P1144R6 Object relocation in terms of move plus destroy
- P1222R4 A Standard flat_set
- P1223R5 find_last
- P1642R10 Freestanding Library: Easy [utilities], [ranges], and [iterators]
- P1673R9 A free function linear algebra interface based on the BLAS
- P1689R5 Format for describing dependencies of source files
- P1774R8 Portable assumptions
- P1839R5 Accessing object representations
- P1967R7 #embed - a simple, scannable preprocessor-based resource acquisition method
- P2167R2 Improved Proposed Wording for LWG 2114 (contextually convertible to bool)
- P2278R4 cbegin should always return a constant iterator
- P2490R3 Zero-overhead exception stacktraces
- P2502R2 std::generator: Synchronous Coroutine Generator for Ranges
- P2505R3 Monadic Functions for std::expected
- P2505R4 Monadic Functions for std::expected
- P2513R3 char8_t Compatibility and Portability Fix
- P2551R2 Clarify intent of P1841 numeric traits
- P2562R1 constexpr Stable Sorting
- P2570R0 On side effects in contract annotations
- P2572R0 std::format() fill character allowances
- P2575R0 2022-05 Library Evolution Poll Outcomes
- P2582R1 Wording for class template argument deduction from inherited constructors
- P2590R1 Explicit lifetime management
- P2591R1 Concatenation of strings and string views
- P2594R0 Slides: Allow programmer to control and detect coroutine elision (P2477R2 Presentation))
- P2596R0 Improve std::hive::reshape
- P2598R0 “Changing scope for lambda trailing-return-type” (P2036) should not be a DR
- P2599R0 mdspan::size_type should be index_type
- P2599R1 mdspan::size_type should be index_type
- P2599R2 index_type & size_type in mdspan
- P2600R0 A minimal ADL restriction to avoid ill-formed template instantiation
- P2601R0 To make redundant empty angle brackets optional for class template argument lists
- P2602R0 Poison Pills are Too Toxic
- P2603R0 member function pointer to function pointer
- P2604R0 MDSPAN: rename pointer and contiguous
- P2605R0 SG16: Unicode meeting summaries 2022-01-12 through 2022-06-08
- P2607R0 Let alignas specify minimum alignment
- P2608R0 Allow multiple init-statements
- P2609R0 Relaxing Ranges Just A Smidge
- P2613R0 Add the missing empty to mdspan
- おわり
P0009R17 MDSPAN
多次元配列に対するstd::spanである、mdspanの提案。
以前の記事を参照
- P0009R12 MDSPAN - WG21月次提案文書を眺める(2021年05月)
- P0009R13 MDSPAN - WG21月次提案文書を眺める(2021年10月)
- P0009R14 MDSPAN - WG21月次提案文書を眺める(2021年11月)
- P0009R15 MDSPAN - WG21月次提案文書を眺める(2022年02月)
- P0009R16 MDSPAN - WG21月次提案文書を眺める(2022年03月)
このリビジョンでの変更は、LWGのフィードバックを受けての文言の修正、P2553とP2554の変更をマージしたこと、submdspanを別の提案に分離したことなどです。
- P2553R1 Make mdspan
size_typecontrollable - [C++]WG21月次提案文書を眺める(2022年03月) - P2554R0 C-Array Interoperability of MDSpan - [C++]WG21月次提案文書を眺める(2022年02月)
- P0009 進行状況
P0429R9 A Standard flat_map
キーの検索をstd::map比で高速に行える連想コンテナ、flat_mapの提案。
以前の記事を参照
このリビジョンでの変更はflast_set(P1222)のレビューの関連する部分の文言修正を適用したことのようです。
この提案はこのリビジョンを持ってLWGのレビューを終えており、次の全体会議で投票にかけられる予定です。
P0447R20 Introduction of std::hive to the standard library
要素が削除されない限りそのメモリ位置が安定なコンテナであるstd::hive(旧名std::colony)の提案。
以前の記事を参照
- P0447R11 Introduction of std::colony to the standard library - [C++]WG21月次提案文書を眺める(2020年12月)
- P0447R12 Introduction of std::colony to the standard library - [C++]WG21月次提案文書を眺める(2021年01月)
- P0447R13 Introduction of std::colony to the standard library - [C++]WG21月次提案文書を眺める(2021年04月)
- P0447R14 Introduction of std::colony to the standard library - [C++]WG21月次提案文書を眺める(2021年05月)
- P0447R15 Introduction of std::hive to the standard library - [C++]WG21月次提案文書を眺める(2021年06月)
- P0447R16 Introduction of std::hive to the standard library - [C++]WG21月次提案文書を眺める(2021年09月)
- P0447R17 Introduction of std::hive to the standard library - [C++]WG21月次提案文書を眺める(2021年11月)
- P0447R18 Introduction of std::hive to the standard library - [C++]WG21月次提案文書を眺める(2022年01月)
- P0447R19 Introduction of std::hive to the standard library - [C++]WG21月次提案文書を眺める(2022年02月)
このリビジョンでの変更は、
- コンテナの
== != <=>演算子削除 - 参照実装のライセンス互換性について追記
sort()の計算量の規定を削除rangeを受け取るオーバーロードの追加block_capacity_hard_limits()の追加- FAQの拡充
memory()の削除trim()をtrim_capacity()へ変更- ブロックサイズ制限を受け取る関数がその制限を満たせない場合、例外スローしていたのを未定義動作へ変更
unique()の追加erase()によってイテレータが無効化される条件の明確化get_iterator()がconstポインタを取るように変更advance/distance/next/prevのオーバーロードを削除hive_limitsのコンストラクタをconstexpr化is_active(const_iterator- 時間計算量の修正
trim_capacity(n)オーバーロードの追加hive_limitを取るコンストラクタはデフォルト引数ではなく個別のコンストラクタに分離- いくつかのフィードバックによる文言修正
などです。
P0792R10 function_ref: a non-owning reference to a Callable
Callableを所有しないstd::functionであるstd::function_refの提案。
以前の記事を参照
- P0792R6 function_ref: a non-owning reference to a Callable - [C++]WG21月次提案文書を眺める(2022年01月)
- P0792R8 function_ref: a non-owning reference to a Callable - [C++]WG21月次提案文書を眺める(2022年02月)
- P0792R9 function_ref: a non-owning reference to a Callable - [C++]WG21月次提案文書を眺める(2022年05月)
このリビジョンでの変更は、nontype_t(P2472R3)を受け取るコンストラクタを追加したことです。
この提案は現在、LEWGからLWGへ進むための投票待ちをしています。
- P2472R1 make_function_ref: A More Functional function_ref - [C++]WG21月次提案文書を眺める(2022年02月)
- P2511R0 Beyond operator(): NTTP callables in type-erased call wrappers - [C++]WG21月次提案文書を眺める(2022年01月)
- P0792 進行状況
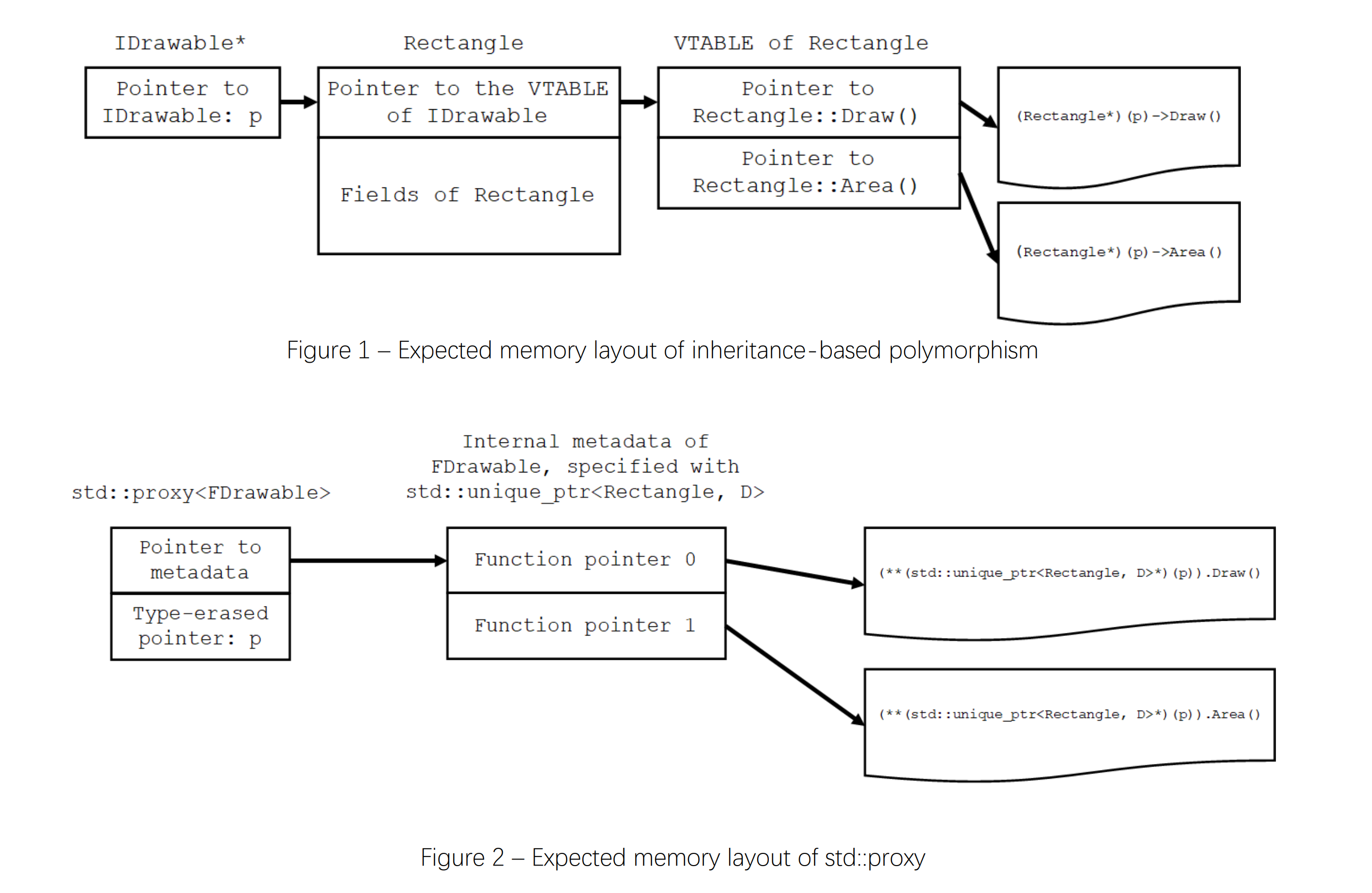
P0957R8 Proxy: A Polymorphic Programming Library
静的な多態的プログラミングのためのユーティリティ、"Proxy"の提案。
以前の記事を参照
- P0957R5 Proxy: A Polymorphic Programming Library - WG21月次提案文書を眺める(2022年02月)
- P0957R6 Proxy: A Polymorphic Programming Library - WG21月次提案文書を眺める(2022年03月)
- P0957R7 Proxy: A Polymorphic Programming Library - WG21月次提案文書を眺める(2022年04月)
このリビジョンでの変更は、機能テストマクロの追加、R5で提案されていた(R6で消された)構文をCPOをサポートする形で復帰、実装へのリンク追加、などです。
残念ながら、この提案はLEWGのレビューで標準化のために時間を使う合意が取れなかったため、これ以上標準化のための作業はされません。
P1018R16 C++ Language Evolution status 🦠 pandemic edition 🦠 2022/02–2022/06
2022年2月から6月にかけてのEWG活動報告書。
投票にかけられた提案は以下のものです
- P2513 char8_t Compatibility and Portability Fixes
- P2460 Relax requirements on wchar_t to match existing practices
- P1854 Conversion to literal encoding should not lead to loss of meaning
どれもEWGでの投票をパスしてCWGに送られています。そのほかにも、いくつかのコア言語へのIssueに関して作業していたようです。
P1144R6 Object relocation in terms of move plus destroy
オブジェクトの再配置(relocation)という操作を定義し、それをサポートするためのユーティリティを整える提案。
再配置(relocation)とは、ムーブと破棄の複合操作のことです。オブジェクトの型Tとポインタsrcとdstがある時、「Tをsrcからdstへ再配置する」とはTのオブジェクトをsrcからdstへムーブ構築した後でsrcを破棄するという意味です。
この提案は、この再配置(relocation)という操作をムーブ・コピー・破棄・swapなどの基本操作のリストに追加するとともに、再配置のnoexceptやトリビアル性の検出を行うユーティリティなどを追加することで、再配置操作をC++の基本操作として全面サポートしようとするものです。
再配置操作において重視されているのは、trivially relocatableという性質で、これは再配置の操作がmemcpyと同等であることを言っています。ほとんどの場合再配置可能な型はtrivially relocatableであり、そのような型には例えば、std::unique_ptr<int>, std::vector<int>, std::stringなどがあります。一方で、std::list<int>のように再配置可能では無い型もあります。再配置不可能な型とは、その実装が自身のポインタ(this)に依存あるいはその不変性を仮定しているような型です。
コピーはオブジェクト表現をその意味論と無関係にコピーし、所有権を移動しません。ムーブはオブジェクトのコピーにおいて所有権を移動しながらコピーを行いますが、ムーブ元のオブジェクトの状態をケアしません(無効なオブジェクトとして扱う)。再配置は、オブジェクト表現のコピーを行うと共に元のオブジェクトを破棄し、その操作が複合していることで所有権移動の問題とムーブ元オブジェクトの問題を回避しています。そのため、memcpyで所有権の移動まで行うことができ、再配置とは言うなればオブジェクトのテレポートです。
ある型がtrivially relocatableであることをコンパイラが認識することで、再配置が必要となる場合にムーブコンストラクタとデストラクタの実行を回避することができるようになり、パフォーマンスの向上につながる可能性があります。これはムーブコンストラクタ及びデストラクタが複雑であるほど効果があり、この提案の内容をclangに実装したところstd::vecttorの一部の操作などで3倍のパフォーマンス向上が達成されたとのことです。
この提案で標準に追加しようとしているものは以下のものです
- 再配置(relocation)という操作の定義
std::relocate(), std::relocate_at()- 再配置操作を行う関数
uninitialized_relocate(), uninitialized_relocate_n()- 未初期化領域に対する再配置操作
- trivially relocatableの定義
[[trivially_relocatable]]属性- 型に付加して、その型がtrivially relocatableであることをコンパイラに伝える
[[trivially_relocatable(expr)]]のようにして、テンプレートの文脈で切り替えることも可能(exprはbool型の定数式)
- 型特性
std::is_relocatable, std::is_nothrow_relocatable, std::is_trivially_relocatable- 再配置可能性、その
noexcept/トリビアル性の検出
- 再配置可能性、その
relocatableコンセプト- 再配置可能な型の定義
再配置と同等の操作は既に既存のコードベースでそこそこ観測でき、そこではUBを回避するために複雑な実装を選択していて、ユーザビリティを損ねています。この提案によって、それらのコードベースでは実装の簡略化とユーザーエクスペリエンス向上というメリットを得られます。また、標準ライブラリ実装においても、実装者に再配置を活用して実装を最適化するという選択肢を与えることができます。
P1222R4 A Standard flat_set
キーの検索がstd::set比で高速に行える連想コンテナ、flat_setの提案。
以前の記事を参照
このリビジョンでの変更は、flat_map(P0429)のレビューによる文言修正の関連する部分の適用と、LWGのレビューを受けての文言修正などです。
この提案はこのリビジョンを持ってLWGのレビューを終えており、次の全体会議で投票にかけられる予定です。
P1223R5 find_last
指定された値をシーケンスの後ろから探索するfind_lastアルゴリズムの提案。
このリビジョンの変更はよく分かりません(多分提案する文言修正のみです)。
この提案はこのリビジョンを持ってLWGのレビューを終えており、次の全体会議で投票にかけられる予定です。
P1642R10 Freestanding Library: Easy [utilities], [ranges], and [iterators]
[utility]、<ranges>、<iterator>から一部のものをフリースタンディングライブラリに追加する提案。
前回の記事を参照
- P1642R3 Freestanding Library: Easy [utilities], [ranges], and [iterators] - [C++]WG21月次提案文書を眺める(2020年6月)
- P1642R4 Freestanding Library: Easy [utilities], [ranges], and [iterators] - [C++]WG21月次提案文書を眺める(2020年7月)
- P1642R5 Freestanding Library: Easy [utilities], [ranges], and [iterators] - [C++]WG21月次提案文書を眺める(2020年12月)
- P1642R6 Freestanding Library: Easy [utilities], [ranges], and [iterators] - [C++]WG21月次提案文書を眺める(2021年06月)
- P1642R7 Freestanding Library: Easy [utilities], [ranges], and [iterators] - [C++]WG21月次提案文書を眺める(2021年10月)
- P1642R8 Freestanding Library: Easy [utilities], [ranges], and [iterators] - [C++]WG21月次提案文書を眺める(2022年04月)
- P1642R9 Freestanding Library: Easy [utilities], [ranges], and [iterators] - [C++]WG21月次提案文書を眺める(2022年05月)
このリビジョンでの変更は、<algorithm>の削除、フリースタンディングエイリアスについての文言を追加、この提案で検討済の全体会議での投票待ち提案のリスト追加、などです。
この提案はLWGのレビューを終えて、次の全体会議で投票にかけられる予定です。
P1673R9 A free function linear algebra interface based on the BLAS
標準ライブラリに、BLASをベースとした密行列のための線形代数ライブラリを追加する提案。
以前の記事を参照
- P1673R3 A free function linear algebra interface based on the BLAS - [C++]WG21月次提案文書を眺める(2021年04月)
- P1673R4 A free function linear algebra interface based on the BLAS - [C++]WG21月次提案文書を眺める(2021年08月)
- P1673R5 A free function linear algebra interface based on the BLAS - [C++]WG21月次提案文書を眺める(2021年10月)
- P1673R6 A free function linear algebra interface based on the BLAS - [C++]WG21月次提案文書を眺める(2021年12月)
- P1673R7 A free function linear algebra interface based on the BLAS - [C++]WG21月次提案文書を眺める(2022年04月)
- P1673R8 A free function linear algebra interface based on the BLAS - [C++]WG21月次提案文書を眺める(2022年05月)
このリビジョンでの変更は
std::mdspanの最新リビジョン(特にP2253の適用)の変更を反映- 提案する文言の修正や改善
layout_transposeの変更scaledとconjugatedの変更- SG6/LEWGの推奨に基づく変更
などです。
P1689R5 Format for describing dependencies of source files
C++ソースコードを読み解きその依存関係をスキャンするツールが出力する依存関係情報のフォーマットを定める提案。
以前の記事を参照
- P1689R3 Format for describing dependencies of source files - [C++]WG21月次提案文書を眺める(2020年12月)
- P1689R4 Format for describing dependencies of source files - [C++]WG21月次提案文書を眺める(2020年07月)
このリビジョンでの変更は、同じヘッダを異なる方法でインポートする例の追加、モジュールがインターフェースに影響を与えるか(exportしているか)を表すis-interfaceキーの追加などです。
P1774R8 Portable assumptions
コンパイラにコードの内容についての仮定を伝えて最適化を促進するための[[assume(expr)]]の提案。
以前の記事を参照
- P1774R4 Portable assumptions - [C++]WG21月次提案文書を眺める(2021年10月)
- P1774R5 Portable assumptions - [C++]WG21月次提案文書を眺める(2021年12月)
- P1774R6 Portable assumptions - [C++]WG21月次提案文書を眺める(2022年02月)
このリビジョンでの変更は、ラムダキャプチャに関する問題についてのCWG/EWGの投票と議論を追記したことです。
前回も少し説明していましたが、[[assume(expr)]]はexprに現れている名前をODR-useするため、テンプレートのインスタンス化やラムダのキャプチャを引き起こします。これは実装が[[assume(expr)]]を無視(未実装)する場合も同様です。
例えば下記のようなコードで、コンパイル時と実行時の両方でその影響を観測できます。
constexpr auto f(int i) { return sizeof( [=] { [[assume(i == 0)]]; } ); } struct X { char data[f(0)]; };
MSVC/GCC/clang/ICCにおいて、このコードのsizeof(X)は[[assume(i == 0)]]がある場合に4になり、ない場合は1になります。この振る舞いはこの提案の意図したところであり、EWG/CWGの議論において合意されたことです。
とはいえこの例のコードを見てわかるように、[[assume]]の使用によってABIの静かな変更が引き起こされるのは非常に稀であり、そのようなコードは(このサンプルのように)非常に奇妙な[[assume]]の使い方をしているはずです。そのような場合にユーザーはABIがポータブルであることを仮定しないべきです。
また、[[assume]]がODR-useを必要とするということは、そこでは宣言のみで定義がない関数を使用できないことを意味します。
P1839R5 Accessing object representations
reinterpret_cast<char*>によるオブジェクト表現へのアクセスを未定義動作とならないようにする提案。
以前の記事を参照
- P1839R3 Accessing Object Representations - [C++]WG21月次提案文書を眺める(2022年02月)
- P1839R4 Accessing Object Representations - [C++]WG21月次提案文書を眺める(2022年03月)
このリビジョンでの変更は、
- 提案の範囲をオブジェクト表現の読み取りのみを扱うようにした(書き込みに関しては触れないようにした)
- オブジェクト表現内で暗黙のオブジェクト作成が行われないようにした
- 既知の問題点を追記
などです。
P1967R7 #embed - a simple, scannable preprocessor-based resource acquisition method
コンパイル時(プリプロセス時)にバイナリデータをインクルードするためのプリプロセッシングディレクティブ#embedの提案。
以前の記事を参照
- P1967R3
#embed- a simple, scannable preprocessor-based resource acquisition method - [C++]WG21月次提案文書を眺める(2021年04月) - P1967R4
#embed- a simple, scannable preprocessor-based resource acquisition method - [C++]WG21月次提案文書を眺める(2021年06月) - P1967R5
#embed- a simple, scannable preprocessor-based resource acquisition method - [C++]WG21月次提案文書を眺める(2021年04月) - P1967R6
#embed- a simple, scannable preprocessor-based resource acquisition method - [C++]WG21月次提案文書を眺める(2022年05月)
このリビジョンでの変更は
- 提案する文言の改善
is_emptyをif_emptyへ変更prefix/suffix/if_emptyを提案としてオプションにした- これらで詰まった時でも、
#embed単体を先に進めるため
- これらで詰まった時でも、
- 属性への参照を削除
- 2022年6月のEWGレビューについて追記
などです。
P2167R2 Improved Proposed Wording for LWG 2114 (contextually convertible to bool)
contextually convertible to boolと言う規格上の言葉を、C++20で定義されたboolean-testableコンセプトを使用して置き換える提案。
- P2167R0 : Improved Proposed Wording for LWG 2114 - [C++]WG21月次提案文書を眺める(2020年5月)
- P2167R1 Improved Proposed Wording for LWG 2114 (contextually convertible to bool) - [C++]WG21月次提案文書を眺める(2021年7月)
このリビジョンでの変更は
- 提案する文言について部分部分で4つのオプションを提示し、どれを選択するのかの質問項目を追加
Exotic Types(演算子オーバーロードの結果、
pairとtupleに包んだときにそれぞれで比較の結果が変わるような型)についてのセクションの追加
P2278R4 cbegin should always return a constant iterator
std::ranges::cbegin/cendを拡張して、常にconst_iteratorを返すようにする提案。
以前の記事を参照
- P2278R0 cbegin should always return a constant iterator - [C++]WG21月次提案文書を眺める(2021年01月)
- P2278R1 cbegin should always return a constant iterator - [C++]WG21月次提案文書を眺める(2021年09月)
- P2278R2 cbegin should always return a constant iterator - [C++]WG21月次提案文書を眺める(2021年11月)
- P2278R3 cbegin should always return a constant iterator - [C++]WG21月次提案文書を眺める(2022年04月)
このリビジョンでの変更は、提案する文言の改善とstd::span<T>に対するviews::as_constがstd::span<const T>を返すようにしたことなどです。
この提案はLWGのレビューを終えており、次の全体会議で投票にかけられる予定です。
P2490R3 Zero-overhead exception stacktraces
例外からのスタックトレースの取得の提案について、問題点とその解決策についての提案。
以前の記事を参照
R1とR2は公開されていないようです。
R1の変更は、提案するソリューションの1つとして[[with_stacktrace]]属性によるアプローチを追加したこと、再スローに関する議論の追記、フォールバック実装・コルーチン・アロケータに関する説明の追記などです。
R2の変更は、[[with_stacktrace]]属性をこの提案のメインのソリューションとして据えたことです。
R3(このリビジョン)での変更は、モチベーションを明確にしたことです。
現在のこの提案のメインソリューションは、catchブロックに対する[[with_stacktrace]]属性の付加によって、そのcatchブロックでスタックトレースを取得することを明示するものです。
void f() noexcept(false); int main() { try { f(); } catch ([[with_stacktrace]] std::exception& e) { std::cout << e.what() << "\n" << std::stacktrace::from_current_exception() << std::endl; } }
この属性の意味は、そのcatchブロックの例外は関連するスタックトレース(associated stacktrace)を持っており、直近の例外throw地点からこの補足地点までの間そのスタックトレース情報を保持するように実装に指定するものです。std::stacktrace::from_current_exception()は呼び出し時点で処理中の例外が関連するスタックトレースを保持している場合はそれをstd::stacktraceオブジェクトとして返し、ない場合は未規定の値を返します。
この提案の機能は全てのABIで実装可能ではない可能性があるため、現在のところオプショナルに近しい機能です。属性構文の無視できるという性質は、この属性もしくはその機能をサポートしない場合は無視しても良いという実装への要求としてのこの機能の側面と一致しています。
このソリューションの欠点としては、処理中の例外に関連するスタックトレースがない場合は実行時の失敗となる点です。ただしこのことは現在でもstd::current_exception()で認められていることであり、サポートされない(属性が無視された)場合にはメリットである可能性があります。
P2502R2 std::generator: Synchronous Coroutine Generator for Ranges
Rangeライブラリと連携可能なT型の要素列を生成するコルーチンジェネレータstd::generator<T>の提案。
以前の記事を参照
このリビジョンでの変更は多岐に(約2ページ分)渡りますが、大きな設計の変更は無いようで、提案する文言やコードの修正・改善がメインです。
この提案はLWGのレビューを終えており、次の全体会議で投票にかけられる予定です。
P2505R3 Monadic Functions for std::expected
↓
P2505R4 Monadic Functions for std::expected
std::optionalのMonadic interfaceをstd::expectedにも導入する提案。
以前の記事を参照
- P2505R0 Monadic Functions for
std::expected- WG21月次提案文書を眺める(2021年12月) - P2505R1 Monadic Functions for
std::expected- WG21月次提案文書を眺める(2022年02月) - P2505R2 Monadic Functions for
std::expected- WG21月次提案文書を眺める(2022年04月)
R3での変更は
- Deducing thisを使用しない理由を追加
- フリー関数ではなくメンバ関数にする理由を追加
.transform()の戻り値型がunexpectedやinplace_tにならないように制約expected<void, E>::transform()についての設計議論と文言の追加.error_or()の設計議論を追加
R4(このリビジョン)での変更は
.value_or()の双対的な関数である.error_or()の追加.error_or()を含めるように提案文書を更新- 提案する文言の修正
- 実装へのリンクを追加
などです。
このリビジョンで追加された.error_or()はstd::expected<T, E>オブジェクトが正常値(Tの値)を保持している場合に指定されたEの値を返し、異常値(Eの値)を保持している場合はそれをそのまま返す関数です。ちょうど、正常値に対しての.value_or()と逆のことを行います。
auto create_file(char const*) -> std::expected<file, std::error_code>; // error_codeが失敗していたら、エラーメッセージを表示してtrueを返す bool test_and_report(const std::error_code&); int main() { auto f = create_file("file"); // error_or()で、ファイルの作成に成功していたら成功状態のerror_codeオブジェクトを渡す if (test_and_report(f.error_or({}))) { return; } }
この提案はLEWGのレビューを一旦完了し、LWGに転送するためのLEWGの全体投票待ちをしています。
P2513R3 char8_t Compatibility and Portability Fix
char8_tの非互換性を緩和する提案。
以前の記事を参照
- P2513R0
char8_tCompatibility and Portability Fixes - WG21月次提案文書を眺める(2021年12月) - P2513R1
char8_tCompatibility and Portability Fixes - WG21月次提案文書を眺める(2022年02月) - P2513R2
char8_tCompatibility and Portability Fixes - WG21月次提案文書を眺める(2022年05月)
このリビジョンでの変更は、タイポの修正のみです。
この提案はすでにCWGでのレビューを終えており全体会議の投票に進めることに合意が取れていますが、EWGでの全体投票がまだなのでそれを待っています。
P2551R2 Clarify intent of P1841 numeric traits
P1841R2で提案されている数値特性(numeric traits)取得ユーティリティについて、実装経験からの疑問点を報告する文書。
以前の記事を参照
- P2551R0 Clarify intent of P1841 numeric traits - WG21月次提案文書を眺める(2022年02月)
- P2551R1 Clarify intent of P1841 numeric traits - WG21月次提案文書を眺める(2022年05月)
このリビジョンでの変更は、前回削除したものも含めて全部の疑問点を記載するようにしたこと、提案する変更のセクションを追加したことなどです。
P2562R1 constexpr Stable Sorting
std::stable_sortとそのファミリをconstexpr対応する提案。
以前の記事を参照
このリビジョンでの変更は、cpp_lib_constexpr_algorithms機能テストマクロの値を更新するようにしたことです。
P2570R0 On side effects in contract annotations
コントラクト注釈に指定された条件式が副作用を持つ場合にどうするかについて、議論をまとめた文書。
この文書はP2182で定義されているMVPと呼ばれるコントラクトの最小セットをベースとして、コントラクト注釈に指定されている条件式が副作用を持つ場合に標準としてどう規定するかの現在の議論や方向性についてまとめたものです。
この文書で提示されている副作用に対する選択肢は以下の3つです
- 条件式が副作用を持たないことを証明できない場合、コンパイルエラーとする
- Cの
assertマクロのモデルを使用する- 一方のモード(Eval and abort)では副作用を評価し、一方のモード(No eval)では評価しない
- Eval and abortモードでは、条件式を複数回評価することを許可する
- 副作用の信頼性を低下させる
Eval and abortモードは、契約条件を評価し破られた(falseとなった)場合にはプログラムを終了させる実行モードで、No evalモードは全ての契約条件を無視する実行モードです。契約違反ハンドリングや契約違反後の続行モードは、C++20コントラクトの際に炎上した部分であるので、MVPには含まれていません。
現在のSG21の方向性としては、MVPをまず標準に導入してからそこに機能を追加していくことを目指しているため、MVPの部分(この文書の範囲も含めて)は将来の拡張について開いているようにしようとしています。そのため、次のような指針があります
- 物議をかもしている部分(機能)について何らかのセマンティクスを指定することは避けようとしている
- 2つの可能な将来の方向性がある場合、どちらに対してもオープンである事を目指す
- 定義したくない部分については、UB/IF-NDRよりもill-formedにする
- プログラマに実行時の驚きを与えることを回避し、構文スペースを節約する
- 未規定や実装定義として指定するよりも、UBとして定義する
- 将来的にプラットフォーム間で統一されたセマンティクスを提供し、その部分をill-formedにすることができるようにしておく
そしてSG21は、コントラクトは安全性を向上させるための機能であるとして機能そのものもより安全なものにしようとしています。とはいえ、この文書で扱われている副作用をはじめとしてC++の危険な側面を多く含んでいるため、コントラクトについては他のC++の部分とは異なる効率性と安全性のトレードオフを取らざるを得ない部分があります。その場合でも、契約条件についてC++の他のところと同様に扱う、などの統一性の要求を重視しない方針です。
P2572R0 std::format() fill character allowances
std::formatにおいて、文字列のアライメント(左寄せ、中央寄せ、右寄せ)の際に空白を埋める文字として使用可能な文字を制限する提案。
std::formatでは、> < ^とその後に指定する整数値によって文字列の幅と配置を調整できます。
#include <format> #include <iostream> int main() { std::cout << std::format("|{:>6}|\n", 23); // 右寄せ std::cout << std::format("|{:<6}|\n", 23); // 左寄せ std::cout << std::format("|{:^6}|\n", 23); // 中央寄せ }
出力例
| 23| |23 | | 23 |
その際、空白(右寄せの時の左側など)を埋める文字としてはホワイトスペースが使用されますが、その文字(以降、これを穴埋め文字と呼びます)を変更することもできます。変更するには、寄せの指定の前に使用したい文字を指定します。
#include <format> #include <iostream> int main() { // 穴埋めは*で行う std::cout << std::format("|{:*>6}|\n", 23); // 右寄せ std::cout << std::format("|{:*<6}|\n", 23); // 左寄せ std::cout << std::format("|{:*^6}|\n", 23); // 中央寄せ }
|****23| |23****| |**23**|
この穴埋めに使用可能な文字としては{と}以外の任意の文字が指定可能とされています。
#include <format> #include <iostream> int main() { // 例えば絵文字 std::cout << std::format("|{:🤔>6}|\n", 23); // 右寄せ std::cout << std::format("|{:🤔<6}|\n", 23); // 左寄せ std::cout << std::format("|{:🤔^6}|\n", 23); // 中央寄せ }
|🤔🤔🤔🤔23| |23🤔🤔🤔🤔| |🤔🤔23🤔🤔|
現在のstd::formatは、特定のコードポイント範囲の文字を幅2、それ以外の文字を幅1として文字幅を推定してこのような文字の配置を行っています。穴埋め文字に例えばゼロ幅文字や負の幅を持つ文字、3以上の幅を持つ文字(アラビア文字など)などを指定すると正しく配置できなくなります。また、文字の幅は文字種だけでなくフォントによっても変化するため、これを厳密に推定することはおそらく不可能です。
ポータブルな実装のためには、std::formatは穴埋めに使用可能な文字を制限する必要があり、この文書はそれを提案するものです。
制限に当たってはまず、どのような文字を使用可能とするかを決定する必要があります。この提案では次の4つを上げています
- ユニコード拡張書記素クラスタ(extended grapheme cluster : EGC)の任意の文字
- UAX15で定義されている、ストリームセーフなユニコード拡張書記素クラスタの任意の文字
- 任意の単一のUCSスカラー値
- 単一のコードユニットを使用してエンコードされた、単一のUCSスカラー値
1つ目のオプションでは、任意長のコードポイントから構成される文字をサポートするための実装が必要となり、これは動的メモリ確保(穴埋め文字の保存のため)とEGC境界検出の実装が必要となります。
2つ目のオプションでは、1文字のコードポイント長が最大32に制限されるため、動的メモリ確保を回避できる可能性があります。それ以外は1つめと同じです。
3つ目のオプションでは、1つ目と2つ目のデメリットをすべて回避し、穴埋め文字を単一のchar32_tの値に格納できます。つまりこのオプションでは、1文字(EGCの任意の1文字)が複数の文字(コードポイント)から構成されるような文字は使用できません。
4つ目のオプションでは、穴埋め文字の保存要件を単一のコードユニット(cahr or wchar_t)にまで減らすことができ、それ以外は3と同様になります。しかし、副作用として許容される穴埋め文字がエンコードによって変化します(例えばサロゲートぺア)。
次に、穴埋め文字に制限範囲外の文字が与えられた場合の振る舞いを決定する必要があります。この提案では
- 穴埋め文字の幅を1として扱って穴埋めする
- 指定された幅を満たすかと超えるまで、穴埋めする(オーバーフィル)
- 指定された幅を超えないように、穴埋めする(アンダーフィル)
- 別の穴埋め文字にフォールバックする
- 指定された穴埋め文字を使用すると指定された幅を超えることが分かる場合に、別の穴埋め文字を使用する
- 未定義、未規定、実装定義
- エラー
- `format_error`例外を投げる - 指定された幅で配置できない場合にのみ、エラー
- `format_error`例外を投げる
次の表は、これらのオプションによって、std::format(">{:🤡^4}<\n", 'X')がどうなるかを示したものです
| オプション | 結果 |
|---|---|
参照配置(-を使用) |
>-X--< |
| 文字幅1とする | >🤡X🤡🤡< |
| オーバーフィル | >🤡X🤡< |
| アンダーフィル | >X🤡< |
| フォールバック(ホワイトスペース) | > X🤡< |
| 未定義 | ??? |
| エラー | N/A |
これらのことと、既存実装(clang/gcc+{fmt}/MSVC)の振る舞いを参照したうえで、この提案ではこの問題を次のように修正することを提案しています
- 穴埋め文字は、単一のUCSスカラー値に制限する(オプション3)
- 制限範囲外の値が指定された場合はエラー(オプション6)
- 任意のEGC文字をサポートしたくなった場合、ABI破壊が生じる
- 穴埋め文字の推定幅は、常に1とする
- 既存実装が全てそうなっていたため
- フォーマット引数(not穴埋め文字)の幅がそもそも指定幅を超える場合、アライメントの指定は無視されることを明確化
- 指定されたアライメントを達成するために、穴埋め文字がどのように挿入されるかを明確化
これは、{fmt}およびMSVCの実装を標準化するものです。また、このエラーはstd::formatの場合はコンパイルエラーとなります。
- LWG Issue 3576. Clarifying fill character in
std::format - LWG Issue 3639. Handling of fill character width is underspecified in
std::format - Unicodeのgrapheme cluster (書記素クラスタ) - hydroculのメモ
- UAX #15 : UNICODE NORMALIZATION FORMS
- P2572 進行状況
P2575R0 2022-05 Library Evolution Poll Outcomes
2022年の5月に行われた、LEWGでの全体投票の結果。
投票の対象となった提案は以下のもので、投票に当たって寄せられた賛否のコメントが記載されています。
- P1885R10 Naming Text Encodings to Demystify Them
- P0792R8 function_ref
- P1223R3 find_last
- P1169R3 Static operator()
- P2553R1 Make mdspan size_type Controllable
- P2554R0 C-Array Interoperability Of mdspan
- P2540R0 Empty Product For Certain Views
- P2538R0 ADL-Proof projected
- P2520R0 move_iterator Should Be A Random Access Iterator
- P2499R0 string_view Range Constructor Should Be Explicit
- P2549R0 unexpected Should Have error As Member Accessor
- P2517R0 Add A Conditional noexcept Specification To apply
- P2300R5 std::execution
- C++26向け
- P1083R5 resource_adaptor
- C++26向け
- P1202R4 Asymmetric Fences
- Concurency TS v2向け
結果的に、P1083R5以外はLWGに転送されたようです。
P2582R1 Wording for class template argument deduction from inherited constructors
クラステンプレートの実引数推定(CTAD)を継承コンストラクタからでも行えるようにする提案。
以前の記事を参照
このリビジョンでの変更は、CWGのレビューを受けて提案する文言を変更した事です。
この提案は既にCWGのレビューを終えており、次の全体会議で投票にかけられることが決まっています。
P2590R1 Explicit lifetime management
メモリ領域上にあるトリビアルな型のオブジェクトの生存期間を開始させるライブラリ機能の提案。
以前の記事を参照
このリビジョンでの変更は、モチベーションについて追記したこととCWGのレビューを受けて提案する文言を変更した事です。
この提案はコア言語の部分についてはCWGのレビューを終えており、ライブラリの部分に関してLWGでレビュー中です。
P2591R1 Concatenation of strings and string views
std::stringとstd::string_viewを+で結合できるようにする提案。
以前の記事を参照
このリビジョンでの変更は、文章の一部の改善のみのようです。
P2594R0 Slides: Allow programmer to control and detect coroutine elision (P2477R2 Presentation))
P2477(コルーチンの動的メモリ確保章竜最適化の制御のための機能の提案)の解説スライド
P2477に関しては以前の記事を参照。
- P2477R0 Allow programmer to control and detect coroutine elision by static constexpr bool should_elide() and - [C++]WG21月次提案文書を眺める(2021年10月)
- P2477R2 Allow programmer to control and detect coroutine elision - [C++]WG21月次提案文書を眺める(2021年11月)
このスライドは、P2477の内容をLEWGのメンバにプレゼンするためのもので、P2477の動機や目的、現状分かっている懸念事項などがまとめられています。
P2596R0 Improve std::hive::reshape
std::hiveの容量モデルを単純化する提案。
std::hive(元std::colony)は可変サイズブロックの連結リストです。要素はブロック内の空きスペースに挿入され、要素を削除してもブロックは解放されずそのスペースは再利用されます。ブロック内に空きスペースがなくなると新しいブロックを確保して利用します。このブロックというのは1つの配列のようなもので、そのサイズは固定長ではありませんが一度確保された後にサイズが変更されることはありません。この性質によって、std::hiveはキャパシティを増大させた時でも既存要素のメモリ位置は安定しており、イテレータが無効になったりしません。
現在のstd::hiveでは、std::hive_limitsというシンプルな構造体によってstd::hiveのブロックサイズの下限と上限を指定することができます。
// ブロックサイズを[4, 5]で指定して構築 std::hive<int> h({1,2,3,4,5,6}, std::hive_limits(4, 5)); // [1 2 3 4 5] [6 _ _ _] h.reserve(10); // [1 2 3 4 5] [6 _ _ _] [_ _ _ _]
ここのコメントの[...]はstd::hiveのブロックと要素がどうなっているかを表したもので、_は未使用領域を示しています。
さらに、このように構築した後でstd::hive_limitsによってブロックサイズを調整(reshape)することができます
// ブロックサイズを[4, 5]で指定して構築 std::hive<int> h({1,2,3,4,5,6}, std::hive_limits(4, 5)); // [1 2 3 4 5] [6 _ _ _] h.reserve(10); // [1 2 3 4 5] [6 _ _ _] [_ _ _ _] // ブロックサイズを[3, 4]へ調整 h.reshape(std::hive_limits(3, 4)); // [6 1 2 3] [4 5 _ _]
この時、最初に指定したブロックサイズが.reshape()後に不正(指定された最小値と最大値の範囲外)になる場合、ブロックは確保しなおされ要素の再配置が行われます。また、.reserve()した領域も解放されてしまう可能性があります。このため、通常は.reshape()してから.reserve()することが推奨されます。
このstd::hiveの容量モデルに関して、次のような問題があります
- ブロック最大サイズは実際には有用ではない
- 最小を気にすることは多いが、最大は気にしない
- 組み込み環境などで最大容量を制限したい場合でも、
std::hive_limitsの指定は要素数であってバイト数ではない- また、ブロックサイズを
nとした時、1つのブロックのために確保する容量はn * sizeof(T)よりも多くなる。そのため、最大容量の制限はあまり意味がない
- また、ブロックサイズを
- 最大ブロックサイズは
O(n)動作の原因となる- アクティブブロックは先頭から順にナンバリングされており、削除や追加の際には番号を付け直す必要がある。これに(アクティブブロック数を
nとして)O(n)の時間がかかる - そのような操作がループ内で行われると、目に見えない
O(n^2)の計算量を埋め込むことになる
- アクティブブロックは先頭から順にナンバリングされており、削除や追加の際には番号を付け直す必要がある。これに(アクティブブロック数を
- ムーブ時のセマンティクスは、ほぼ間違いなく直感的ではない
std::hive_limitsによるブロックサイズ制限はムーブやコピーによって伝播する- ブロックサイズ制限は
std::hiveの値の一部ではないはず
.splice()がO(n)となり、例外を投げうるh.splice(h2)ではhの制限が変更されないが、h2にhの最大サイズよりも大きなブロックが含まれている場合に失敗し例外を投げることを意味する
std::hive_limitsを受け取るためにコンストラクタの数を増大させているstd::hive_limitsは不必要な未定義動作を導入する- ユーザーによって指定された制限が、実装定義のハードリミットの範囲外にある場合は未定義動作とされる
- このハードリミットは通常それほど大きな値ではないため(参照実装では255)、用意にUBを踏みうる
- また、
std::hive_limitsを受け取るAPIはその制限に触れる場合に何が起こるか(あるいは起こらないのか)を規定しなければならず、仕様を肥大化させる
この提案は、これらの問題を解決するために、std::hiveからブロックサイズ指定を取り除いて、別の容量管理モデルを導入しようとするものです。
この提案では、std::hive_limitsを無くして、ブロックサイズ指定が一時的なプロパティとなるようにすることを提案しています。このモデルは、std::vectorやstd::dequeにおいてそのキャパシティが一時的なプロパティであることと同様です。他に、キャパシティやソートの有無がstd::hiveの一時的なプロパティに該当しています。
std::hive<int> h = {1,2,3}; h.erase(h.begin()); // [_ 2 3] h.sort(); // [_ 2 3] // ソート状態はその後の操作で維持されない h.insert(4); // [4 2 3], no longer sorted h.reshape(4, 8); // [4 2 3 _] [_ _ _ _] // ブロックサイズ制限は一時的(コピーやムーブで推移しない) auto h2 = h; // [4 2 3], no longer capacious
そして、.reshape()のインターフェースはbool reshape(size_t min, size_t n = 0)のように変更されます。minはブロックサイズの下限であり、nはこの操作の後でメモリを確保することなく挿入可能な最低要素数です。戻り値は、イテレータが無効化されたか否かを伝えるためのものです。
この変更によって、std::hiveの最大ブロックサイズの指定は無くなり、実装が要素の隣接性を高めようとする場合にそれを制限することはできませんが、隠れたO(n)計算量の問題を回避できるようになります。
- P0447R11 Introduction of std::colony to the standard library - [C++]WG21月次提案文書を眺める(2020年11月)
- P2596 進行状況
P2598R0 “Changing scope for lambda trailing-return-type” (P2036) should not be a DR
P2036(ラムダの戻り値型の推論時、キャプチャした変数を使用するようにする提案)の変更をDRとしないようにする提案。
P2036については以前の記事を参照
P2036の内容は検討段階では問題ないと思われていましたが、実際にclangにおいて実装されたところ既存のコードを壊すことが判明しました。その報告とともにその緩和策も提案(P2579)されていますが、まだ採択されておらず、適用されたとしても既存のコードを破壊する可能性がまだ残っています。
それらの変更をDRとした場合、実装されたコンパイラでは破壊的変更が静かに全てのバージョン(C++11以降)に対して適用されることになります。あるいは、実装はDRをオプショナルとしたり実装しないことを選択するかもしれず、その場合この変更はC++コードのポータビリティを損ねることになります。これでは、破壊的変更を回避したい人も最新のC++の変更を積極利用したい人のどちらも幸せになりません。
そもそも、このような静かな意味の変更を行うのは良いことではなく、それを遡及的に行うかもしれないしそうでないかもしれない、とするのはさらに悪いことです。この変更について知らないユーザーは、ある日突然有効だと思っていたコードが壊れていることに気づき、修正する必要性に迫られます。DRとしないことで(C++23の破壊的変更とすることで)、少なくとも問題の回避のために言語バージョンを上げないという選択肢が与えられます。DRの場合はそのような選択肢はなく、すぐに行動を起こさなければなりません。
これらの理由によりこの提案では、P2036(と関連する変更)をDRとせずにC++23以降の破壊的変更とすることを提案しています。
P2599R0 mdspan::size_type should be index_type
↓
P2599R1 mdspan::size_type should be index_type
↓
P2599R2 index_type & size_type in mdspan
std::mdspanのメンバ型size_typeをindex_typeに変更する提案。
標準ライブラリのコンテナ等のsize_typeは通常符号なし整数型(std::size_t)が使用され、それがほぼデファクトになっています。当初のstd::mdspanのsize_typeはstd::size_tで固定であったため問題はありませんでしたが、P2553(未採択)によってsize_typeを制御可能とするとともに任意の整数型を使用可能となるようになると名前と実態が既存の慣行と一致しなくなります。
この提案は、このような理由からstd::mdspan(とstd::extents)のsize_typeの名前をindex_typeに変更しようとするものです。
さらにその上で、std::mdspan::size_typeをmake_unsigned_t<index_type>で再定義し、std::mdspan::size()はその型の値を返すようにすることも提案しています(これはLEWGからのリクエストのようです)。
- P2553R0 Make mdspan
size_typecontrollable - [C++]WG21月次提案文書を眺める(2022年02月) - P2553R1 Make mdspan
size_typecontrollable - [C++]WG21月次提案文書を眺める(2022年03月) - P2599 進行状況
P2600R0 A minimal ADL restriction to avoid ill-formed template instantiation
ADLのルールを少し制限することで、意図しないインスタンス化を防止する提案。
ADLにおいては、引数型から関連エンティティを抽出しその名前空間を探索候補に加えることが行われます。その際、関連エンティティに含まれるクラステンプレートは暗黙にインスタンス化されるため、意図しないコンパイルエラーが起こる場合があります。
struct Incomplete; // Tに不完全型を指定してインスタンス化するとエラーになる template<typename T> struct Wrap { T t; }; template<typename Unused> struct Testable { explicit operator bool() const { return true; } }; int main() { Testable<Incomplete> l; if (l) // OK return 1; if(!(bool)l) // OK return 0; if(!l) // OK return 0; Testable<Wrap<Incomplete>> l2; if(l2) // OK return 1; if(!(bool)l2) // OK return 0; if(!l2) // ERROR return 0; }
上記の!l, !l2ではoperator!の探索が発生しており、ADLによる探索が行われています。クラステンプレートのADLでは、そのテンプレートパラメータの型からも関連名前空間を取得しようとし、その際にテンプレートパラメータの型のインスタンス化が発生します。
Testable<Incomplete>は追加でインスタンス化するものはありませんが、Incomplete型の完全性が必要となる使われ方をしていないためエラーは起きません。一方、Testable<Wrap<Incomplete>>ではWrap<Incomplete>のインスタンス化が発生し、Wrap<T>ではTの完全性が必要(メンバ変数として宣言)なため、コンパイルエラーとなります。
すなわち、ADLがクラステンプレートのテンプレートパラメータ型に対してインスタンス化を引き起こし、その際にその完全性が要求されるかされないかが異なること、によってこの振る舞いの微妙な差が生じています。
式!lはADLが不完全型を無視している間はwell-formedですが、例えば次のように後から定義を追加すると結果が変わります。
struct Incomplete{ friend bool operator!(Testable<Incomplete>) { return true; } }
ODR違反につながりうるにも関わらず、規格はなぜ不完全型をADLの関連エンティティに含めているのでしょうか?また、まだインスタンス化されていないテンプレートに対しても同じことを適用してはいけないのでしょうか?
この例は恣意的に見えるかもしれませんが、Testableを例えばstd::unique_ptrにすると現実的なユースケースにおいてもこの問題に出会いうることが見えてきます。
class Incomplete; using Data = std::array<Incomplete, 3>; using Ptr = std::unique_ptr<Data>; void assert_nonnull(std::span<Ptr> x) { for (const Ptr& ptr : x ) { // ERROR : 'std::array<_Tp,_Nm>::_M_elems'は不完全型 assert(ptr); } }
ここでは、begin(std::span<std::unique_ptr<std::array<Incomplete, 3>>>)のような関数の探索によってstd::array<Incomplete, 3>がインスタンス化され、Incompleteの完全性が要求されることでエラーが起きています。
これと似た問題はP2538でも提起されています。そこでは、ADLに対する防壁を設置するパターンによってADLによる不要なインスタンス化を防止しようとしています。
この問題はまた、非メンバoperator[]やオーバーロード?:のような機能を破壊的変更にしてしまっており、将来の機能追加・改善を妨げています。新しい機能がADLに関連する場合、常にこの問題を考慮しなければなりません。
この提案では、ADLにおけるこのような意図しないインスタンス化が発生しないようにすることで、これらの問題を解決しようとするものです。これによって、P2538は不要となり、将来の機能拡張の際もこのれらの問題による破壊的変更を取り除くことができます。
このADLによるインスタンス化は[temp.inst/2]の「クラス型の完全性がプログラムのセマンティクスに影響を与える時、クラステンプレートは暗黙にインスタンス化される」という規定によるものののようです。基本的にクラス型の完全性はプログラムのセマンティクスに影響を与えませんが、ある名前(ここでは関数名)が存在するかどうかに関する知識はプログラムのセマンティクスに影響を与えます。そのため、クラステンプレートのインスタンス化が必要となるかどうかはインスタンス化した後でしか判断できず(hidden friendsのようにインスタンス化するまで存在が確定しない名前が考えられるため)、コンパイラはインスタンス化を避けることができません。
template<typename T> struct A { friend void f(const A&); // 依存名であり、インスタンス化が必要 }; void g(const A<int>& x){ f(x); }
したがって、少なくともADLのトリガーとなった直接の引数型のインスタンス化は必要です。ただし、この場合でもAのテンプレートパラメータTのインスタンス化までは必要ありません。
ADLの関連名前空間にはクラス型の基底クラスが含まれ、基底クラスを知るためにはそのクラスのインスタンス化が必要となります。仮にADLにおいて直接の引数型をインスタンス化しないようにしたとすると、その時点でのその型のインスタンス化の有無によって同じコードの振る舞いが変わります
namespace A { class B{}; void f(B*); } void f(void*); template<class T> class C : public A::B {}; // C<int>がインスタンス化される前に呼ばれたとすると void g(C<int>* p){ f(p); // ::f(void*)が呼ばれる、C<int>はまだインスタンス化されていない A::B* other_ptr = p; // C<int>がインスタンス化される f(p); // A::f(B*)が呼ばれる、 }
このことは、現在の不完全型の振る舞いによく似ています。
// 不完全型 class I; void g0(I* p) { f(p); // ::f(void*)が呼ばれる } // Iの定義 class I : public A::B {}; void g1(I* p) { f(p); // A::f(B*)が呼ばれる }
ただし不完全型においてはなぜその振る舞いの違いが起こるのかは明確(1つ目の時点でIはまだA::Bを継承していない)であり、やはり直接の引数型のインスタンス化は必要です。
これらのことから、この提案による解決策は、ADLの関連エンティティ内にあるまだインスタンス化されていないクラステンプレートは、それが直接の引数型となっている場合(ADLのトリガーとなっている型)を除いてインスタンス化されない、というようにADLの振る舞いを変更する事です。すなわち、ADLが行われる際はその時点でインスタンス化されていないクラステンプレートは現在の不完全型と同様に扱われる(無視される)ようにします。
この提案の変更の問題点はポインタ/参照からのADLにおいてインスタンス化済みか否かでADLの振る舞いが変化することです。そしてこの変更は、次の場合に既存の振る舞いを壊します
- まだインスタンス化されていないクラステンプレートの特殊化
X<Y>によってADLがトリガーされていて、名前探索でX<Y>のhidden friendsを見つけたい関数または演算子の呼び出し std::reference_wrapper<X<Y>>のようにラップされているものに対するADL
2つ目は次のような場合に起こります(この提案が採択されたとして
template<typename T> struct X { T data; friend auto operator<=>(const X&, const X&) = default; }; //static_assert(std::totally_ordered<X<int>>); // ↑のコメントアウトを解除しない場合、↓は失敗する static_assert(std::totally_ordered<std::reference_wrapper<X<int>>>);
std::totally_ordered内部では、std::reference_wrapper<X<int>>の値a, bに対してa < bの呼び出しが可能かをチェックしており、そこでADLがトリガーされます。
この場合、operator<の直接の引数型はstd::reference_wrapper<X<int>>であり、(この提案の採択後は)std::reference_wrapper<X<int>>そのものはインスタンス化されますが、そのテンプレートパラメータの型X<int>は関連エンティティではあるもののインスタンス化されず、Xで定義されているhidden friendsな<=>演算子を発見できません。なお、現在はこの場合でもX<int>がインスタンス化されるため問題は起こりません。
これは深刻な破壊的変更となりますが、標準ライブラリには現在これが問題になるクラステンプレートはなく、問題になる型に対してもこのように書くことは稀であり、std::reference_wrapperの通常の使用時には自動的にunwrapされるため問題にならない、と提案では主張しています。
また提案によれば、メインテーマとなっているADLを介したインスタンス化は実は長い間実装されていなかったようで、この提案の内容はある時期以前のコードには影響を与えないとの事です。
P2601R0 To make redundant empty angle brackets optional for class template argument lists
クラステンプレート使用時に、不要な<>を省略可能にする提案。
クラステンプレート宣言では、それを使用するコードを破壊することなくデフォルト引数付きのテンプレートパラメータを追加することができます。しかし、その方法は少なくとも1つのテンプレートパラメータが既にある場合にのみ行うことができます。クラステンプレートを使用する構文ではほとんどの場合に<>を必要とするため、テンプレートパラメータ全てにデフォルト引数を設定したとしても非テンプレートなクラスにテンプレートパラメータを追加できないためです。
一方で、C++17以降はCTADによって変数宣言においてその制限がなくなり、<>を省略することができます。ただし、それ以外の部分では依然として<>が必要です。
template <typename T = int> class C {}; C c; // OK (1) extern C x; // error: need C<> C *p; // error: need C<> C a[2]; // error: need C<> C &r = c; // error: need C<> struct S { C c; }; // error: need C<> struct D : C {}; // error: need C<> std::vector<C> v; // error: need C<> void foo(C c); // error: need C<>
この提案は、この制限を取り払うことで非テンプレートクラスからクラステンプレートへの非破壊的な書き換えを可能にしようとするものです。
この変更は現在コンパイルエラーとなっているものを許可しようとするものであるため破壊的ではなく、ある名前はクラスや関数などのエンティティ種別で共有できない(名前はスコープ内で一意である)ため上記の例は曖昧にもなりません。
P2602R0 Poison Pills are Too Toxic
標準ライブラリから、Poison Pillと呼ばれるオーバーロードを削除する提案。
Poison Pillオーバーロードとは、カスタマイゼーションポイントオブジェクト(CPO)の実装において使用されるテクニックで、std名前空間にある同名の関数を呼び出さないようにするためのものです。
namespace std::ranges { namespace impl { // Poison Pillオーバーロード // std::begin()を(名前探索的な意味で)毒殺する void begin(auto&) = delete; void begin(const auto&) = delete; // ranges::begin CPOの実体 // 制約等は省略 struct begin_fn { // ADLでbegin()を呼び出す auto operator()(auto&& range) const { return begin(range); // ここではstd::begin()が見つからない } }; } inline namespace cpo { // ranges::begin CPO inline constexpr impl::begin_fn begin; } }
この例はstd::ranges::beginCPOの効果の1つ(ADLによる非メンバ関数の探索)の簡略化された実装例です。std::ranges::beginの非メンバ関数探索ではADLによって探索が行われますが、std::ranges::begin自体がstd名前空間で定義されているため非修飾名探索(ADLの1つ前の探索)においてstd::begin()が見つかってしまいます。この関数はC++20以前の古いものでありコンセプトによるチェックなどはなく使用する候補として適切ではないため、std::ranges::beginではこれを呼び出さないようにしています。
このことは標準ライブラリにあるほとんどのCPOに当てはまり、同様のテクニックが多用されています。
一方で、このPoison PillオーバーロードはCPOにアダプトしたい型に対して不要な影響を及ぼしています。
struct A { friend auto begin(A const&) -> int const*; friend auto end(A const&) -> int const*; }; struct B { friend auto begin(B&) -> int*; friend auto end(B&) -> int*; };
この2つの型はどちらもrangesコンセプトを満たすことが期待されます。しかし、B, const Aはrangeですが、Aはrangeではありません。
これは、Poison Pillオーバーロードが担っている(いた)もう一つの役目である右辺値オブジェクトからのイテレータ取得禁止という効果の名残の悪影響によるものです。
当初のrangeコンセプトでは右辺値は完全に禁止されていましたが、std::string_viewのようにそのオブジェクトの生存期間とそこから取得できるイテレータの有効性が無関係であるような型は右辺値オブジェクトからイテレータを取得しても問題ないため、そのような型の右辺値もrangeコンセプトを満たすようにしたいという要望が上がりました。
当初のRangeライブラリでは、そのハンドリングのためにPoison Pillオーバーロード(begin(auto&&) = delete;)を活用しました。begin(A{})のように呼んだ時、Poison PillオーバーロードがADLによる候補よりも優先されるためconst参照を取るオーバーロードだけでは右辺値オブジェクトからイテレータを取得できなくしています。右辺値オブジェクトに対してbeginを有効にするには、begin(A&&)かbegin(A)のようなオーバーロードを追加することでそれを明示します。
当初のRangeライブラリでは右辺値rangeをこのように非常に高度なテクニックによってオプトインするようにしていましたがこれには問題が多く、これは後にenable_borrowed_range変数テンプレートによるより明確かつわかりやすいオプトイン方法に置き換えられ、現在に至っています。現在のstd::ranges::beginをはじめとするCPOでは、enable_borrowed_rangeな型Rに対して右辺値の入力を左辺値に実体化した上でディスパッチを行う(入力は常に左辺値として扱う)ことで規格の表現と実装を簡素化しています(規格ではこのことをreified objectという用語で表現しています)。
そのため、現在のPoison Pillオーバーロードには最初に紹介したstd名前空間の同名関数の毒殺以外の役割はもはやありません。また、その変更によって、std::ranges::beginの行うディスパッチでは右辺値を直接扱うことがなくなったためbegin(auto&&)という宣言ではPoison Pillオーバーロードが意図通りに機能しなくなり、現在のauto&とconst auto&の2つのオーバーロードに置き換えられました。
ここで、先ほどの例に戻ります。
struct A { friend auto begin(A const&) -> int const*; friend auto end(A const&) -> int const*; }; struct B { friend auto begin(B&) -> int*; friend auto end(B&) -> int*; };
Aのオブジェクトに対するstd::ranges::beginはADLによってAのHidden frineds begin()を見つけてくれるはずで、そこでは2つのPoison Pillオーバーロードを含めたオーバーロード解決が行われます。前述のように、オーバーロード解決は実際の引数型の値カテゴリに関わらずAの左辺値オブジェクト(A&)に対して行われ、それに対してはbegin(const A&)よりもbegin(auto&)の宣言の方が優先順位が高くなります。そしてそれはdeleteされているため、素の型Aに対するrange<A>はfalseになります。しかし、range<const A>だとオーバーロード解決はconst A&に対して行われるため、定義されているbegin()がPoison Pillオーバーロードよりも優先順位が高くなり、range<const A>はtrueとなります。
このようなコードは完全に合法かつ合理的であり、Poison Pillオーバーロードはそれを妨げています。Poison Pillオーバーロードを削除するとこの問題を解消できますが、Poison Pillオーバーロードにはまだ役割が残ってます。
しかしよく考えてみると、std::begin(r)はrがメンバbegin()を持っていたらそれを呼び出してくれるので、少なくとも標準ライブラリのものについてそれが呼び出されて困る理由はなく、borrowed_rangeであるか否かはすでに変数テンプレートによって弁別されるため、Poison Pillオーバーロードの有用な役割は実はもうありません。
実のところ、Poison Pillオーバーロードの残った1つの役割が有用なのはstd::ranges::swapのようなCPOにおいてです。std::swap()は無制約であり、これを呼び出すとswap操作を定義しない任意の型に対してswap(a, b)の呼び出しができてしまうためstd::swap()は使用したくないのです。このことは特に、std::swappableコンセプトがstd::ranges::swapを用いて定義されているため、そのコンセプトの有用性に直結します(std名前空間のものに対しては無条件でstd::swappableがtrueになりうる)。
ただこちらも、C++17以降はきちんと制約されていることが規定されているため、現在Poison Pillオーバーロードは実は必要ありません。
唯一標準ライブラリでPoison Pillオーバーロードが必要なのは、std::ranges::iter_swapだけです。これはstd::iter_swap()についてstd::swap()と同様の問題がありますが、C++20でもstd::iter_swap()は無制約であるため、ADLでiter_swap()を探しに行く際はPoison Pillオーバーロードが必要です。
これらのことから、この提案ではstd::ranges::iter_swap以外のすべてのCPOの定義から、Poison Pillオーバーロードを取り除くことを提案しています。ただし、CPOが自分自身を発見しないためとグローバル名前空間で不必要な探索を行わないようにするために、CPOが非メンバ関数を探索する際はADLによって探索される(非修飾名探索がおこなわれない)ことが確実になるように追記します。
この実装は単に、既存のPoison Pillオーバーロードが引数無しの宣言になるだけです。例えばstd::ranges::beginなら、void begin() = delete;のようになります。
namespace std::ranges { namespace impl { // 現在のPoison Pillオーバーロード //void begin(auto&) = delete; //void begin(const auto&) = delete; // この提案の実装例 void begin() = delete; struct begin_fn { auto operator()(auto&& range) const { return begin(range); } }; } }
そして、このことはすでにGCC(libstdc++)とMSVC(MSVC STL)で実装済みです。
P2603R0 member function pointer to function pointer
メンバ関数ポインタから、基底クラスの関数を明示的に呼び出せるようにする提案。
C++はコンパイル時に確定する場合にのみ、派生クラスから基底クラスの関数を呼び出すことができます。一方、実行時に呼び出し先が確定しうる場合には常に派生クラスのメンバ関数が呼び出されます。どういうことでしょうか?
#include <iostream> class Base { public: virtual void some_virtual_function() { std::cout << "call Base::some_virtual_function()\n"; } virtual void some_virtual_function() const { std::cout << "call Base::some_virtual_function() const\n"; } }; class Derived : public Base { public: void some_virtual_function() override { std::cout << "call Derived::some_virtual_function()\n"; } void some_virtual_function() const override { std::cout << "call Derived::some_virtual_function() const\n"; } }; int main() { Derived derived; Derived* pderived = &derived; Derived& rderived = derived; // 派生クラスメンバ関数の呼び出し derived.some_virtual_function(); pderived->some_virtual_function(); rderived.some_virtual_function(); std::cout << "\n"; // 基底クラスメンバ関数の呼び出し derived.Base::some_virtual_function(); pderived->Base::some_virtual_function(); rderived.Base::some_virtual_function(); std::cout << "\n"; // メンバ関数ポインタの取得 void (Base::*bmfp)() = &Base::some_virtual_function; void (Derived::*dmfp)() = &Derived::some_virtual_function; void (Derived::*dmfpc)() const = static_cast<void (Derived::*)() const>(&Derived::some_virtual_function); // メンバ関数ポインタからの呼び出し (derived.*bmfp)(); (derived.*dmfp)(); (derived.*dmfpc)(); }
実行例([Wandbox]三へ( へ՞ਊ ՞)へ ハッハッ)
call Derived::some_virtual_function() call Derived::some_virtual_function() call Derived::some_virtual_function() call Base::some_virtual_function() call Base::some_virtual_function() call Base::some_virtual_function() call Derived::some_virtual_function() call Derived::some_virtual_function() call Derived::some_virtual_function() const
(メンバ)関数ポインタでは実行時に呼び出し先が確定するため、仮想関数のメンバ関数ポインタ呼び出しは常に使用されたオブジェクトの際派生クラスのものが呼ばれます。特に問題となるのはこの部分です
int main() { Derived derived; // 基底クラスのメンバ関数ポインタを取得 void (Base::*bmfp)() = &Base::some_virtual_function; // 派生クラスのオブジェクトで基底クラスのメンバポインタから呼び出し (derived.*bmfp)(); // 派生クラスの関数が呼ばれる }
これは基底クラスのポインタから呼び出しても同様になります。
void call(Base* base) { void (Base::*bmfp)() = &Base::some_virtual_function; (base->*bmfp)(); } int main() { Derived derived; call(&derived); // 派生クラスの関数が呼ばれる }
これは仮想関数の性質を考えると当然の振る舞いであり、この振る舞いそのものに問題があるわけではありません。問題なのは、メンバ関数ポインタを介して派生クラスのオブジェクトから基底クラスのメンバ関数を明示的に呼び出すことができないという点で、これはfunction_refやnontypeで問題となる可能性があります。
auto make_fr(Base* base) { // 基底クラスの関数を呼ぶ意図のfunction_refを作成 // この関数単体で見ると引数型も含めて問題ないように見える function_ref<void()> fr = {nontype<&Base::some_virtual_function>, base}; return fr; } int main() { Derived derived; // 派生クラスのオブジェクトを渡す auto fr = make_fr(&derived); fr(); // 派生クラスの関数が呼ばれる }
この提案はこの事を解決すべく、メンバ関数ポインタと派生クラスオブジェクトから明示的に基底クラスのメンバ関数を呼び出せるようにしようとするものです。
提案されている解決策は、member_function_pointer_to_free_function_pointer()の様な関数を用意することで、メンバ関数ポインタを第一引数を明示した関数ポインタへ変換できるようにすることです。
int main() { Derived derived; void (*bfp)(Base&) = member_function_pointer_to_free_function_pointer(&Base::some_virtual_function); void (*dfp)(Derived&) = member_function_pointer_to_free_function_pointer(&Derived::some_virtual_function); void (*dfpc)(const Derived&) = member_function_pointer_to_free_function_pointer(static_cast<void (Derived::*)() const>(&Derived::some_virtual_function)); void (*ddtfp)(Derived) = member_function_pointer_to_free_function_pointer(&Derived::some_deducing_this_member_function); }
これによって、既存の振る舞いに一切影響を与えることなく、上記の問題を解決できます。
member_function_pointer_to_free_function_pointer()はconsteval関数のようなもので、コンパイル時にメンバ関数ポインタからそのメンバ関数を指すフリー関数ポインタそのものか、もしくはそのクラス型の参照を第一引数に取るようにした何か(サンク)を取得します。
この提案は次のようなメリットがあります
- 派生クラスのオブジェクトから、基底クラスのメンバ関数ポインタを用いて基底クラスの関数を呼び出す、という選択肢を追加する
- メンバ関数がDeducing thisを用いて記述されているかに関係なくメンバ関数ポインタを扱える
- 初期化に使用するメンバ関数ポインタによって呼び出されるメンバ関数を確実に選択でき、C++の他の部分や手法と一貫する
関数名とかその振る舞いの詳細やライブラリ関数として追加するのかなどの部分はまだ確定しておらず、今後詰めていく予定のようです。
なおこの機能はすでに、GCCで独自拡張として実装されているようです。
P2604R0 MDSPAN: rename pointer and contiguous
mdspanの一部のメンバの名前を変更する提案。
提案しているのは以下のものです
mdspan::pointermdspan::data()mdspan::contiguous
mdspanのpointer型はそのアクセサポリシークラスに別に求めたインデックスと一緒に渡す際の、その引数型でしかありません(要素型のポインタ型を表すものではない)。従って、その要件は緩く、標準コンテナにおけるpointer型とは役割が大きく異なっています。
そのため、その違いを明確にするためにmdspan::pointerをdata_handle_typeにリネームすることを提案しています。また、mdspan::data()も同様にmdspanの参照する領域へのポインタではあるものの、その要素型やレイアウトに関連付けられたものではないため、data_handle()に変更することを提案しています。
mdspan::contiguousとは、与えられたレイアウトマッピングの範囲[0, map.required_span_size())の全ての値に対して正しいインデックスが得られることを表すメンバ型です。例えばレイアウトマッピングの範囲が[0, 10)であるとき、0~9までのインデックス値をmdspanに与えるとその参照領域のどこかを指す(不正にならない)インデックス値へ変換され、要素を引き当てることができることを表しています。
ただし、レイアウトマッピングクラスはカスタム可能であり、それによっては必ずしも線形な順序でインデックスが変換されない可能性があります。例えば、{0, 1, 2, 3, 4}のインデックスは{4, 1, 3, 0, 2}にマップすることができます。これはmdspan的にはまだcontiguousですが、ユーザーの期待には沿っていません。
そのため、mdspan::contiguousをexhaustiveに変更することを提案しています(変換後インデックスは隣接していないかもしれないけど、入力に対しては抜けが無い)。
P2605R0 SG16: Unicode meeting summaries 2022-01-12 through 2022-06-08
P2607R0 Let alignas specify minimum alignment
alignasでデフォルトのアライメントよりも弱いアライメント指定がされた場合にエラーとせず無視するようにする提案。
現在のalignasでは、その型のデフォルトのアライメント指定よりも弱いアライメントを指定するとコンパイルエラーとなります。
alignas(1) int i; // ng(おそらくデフォルトのアライメントは4バイト struct alignas(1) S { int i; }; // ng(おそらくデフォルトのアライメントは4バイト
これによって、ある型に指定したい最小のアライメント指定を移植可能な方法で指定することが困難になっています。そのような場合、nを指定したい最小のアライメント、dをデフォルトのアライメントとすると、指定したいアライメントはmax(n, d)の値です。例えば、最小8バイトアライメントを指定したい場合に実装が16バイトでアラインしていたとしても、それは意図通りなので問題ありません。
型のアライメント値(d)はalignofによって取得することができますが、そのためにはまず型を定義しなければなりません。しかし、型の定義後にalignasでアライメントを変更できないため、現在の仕様では最小アライメントの指定をalignas(max(n, d))のような形で行うことができません。
この提案はこれをできるようにするために、alignasでデフォルトのアライメントよりも弱いアライメント指定がされた場合はalignasが効果を持たないようにしようとするものです。
alignas(1) int i; // ok、alignasは無視されデフォルトのアライメントが使用される struct alignas(1) S { int i; }; // ng、alignasは無視されデフォルトのアライメントが使用される
このことはすでにGCCが実装しており、GCCはまさにこの振る舞いをします。
P2608R0 Allow multiple init-statements
通常のfor文で、変数初期化を複数書けるようにする提案。
現在の非range-based forでは、変数初期化ステートメントの部分で異なる型の複数の初期化を行うことはできません。
int main() { // これはできる for (int i = 0, j = 0; i < 10; ++i) { ... } // これはできない for (int i = 0, double v = 0.0; i < 10; ++i) { ... } }
この場合に、複数の初期化をかけるようにしたとしても構文上の曖昧さは生じないため、これを許可しようとする提案です。
なお、これと同じ構文は現在if, switchとrange-based forでも使用されており、この提案の内容はそちらにも及んでいます。
P2609R0 Relaxing Ranges Just A Smidge
射影(プロジェクション)を取るアルゴリズムについて、その制約を緩和する提案。
射影を取るアルゴリズムでは、次のようなコードが動くように制約される必要があります
iter_value_t<It> x = *it; f(proj(x));
しかし実際には、次のようなコードが動くような制約になっています
iter_value_t<projected<I,Proj>> u = proj(*it); f(u);
これは1つ目のコードを有効化するよりも強い制約であり、射影の結果に対してコピー可能であることを追加で求めてしまっています。
これは、このような制約を間接呼び出しに関するコンセプトと射影の合成によって制約を行なっているために起きています。例えば、std::ranges::for_eachの制約にあるstd::indirect_unary_invocable<std::projected<I,P>>がそれにあたります。
std::projected<I,P>はイテレータ型Iの間接参照結果(*i)を射影Pに通した結果を(イテレータlikeな型として)返します。その型をPrjとして、indirect_unary_invocable<Pred, Prj>はPrjの間接参照結果(*prj)を述語(Pred)に渡して呼び出し可能かがチェックされます。
アルゴリズム内で述語は、入力イテレータの要素への参照を渡して呼ばれることもあれば、それをコピーした値を渡して呼ばれることもあり、std::ranges::unique_copyのように両方を行うものもあります。そのため、indirectly_unary_invocable(などのコンセプト)では、その両方の呼び出し及び共通参照(common reference)に束縛してから呼び出しが可能であることをチェックする制約式が含まれています。
template< class F, class I > concept indirectly_unary_invocable = indirectly_readable<I> && copy_constructible<F> && invocable<F&, iter_value_t<I>&> && // コピーした値への参照を渡して呼び出し可能 invocable<F&, iter_reference_t<I>> && // *iを直で渡して呼び出し可能 invocable<F&, iter_common_reference_t<I>> && // common referenceに束縛した値を渡して呼び出し可能 common_reference_with< invoke_result_t<F&, iter_value_t<I>&>, invoke_result_t<F&, iter_reference_t<I>>>;
射影は関数アダプタであり、アルゴリズムの主たる振る舞いに影響を与えるものではなく、ユーザーが述語と射影を事前に関数合成したものを述語として渡したとしても分けて渡された時と同じ振る舞いをするはずです。実際そのように実装されているのですが、現在のイテレータと射影及び述語に課せられた制約はそのことを正しく表現できていません。このindirectly_unary_invocableの中の、iter_value_tによる呼び出しに関する制約式が問題を起こしています。
// 問題のある制約 invocable<F&, iter_value_t<projected<I, Proj>>&> // projectedとiter_value_tを展開 invocable<F&, remove_cvref_t<invoke_result_t<Proj&, iter_reference_t<I>>&>
この制約はf(proj(*it))が有効であることを制約してはいますが、イテレータの要素をコピーしてから渡す場合は次のような違いがあります
// 有効にしたいコード iter_value_t<It> x = *it; f(proj(x)); // 実際に有効になっているコード iter_value_t<projected<I,Proj>> u = proj(*it); f(u);
invocable<F&, iter_value_t<projected<I, Proj>>&>をよく見てみると、これは次のような制約になっています
using T = invoke_result_t<Proj&, iter_reference_t<I>; // decltype(proj(*it)) (射影結果の型 using U = remove_cvref_t<T>&; // auto u = proj(*it) に対する decltype((u)) (射影結果をコピーした左辺値 invocable<F&, U>; // requires(F& f, U u) { f(u) } (射影結果をdecay-copyした左辺値で呼び出し可能かを制約している
すなわち、最初に(射影する前に)イテレータの要素をコピーしてからそれを射影と述語にかけたいはずなのに、std::indirect_unary_invocable<std::projected<I,P>>という制約には射影後の値をコピーしてそれを述語にかけるコードを許可する制約が含まれています。イテレータの要素のコピーの必要性はアルゴリズムによるので(今はそのようなアルゴリズムにおける制約を見ているため)イテレータ要素型のコピー可能性はここでの前提であり、そのようなアルゴリズムにおいてこの制約は射影結果型に対してもコピー可能であることを追加で求めている過剰な制約となっています。
このことによって影響を受けるユーザーコードはほぼ無いと思われますが、射影の結果がムーブオンリー型を返す場合は問題になる可能性があります
std::ranges::for_each( std::views::iota(0, 5), // 述語、unique_ptrを値で受け取る // 左辺値(std::unique_ptr<int>&)では呼べない [](std::unique_ptr<int> v){ std::cout << *v << std::endl; }, // 射影、unique_ptrを返す [](int v){ return std::make_unique<int>(v); });
この提案は、これらの制約について本来の意図と一致するように間接呼び出し系のコンセプトを修正(緩和)しようとするものです。
まず、std::projectedの結果と素のイテレータとでその値型の取得方法を切り替える型特性std::indirect_value_tを導入します
template<indirectly_readable I> using indirect_value_t = ...;
indirect_value_t<T>は、Tの名前がprojected<I, Proj>である時はinvoke_result_t<Proj&, iter_value_t<I> &>となり、それ以外の場合はiter_value_t<T>&となります。
// 射影結果型(projected)に対してはこうなる template<indirectly_readable I> using indirect_value_t = invoke_result_t<Proj&, iter_value_t<I>&>; // それ以外のイテレータ型に対してはこうなる template<indirectly_readable I> using indirect_value_t = iter_value_t<T>&;
これを用いて間接参照を介した呼び出しを制約するコンセプトを修正します。例えばstd::indirect_unary_invocableだと次のようになります
template< class F, class I > concept indirectly_unary_invocable = indirectly_readable<I> && copy_constructible<F> && invocable<F&, indirect_value_t<I>&> && // 👈 invocable<F&, iter_reference_t<I>> && invocable<F&, iter_common_reference_t<I>> && common_reference_with< invoke_result_t<F&, indirect_value_t<I>&>, // 👈 invoke_result_t<F&, iter_reference_t<I>>>;
これによって変わったことは
invocable<F&, indirect_value_t<I>&> // indirect_value_tを展開 invocable<F&, invoke_result_t<Proj&, iter_value_t<I>&>>
これをよく見てみると
using T = iter_value_t<I>&; // auto c = *it; に対する decltype((c)) (イテレータの要素をコピーした左辺値 using U = invoke_result_t<Proj&, U>; // decltype(proj(c)) (コピーした要素の左辺値による射影結果の型 invocable<F&, U>; // requires(F& f, U u) { f(u) } (射影結果を直接渡して呼び出し可能かを制約している
つまりこの変更によって、auto c = *it;のようにコピーしておいた要素によってf(proj(c))のような呼び出しが可能であることを制約するようになっており、これは元の(現在の)制約を緩和するとともに本来の意図を正しく表現するものです。
このことは既にGCC(libstdc++)及びRange-v3にて実装されており、特に問題が起きていないことを確認しているようです。
この部分の9割は以下の方のご協力によって成り立っています
P2613R0 Add the missing empty to mdspan
std::mdspanにempty()メンバ関数を追加する提案。
現在の提案中のstd::mdspanは.size()はあっても.empty()メンバ関数を持っていません。一方、標準ライブラリの非固定サイズコンテナやstd::spanは両方を備えています。このことは、それらとstd::mdspanとのインターフェースの一貫性を損ねているため、std::mdspanにempty()メンバ関数を追加しようとする提案です。
また、std::mdspanに.empty()はsize() = 0よりも最適化される可能性があるようです。例えば、.size()はmdspanのその時点の全ての次元の要素数(エクステント)を乗算した値を返しますが、.empty()は全ての次元の要素数が0より大きいかどうかをチェックするだけで、これは乗算よりも高速である可能性があります。
この提案はすでにLEWGのレビューをパスして、std::mdspanに直接適用するためのLEWG全体投票待ちをしています。